



视频超分学习(个人收集自用)
视频超分指的是利用视频图像的前后多帧图像信息实现图像超分效果提升。
整体的方案可以分为几个模块:多帧图像信息的对齐模块,多帧图像信息的融合模块,以及图像重建超分模块
通过阅读三篇经典论文快速入门
1. VSRnet
paper: https://ieeexplore.ieee.org/document/7444187
第一篇借鉴了SRCNN的视频超分网络,主要是探索了多种融合和对齐方法的效果。
1.1 多帧对齐模块
采用了Druleas的光流估计方法进行对齐。
光流简单来说就是某一时刻物体移动的速度和方向,我们可以利用光流提取当前帧与相邻帧画面的相对位置关系,进而根据该信息执行帧之间的变形(Warping)操作,实现一个帧向另外一个帧对齐。
1.2 多帧融合模块
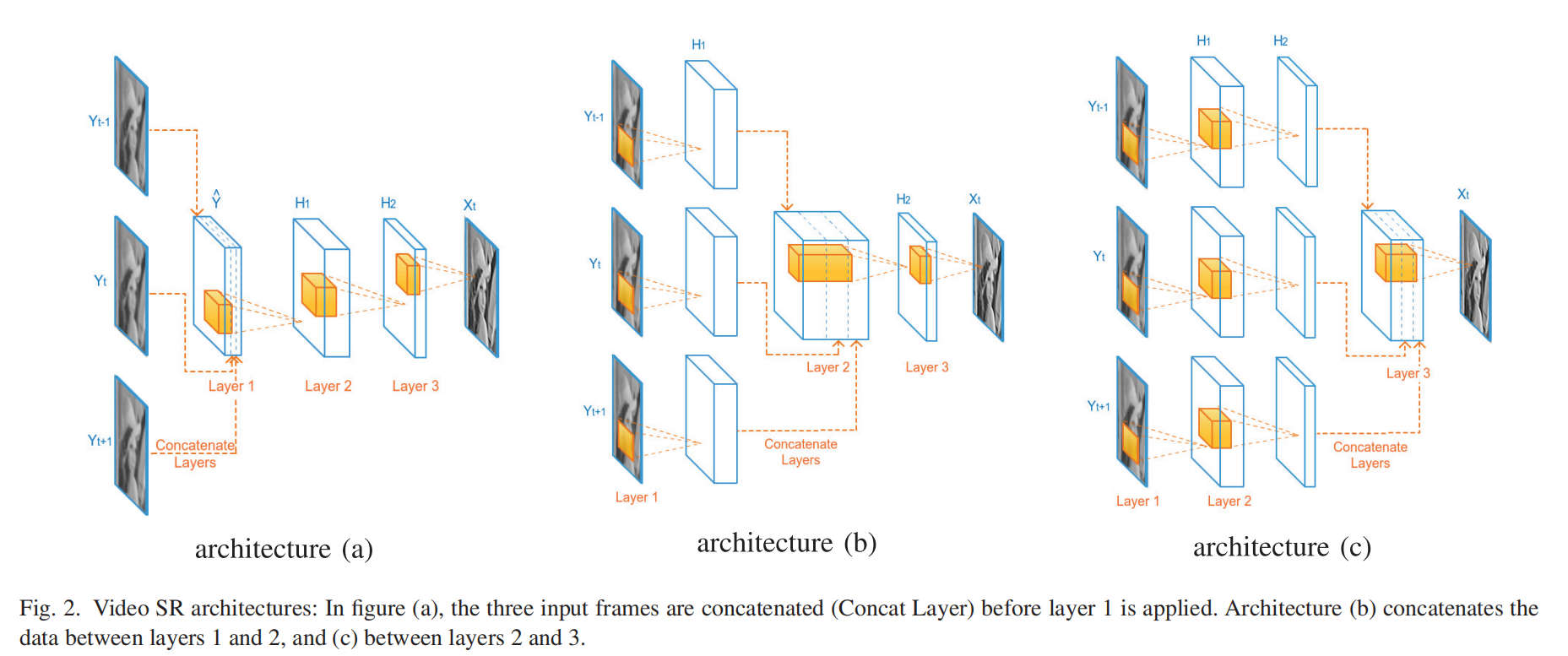
1.3 提点的trick
利用非视频图像进行预训练提升性能(性能提升0.6dB左右),利用相同的卷积层提取前后帧的图像特征(基于运动区域是相同的假设,利用相同的卷积层能提取到不同帧相同区域的非运动区域特征,在多帧合成任务中会使用这样的网络结构设计,性能提升0.2dB左右)
1.4 不足
因为是2016年的文章,所用的网络结构比较简单(只有三层卷积网络),数据集比较小(只用了53段视频数据进行训练),使用的是传统的光流算法(精度和鲁棒性不够),后续文章主要针对这几点进行优化。
2. EDVR
paper: https://openaccess.thecvf.com/content_CVPRW_2019/papers/NTIRE/Wang_EDVR_Video_Restoration_With_Enhanced_Deformable_Convolutional_Networks_CVPRW_2019_paper.pdf
参考博客:
https://blog.youkuaiyun.com/MR_kdcon/article/details/124170948
主要针对前面方法中的对齐和融合模块进行改良,其中对齐采用了金字塔级联可变形卷积层的对齐模块,融合模块采用了时空注意力机制,另外还使用了两个EDVR串联的方式提升效果。
2.1 网络整体结构
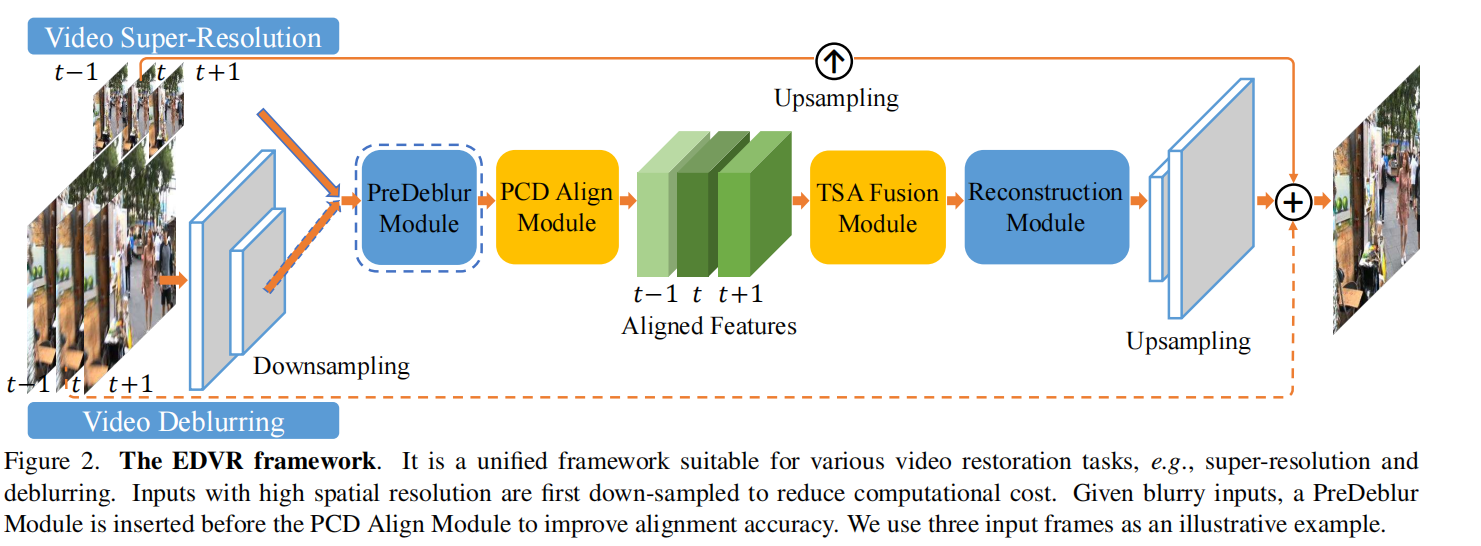
输入的多帧图像首先经过deblur模块后,再经过对齐模块进行对齐,然后经过融合模块,最后经过重建模块得到输出的结果。
2.2 金字塔级联可变形卷积层(Pyramid, Cascading and Deformable, PCD)
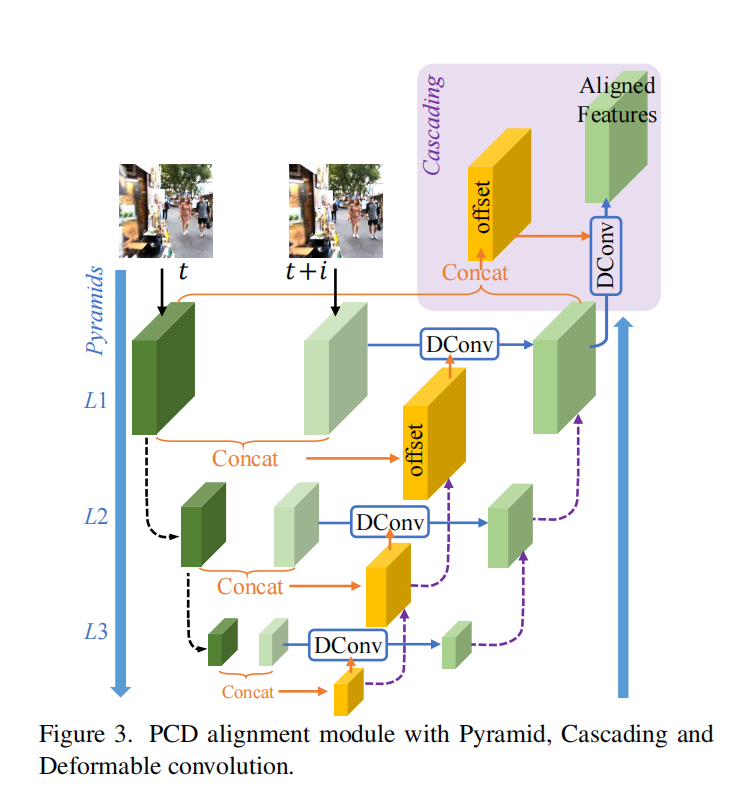
输入图像经过两次下采样,得到三个不同尺度的特征图(L1-L3),通过相同层级特征图concat后(对于L1和L2层还会把低一级的offset参数concat上),经过卷积层后得到可变形卷积层的offset参数,最后把特征图通过可变形卷积层得到对齐的输出。
2.3 时空注意力机制(Temporal and Spatial Attention, TSA)
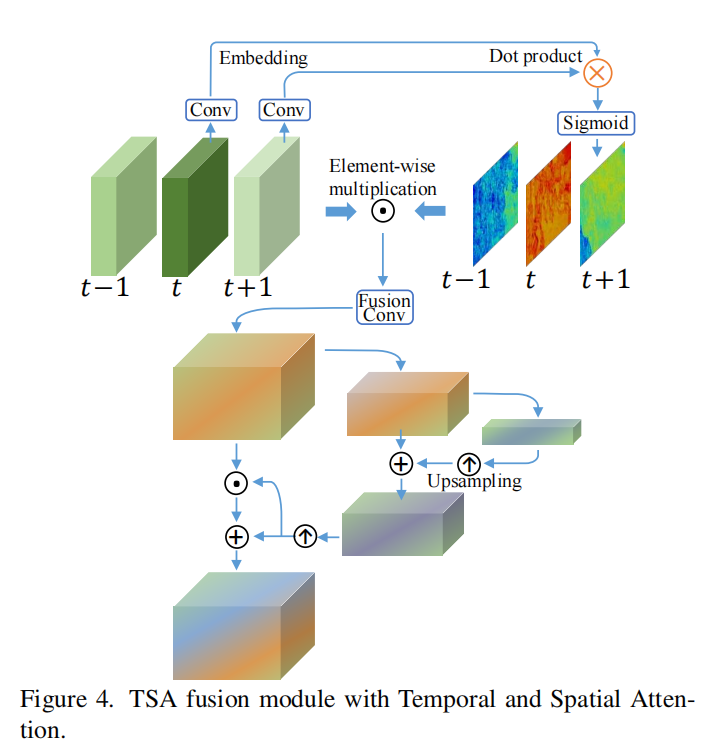
对齐后的输入先通过卷积层计算对应的特征图,然后在时间通道上进行交叉注意力计算,最后通过Sigmoid函数得到0-1之间的权重map,进行点乘得到在时间上融合的结果。
ht+1,t=sigmoid(Conv(Ft+1)TConv(Ft))h_{t+1, t} = sigmoid(Conv(F_{t+1})^TConv(F_t))ht+1,t=sigmoid(Conv(Ft+1)TConv(Ft))
F~t+1=Ft+1⊙ht+1,t\tilde{F}_{t+1} = F_{t+1}\odot h_{t+1, t}F~t+1=Ft+1⊙ht+1,t
FFusion=Conv([F~t−N,...,F~t,...,F~t+N])F_{Fusion} = Conv([\tilde{F}_{t-N},..., \tilde{F}_{t},..., \tilde{F}_{t+N}])FFusion=Conv([F~t−N,...,F~t,...,F~t+N])
完成时间通道的注意力融合后进行空间注意力融合,主要采用了两次卷积下采样和点乘完成空间注意力融合
F1=Conv↓(FFusion),F2=Conv↓(F1)F_1 = Conv_\downarrow(F_{Fusion}), F_2 = Conv_\downarrow(F_1)F1=Conv↓(FFusion),F2=Conv↓(F1)
F3=F1+F2↑F_3 = F_1 + F_2 ^\uparrowF3=F1+F2↑
Fout=F3↑+F3↑⊙FFusionF_{out} = F_3^\uparrow + F_3^\uparrow \odot F_{Fusion}Fout=F3↑+F3↑⊙FFusion
2.4 两阶段复原
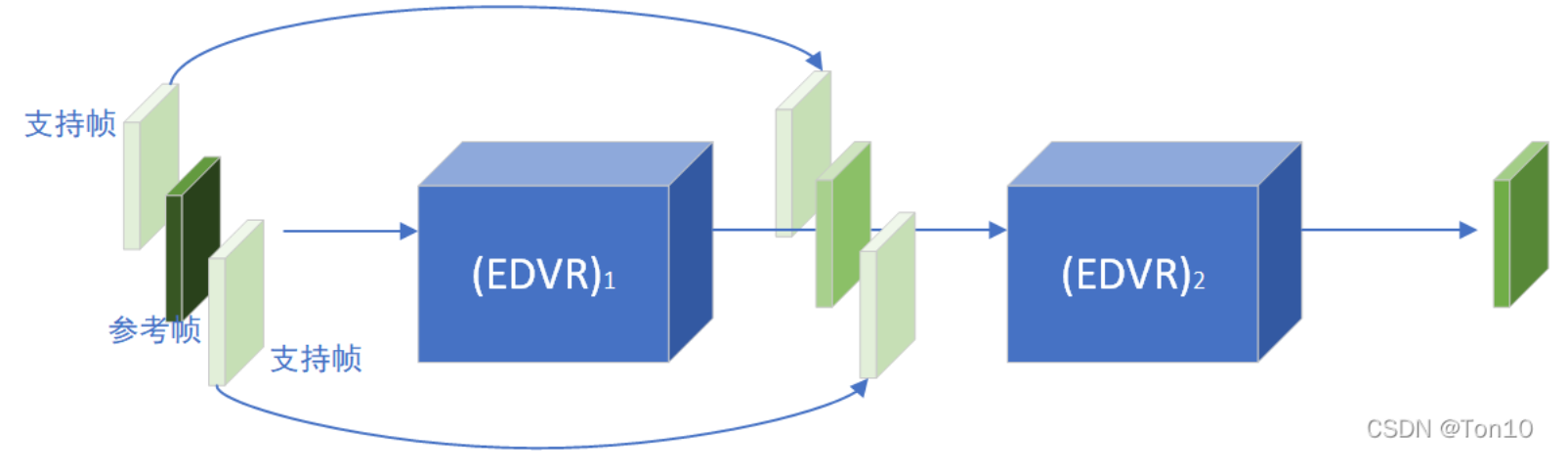
作用:
- 去除了原来1个EDVR无法完全去除的模糊问题。
- 减缓了1个EDVR输出的帧间不连续情况。
2.5 总结
- EDVR对经典VSR结构的对齐网络和融合网络都进行了改进,分别使用了PCD和TSA模块。PCD的存在使得EDVR可以应对大而复杂的运动;而TSA的存在使得EDVR更加注重对重建效果好的特征信息,对于存在模糊或对齐不佳的特征进行忽略。此外EDVR使用two-stage的策略可以较大提升表现力。
- EDVR是一个可以处理超分和去模糊任务的多功能VSR网络,并取得了2019超分挑战赛的冠军以及在性能上取得了SOTA!
- 这些方法还是基于多帧的方法,没有从整个视频流的角度去考虑
3. BasicVSR
博客可参考:https://blog.youkuaiyun.com/MR_kdcon/article/details/124463280
paper: https://arxiv.org/abs/2012.02181
3.1 文章动机
文章认为视频和多帧图像超分有不同的地方,视频的每一帧都与整体视频相关。在视频超分中有四个模块:传播(Propagation),对齐(Alignment),融合(Aggregation)和上采样(Upsampling)四个模块。BasicVSR主要是针对其中的传播和对齐模块进行了改良。在传播中使用了双向循环传播机制(Bidirectional),对齐主要是采用Spynet的光流法进行对齐。
3.2 整体框架
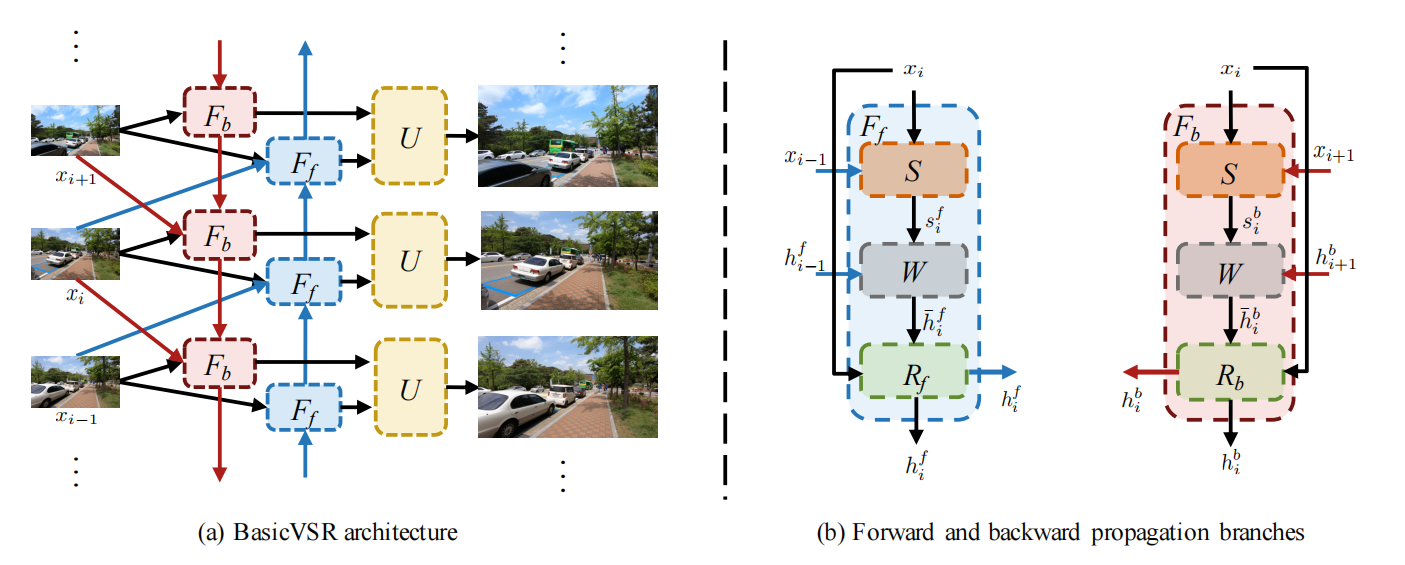
左侧是视频输入图像到输出图像的整体数据流动方向,右侧是其中的反向传播模块FbF_bFb和正向传播模块FfF_fFf的示意图。通过传播模块完成相应的特征对齐后,正向和反向的特征信息被输入到上采样模块中进行图像的超分,完成最终的图像输出。
hib=Fb(xi,xi+1,hi+1b)h_i^b = F_b(x_i, x_{i+1}, h_{i+1}^b)hib=Fb(xi,xi+1,hi+1b)
hif=Ff(xi,xi−1,hi−1f)h_i^f = F_f(x_i, x_{i-1}, h_{i-1}^f)hif=Ff(xi,xi−1,hi−1f)
hibh_i^bhib是FbF_bFb模块的输出,b表示back propagation,i表示当前是第i帧图像。由上面的图示可以看到,FbF_bFb模块的输入是当前视频帧xix_ixi,未来帧xi+1x_{i+1}xi+1和未来帧的FbF_bFb模块输出。FfF_fFf也类似。
对于其中的FbF_bFb模块,由光流估计模块S,配准模块W和残差模块R构成。光流估计使用的是SpyNet,在这个模块中通过输入xix_ixi和xi+1x_{i+1}xi+1计算出从第i+1帧到第i帧的光流参数sibs_i^bsib。
sib=S(xi,xi+1)s_i^{b} = S(x_i, x_{i+1})sib=S(xi,xi+1)
然后再配准模块W中利用估算的光流参数sibs_i^bsib将未来帧的FbF_bFb模块输出hi+1bh_{i+1}^bhi+1b配准到第i帧,得到h~b\tilde{h}^bh~b。
h~b=W(hi+1b,sib)\tilde{h}^b = W(h_{i+1}^b, s_i^b)h~b=W(hi+1b,sib)
考虑到上面的对齐存在一定的误差,还利用了一些基于卷积层进行调整。
hib=Rb(xi,h~b)h_i^b = R_b(x_i, \tilde{h}^b)hib=Rb(xi,h~b)
FfF_fFf模块也类似,最后是上采样模块U,特征的融合是直接concatenate,上采样是利用了pixel-shuffle
yi=U(hif,hib)y_i = U(h_i^f, h_i^b)yi=U(hif,hib)
3.3 IconVSR改良
基于上面的basicVSR框架,文章进一步优化,优化了FFF内部模块解决传播过程的误差累计问题,并在FbF_bFb和FfF_fFf模块之间采用了耦合的传播方式,提升特征对齐质量。修改的部分见下图的紫色部分。
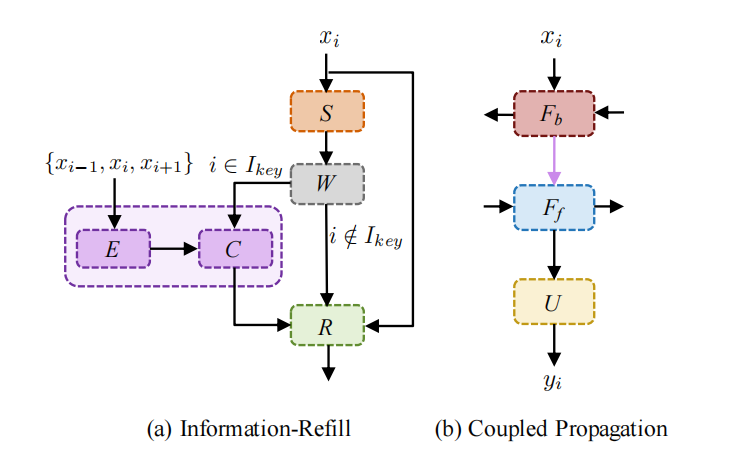
Information-Refill
主要是引入了额外的特征提取模块,直接提取关键帧以及前后帧输入的信息,通过卷积层融合配准后的特征。为了降低计算量,不是对全部帧都额外增加这些计算,只在特定的帧上进行处理。在整个视频图像中选择了一些参考帧的集合,当当前处理的图像是参考帧,则使用这些额外的网络层,否则保持basicvsr的结构。
Coupled Progagation
原来的FbF_bFb和FfF_fFf是完全独立处理的,现在进行改良把FbF_bFb的输出也输入到FfF_fFf模块中,提高对齐质量。
3.4 总结
- 对视频超分的对齐和传播模块进行了改良,引入光流法和额外卷积层的对齐模块在特征空间进行对齐,提升效果和降低运行计算耗时。引入了双向的传播,利用整个视频的信息提升重建效果。
- 基于前面的框架,进一步改良对齐模块和传播模块,获得了效果的提升。
4. 补充——光流法对齐
4.1 传统算法(Lucas-Kanade经典算法)
假设1:亮度恒定假设
I(x,y,t)=I(x+dx,y+dy,t+dt)I(x, y, t) = I(x+dx, y+dy, t+dt)I(x,y,t)=I(x+dx,y+dy,t+dt)
假设2:小运动假设,可以使用一阶泰勒展开表示
I(x+dx,y+dy,t+dt)≈I(x,y,t)+∂I∂xdx+∂I∂ydy+∂I∂tdtI(x+dx, y+dy, t+dt) \approx I(x,y,t) + \frac{\partial I}{\partial x} dx + \frac{\partial I}{\partial y} dy + \frac{\partial I}{\partial t} dtI(x+dx,y+dy,t+dt)≈I(x,y,t)+∂x∂Idx+∂y∂Idy+∂t∂Idt
联立两个等式可得:
Ixu+Iyv=−ItI_x u + I_y v = -I_tIxu+Iyv=−It
其中,Ix,Iy,ItI_x, I_y, I_tIx,Iy,It分别时图像的x方向,y方向以及时间上的梯度变化,为已知变量。u=dxdt,v=dydtu=\frac{dx}{dt}, v=\frac{dy}{dt}u=dtdx,v=dtdy是需要求解的两个未知变量,只有一个方程无法求解,因此需要新的假设。
假设3:空间一致性假设,假设图像像素的邻域内u,vu, vu,v变量是相等的
[Ix1Iy1......IxnIyn][uv]=[It1...Itn]\begin{equation}
\begin{bmatrix}
I_x^1 & I_y^1 \\
. & .\\
. & .\\
. & .\\
I_x^n & I_y^n
\end{bmatrix}
\begin{bmatrix}
u \\
v
\end{bmatrix}
=
\begin{bmatrix}
I_t^1 \\
.\\
.\\
.\\
I_t^n
\end{bmatrix}
\end{equation}
Ix1...IxnIy1...Iyn[uv]=It1...Itn
因此对齐问题转换为求上述的最优化问题,通过求解min∣Ab−d∣min|Ab-d|min∣Ab−d∣,即可得到d=[uv]d=\begin{bmatrix} u\\v \end{bmatrix}d=[uv],进而可以利用这个光流信息计算出每个像素新的坐标位置,实现图像的对齐。
4.2 深度学习算法(SpyNet)
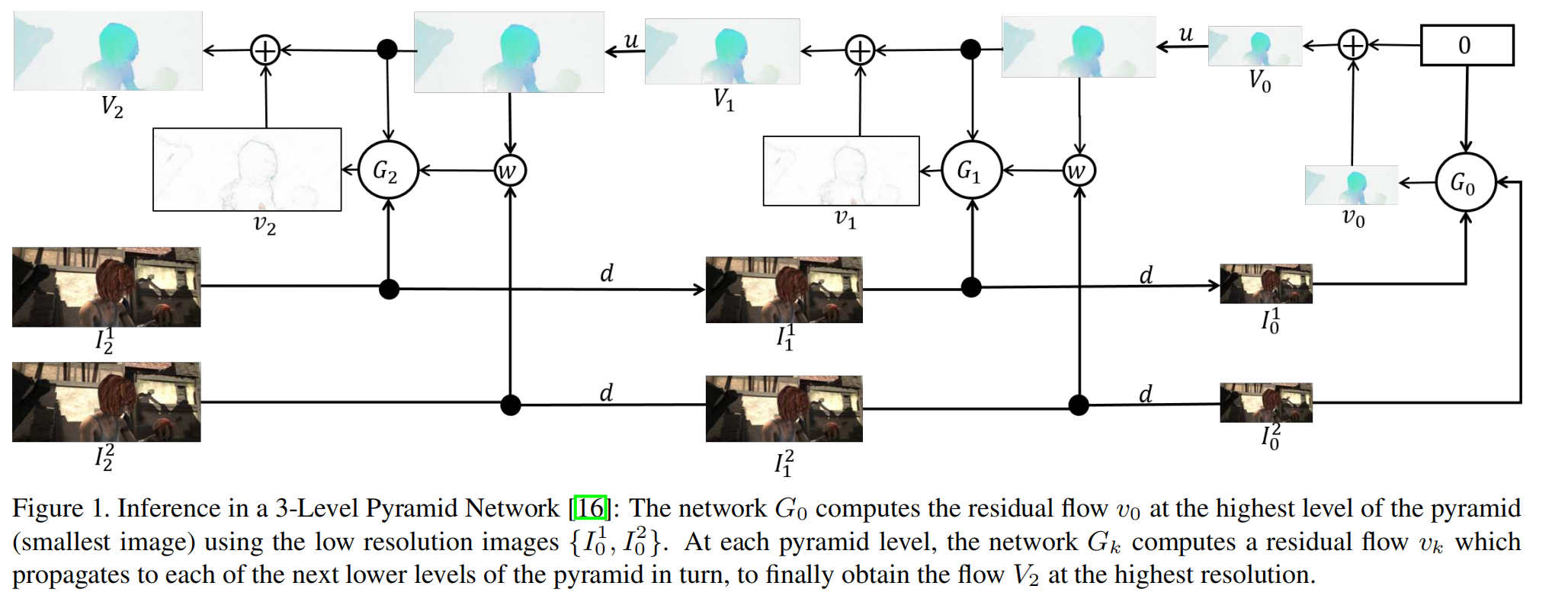
网络框架
SpyNet采用的是一个空间金字塔结构,在金字塔的每层学习残差光流。对于一个K层的SpyNet,输入的图像会被下采样K-1次,每层都是一个小的光流预测网络。
一层的光流网络由以下几部分组成:III是分辨率m×nm \times nm×n的图像,ddd是下采样操作,uuu是上采样操作,GGG是卷积神经网络层,www是一个扭曲算子,基于光流场VVV对图像III采用双三次插帧进行变形(光流法计算出的新坐标可能是非整数坐标,需通过双线性插值计算新的像素值)。


















 4514
4514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









