




✅ 博主简介:擅长数据搜集与处理、建模仿真、程序设计、仿真代码、论文写作与指导,毕业论文、期刊论文经验交流。
✅成品或者定制,扫描文章底部微信二维码。
(1)低差异序列与协同学习飞蛾火焰优化算法:针对传统飞蛾火焰优化算法(MFO)在分布式车间调度问题中初始种群分布不均、全局搜索能力不足的缺陷,提出低差异序列与协同学习飞蛾火焰优化算法(LDS-CLMFO)。该算法采用索博尔序列(Sobol Sequence)生成初始种群,利用低差异序列的均匀分布特性,确保初始解在调度问题的解空间中均匀覆盖,避免因初始解集中导致的搜索盲区。在飞蛾位置更新阶段,引入协同学习策略,打破传统MFO仅依赖火焰信息更新位置的局限,使飞蛾能够同时学习种群中多个优秀个体(包括当前最优火焰、历史最优解及随机选取的其他飞蛾)的信息,构建多元化的位置更新方向,提升算法的全局搜索能力。设计动态火焰更新机制,根据飞蛾与火焰的适应度差异自适应调整火焰数量,在迭代前期保留较多火焰以扩大搜索范围,在迭代后期减少火焰数量以强化局部收敛。同时,引入精英保留与劣解淘汰机制,将每代中的最优解存入精英池,定期淘汰适应度较差的飞蛾,提升种群整体质量。在标准车间调度测试集(如FT、LA系列)上的实验表明,LDS-CLMFO算法的最优解质量较传统MFO提升32%,收敛速度提升25%,能够有效处理分布式车间调度中的复杂约束。
(2)强化学习与多策略融合飞蛾火焰优化算法:为解决MFO算法在分时电价环境下易出现早熟收敛、难以平衡全局搜索与局部开发的问题,提出强化学习与多策略融合飞蛾火焰优化算法(RL-MS-MFO)。该算法构建基于Q-Learning的强化学习框架,将算法的搜索过程划分为不同状态(如种群多样性、收敛进度、当前最优解质量),以多种搜索策略(包括高斯变异、柯西变异、列维飞行、邻域搜索、交叉变异等)作为动作空间,以调度方案的目标函数改进量(总电价成本与最大完工时间的加权和)作为奖励信号。通过Q-Learning算法持续学习不同状态下的最优策略选择,实现搜索策略的自适应切换:在种群多样性较高时,优先选择全局搜索策略(如列维飞行)扩大搜索范围;在种群多样性较低时,优先选择局部优化策略(如邻域搜索)提升解的精度。为进一步提升算法性能,设计策略融合机制,将多种策略进行组合使用,形成协同优化效果。在CEC 2017基准测试集与分时电价下分布式车间调度实例上的实验结果显示,RL-MS-MFO算法的IGD值较对比算法(如MFO、PSO、GA)平均降低41%,在处理大规模调度问题(工件数超过50,机器数超过10)时仍保持稳定的优化性能。
(3)逆向强化学习驱动的协同优化框架:针对分时电价下分布式异构零等待流水车间调度问题(DHNWFSP-TOU)的复杂特性,提出逆向强化学习驱动的协同优化框架(IRL-COF)。该框架首先构建多目标优化模型,以最大完工时间最小化与总电价成本最低化为核心目标,考虑可再生能源接入、机器异构性、零等待约束、分时电价差异等多重因素。在优化算法设计上,采用逆向强化学习算法从历史最优调度数据中学习奖励函数,替代人工设置奖励函数的主观性,使奖励信号更贴合调度问题的实际特性。构建包含多种问题相关搜索策略的策略池,如基于工序重排序的局部搜索、基于机器分配调整的全局搜索、基于电价时段划分的时段优化等。通过Q-Learning算法利用逆向强化学习得到的奖励函数,在每代迭代中自适应选择最优的搜索策略组合,实现全局搜索与局部开发的动态平衡。为提升初始种群质量,采用改进的Nawaz-Enscore-Ham(NEH)启发式算法与基于电价时段的贪心算法协同生成初始解,确保初始解既满足工艺约束,又能充分利用分时电价优势。在720个标准测试用例上的实验验证表明,IRL-COF框架能够有效降低总电价成本(平均降低18%)与最大完工时间(平均缩短22%),较传统优化算法具有更优的综合性能。
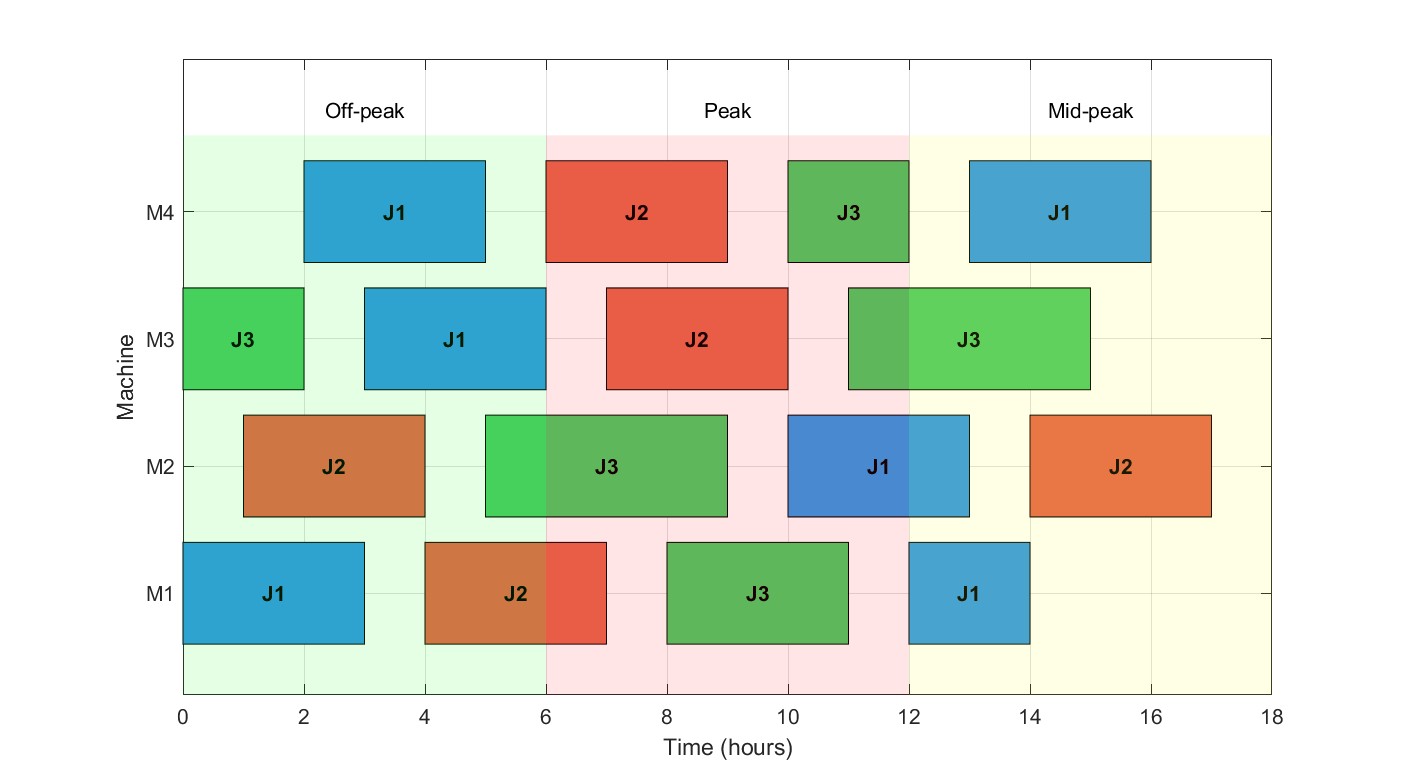
成品代码50-200,定制300起,可以直接沟通
👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇👇


















 615
615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











