







欢迎关注更多精彩
关注我,学习常用算法与数据结构,一题多解,降维打击。
本期话题:最小二乘3D圆拟合
相关背景资料
点击前往
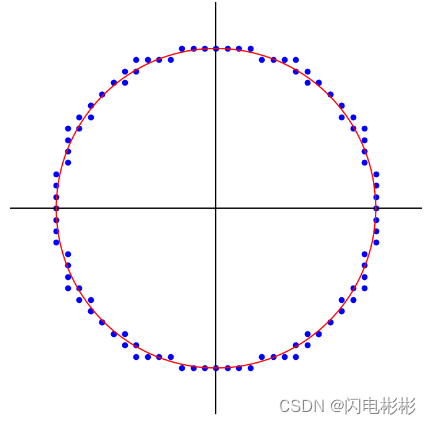
3D圆拟合输入和输出要求
输入
- 8到50个点,全部采样自3D圆上。
- 每个点3个坐标,坐标精确到小数点后面20位。
- 坐标单位是mm, 范围[-500mm, 500mm]。
tips
输入虽然是严格来自3D圆,但是由于浮点表示,记录的值和真实值始终是有微小的误差,点云到拟合圆的距离不可能完全为0。
输出
- 1点X0表示 圆心,用三个坐标表示。
- 法向A代表圆所在平面法向。
- 圆半径r。
精度要求
- X0点到标准圆心距离不能超过0.0001mm。
- 法向A与圆法向夹角不能超过0.0000001rad。
- r与标准半径的差不能超过0.0001mm。
3D圆优化标函数
根据论文,圆拟合转化成数学表示如下:
圆参数化表示
- 圆心为1点X0 = (x0, y0, z0)。
- 法向A=(a,b,c)。
- 半径r。
圆方程 ( x − x 0 ) 2 + ( y − y 0 ) 2 + ( z − z 0 ) 2 = r 2 a ( x − x 0 ) + b ( y − y 0 ) + c ( z − z 0 ) = 0 圆方程\begin {array}{c}(x-x_0)^2+(y-y_0)^2+(z-z_0)^2=r^2 \\ a(x-x_0)+b(y-y_0)+c(z-z_0)=0 \end {array} 圆方程(x−x0)2+(y−y0)2+(z−z0)2=r2a(x−x0)+b(y−y0)+c(z−z0)=0
能量方程
第i个点 pi(xi, yi, zi)。
定义距离如图
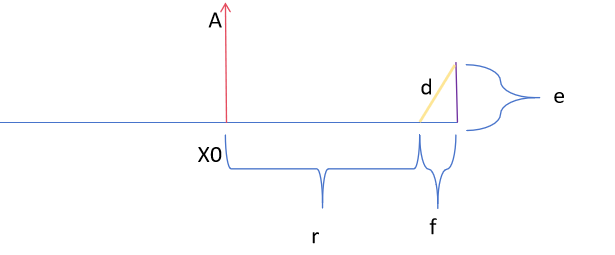
根据勾股定理,黄色线为距离。
d i = e i 2 + f i 2 d_i = \sqrt{e_i^2+f_i^2} di=ei2+fi2
根据定义得到能量方程
E = ∑ 1 n d i 2 = ∑ 1 n ( e i 2 + f i 2 ) E=\displaystyle \sum _1^n {d_i^2}=\displaystyle \sum _1^n {(e_i^2+f_i^2)} E=1∑ndi2=1∑n(ei2+fi2)
e i = a ( x i − x 0 ) + b ( y i − y 0 ) + c ( z i − z 0 ) f i = u i 2 + v i 2 + w i 2 − r \begin {array}{l} e_i =a(x_i-x_0)+b(y_i-y_0)+c(z_i-z_0)\\ f_i=\sqrt{u_i^2+v_i^2+w_i^2}-r\end {array} ei=a(xi−x0)+b(yi−y0)+c(zi−z0)fi=ui2+vi2+wi2−r
u i = c ( y i − y 0 ) − b ( z i − z 0 ) v i = a ( z i − z 0 ) − c ( x i − x 0 ) w i = b ( x i − x 0 ) − a ( y i − y 0 ) \begin {array}{l}u_i =c(y_i-y_0)-b(z_i-z_0)\\ v_i=a(z_i-z_0)-c(x_i-x_0)\\ w_i=b(x_i-x_0)-a(y_i-y_0)\end {array} ui=c(yi−y0)−b(zi−z0)vi=a(zi−z0)−c(xi−x0)wi=b(xi−x0)−a(yi−y0)
最小二乘优化能量方程
能量方程 E = f ( X 0 , A , r ) = ∑ 1 n d i 2 E=f(X0, A, r)=\displaystyle \sum _1^n {d_i^2} E=f(X0,A,r)=1∑ndi2
上式是一个7元二次函数中,X0, A, r是未知量,拟合3D圆的过程也可以理解为优化X0, A, r使得方程E最小。
上述方程直接求导不好解,可以使用高斯牛顿迭代法。
高斯牛顿迭代法
用于解非线性最小二乘问题。同时,高斯牛顿法需要比较可靠的初值,所以寻找目标函数的初值也是一个比较关键的步骤。
基本原理
设 a = ( a 0 , a 1 , . . . , a n ) 是待求解向量, a ^ 是初始给定值, a = a ^ + Δ a , Δ a 是我们每次迭代后移动的量 设 a=(a_0, a_1,...,a_n)是待求解向量,\widehat {a} 是初始给定值,a = \widehat {a} +\Delta a, \Delta a 是我们每次迭代后移动的量 设a=(a0,a1,...,an)是待求解向量,a 是初始给定值,a=a +Δa,Δa是我们每次迭代后移动的量
定义距离函数为 F ( x , a ) , d i = F ( x i , a ) , 进行泰勒 1 阶展开, F ( x , a ) = F ( x , a ^ ) + ∂ F ∂ a ^ Δ a = F ( x , a ^ ) + J Δ a 定义距离函数为 F(x, a), d_i = F(x_i, a), 进行泰勒1阶展开, F(x, a) = F(x, \widehat a) + \frac {\partial F}{\partial \widehat a}\Delta a = F(x, \widehat a) + J\Delta a 定义距离函数为F(x,a),di=F(xi,a),进行泰勒1阶展开,F(x,a)=F(x,a )+∂a ∂FΔa=F(x,a )+JΔa
每次迭代,其实就是希望通过调整 Δ a 使得 J Δ a = − F ( x , a ^ ) 每次迭代,其实就是希望通过调整\Delta a 使得 J\Delta a = -F(x, \widehat a) 每次迭代,其实就是希望通过调整Δa使得JΔa=−F(x,a )
J = [ ∂ F ( x 0 , a ) ∂ a 0 ∂ F ( x 0 , a ) ∂ a 1 . . . ∂ F ( x 0 , a ) ∂ a n ∂ F ( x 1 , a ) ∂ a 0 ∂ F ( x 1 , a ) ∂ a 1 . . . ∂ F ( x 1 , a ) ∂ a n . . . . . . . . . . . . ∂ F ( x n , a ) ∂ a 0 ∂ F ( x n , a ) ∂ a 1 . . . ∂ F ( x n , a ) ∂ a n ] J = \begin {bmatrix} \frac {\partial F(x_0, a)} {\partial a_0} & \frac {\partial F(x_0, a)} {\partial a_1} & ...& \frac {\partial F(x_0, a)} {\partial a_n} \\ \\ \frac {\partial F(x_1, a)} {\partial a_0} & \frac {\partial F(x_1, a)} {\partial a_1} & ...& \frac {\partial F(x_1, a)} {\partial a_n} \\\\ ... & ... & ...& ... \\ \\ \frac {\partial F(x_n, a)} {\partial a_0} & \frac {\partial F(x_n, a)} {\partial a_1} & ...& \frac {\partial F(x_n, a)} {\partial a_n} \end {bmatrix} J= ∂a0∂F(x0,a)∂a0∂F(x1,a)...∂a0∂F(xn,a)∂a1∂F(x0,a)∂a1∂F(x1,a)...∂a1∂F(xn,a)............∂an∂F(x0,a)∂an∂F(x1,a)...∂an∂F(xn,a)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3394
3394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









