



文章目录
1.数据集准备
准备你要进行分类的数据集,可以自己拍摄,可以网上进行爬取。
- 将不同类的数据图片放在单独文件夹中(每种类别数据尽可能均衡、数目尽可能多)
在网上爬取数据的python代码:
import os
import time
import requests
import urllib3
urllib3.disable_warnings()
from tqdm import tqdm #进度条库
import os
def craw_single_class(keyword, DOWNLOAD_NUM=50):
"""
参数说明:
keyword: 爬取对象
DOWNLOAD_NUM:爬取的数量
"""
########################HTTP请求参数###############################
cookies = {
'BDqhfp': '%E7%8B%97%E7%8B%97%26%26NaN-1undefined%26%2618880%26%2621',
'BIDUPSID': '06338E0BE23C6ADB52165ACEB972355B',
'PSTM': '1646905430',
'BAIDUID': '104BD58A7C408DABABCAC9E0A1B184B4:FG=1',
'BDORZ': 'B490B5EBF6F3CD402E515D22BCDA1598',
'H_PS_PSSID': '35836_35105_31254_36024_36005_34584_36142_36120_36032_35993_35984_35319_26350_35723_22160_36061',
'BDSFRCVID': '8--OJexroG0xMovDbuOS5T78igKKHJQTDYLtOwXPsp3LGJLVgaSTEG0PtjcEHMA-2ZlgogKK02OTH6KF_2uxOjjg8UtVJeC6EG0Ptf8g0M5',
'H_BDCLCKID_SF': 'tJPqoKtbtDI3fP36qR3KhPt8Kpby2D62aKDs2nopBhcqEIL4QTQM5p5yQ2c7LUvtynT2KJnz3Po8MUbSj4QoDjFjXJ7RJRJbK6vwKJ5s5h5nhMJSb67JDMP0-4F8exry523ioIovQpn0MhQ3DRoWXPIqbN7P-p5Z5mAqKl0MLPbtbb0xXj_0D6bBjHujtT_s2TTKLPK8fCnBDP59MDTjhPrMypomWMT-0bFH_-5L-l5js56SbU5hW5LSQxQ3QhLDQNn7_JjOX-0bVIj6Wl_-etP3yarQhxQxtNRdXInjtpvhHR38MpbobUPUDa59LUvEJgcdot5yBbc8eIna5hjkbfJBQttjQn3hfIkj0DKLtD8bMC-RDjt35n-Wqxobbtof-KOhLTrJaDkWsx7Oy4oTj6DD5lrG0P6RHmb8ht59JROPSU7mhqb_3MvB-fnEbf7r-2TP_R6GBPQtqMbIQft20-DIeMtjBMJaJRCqWR7jWhk2hl72ybCMQlRX5q79atTMfNTJ-qcH0KQpsIJM5-DWbT8EjHCet5DJJn4j_Dv5b-0aKRcY-tT5M-Lf5eT22-usy6Qd2hcH0KLKDh6gb4PhQKuZ5qutLTb4QTbqWKJcKfb1MRjvMPnF-tKZDb-JXtr92nuDal5TtUthSDnTDMRhXfIL04nyKMnitnr9-pnLJpQrh459XP68bTkA5bjZKxtq3mkjbPbDfn02eCKuj6tWj6j0DNRabK6aKC5bL6rJabC3b5CzXU6q2bDeQN3OW4Rq3Irt2M8aQI0WjJ3oyU7k0q0vWtvJWbbvLT7johRTWqR4enjb3MonDh83Mxb4BUrCHRrzWn3O5hvvhKoO3MA-yUKmDloOW-TB5bbPLUQF5l8-sq0x0bOte-bQXH_E5bj2qRCqVIKa3f',
'BDSFRCVID_BFESS': '8--OJexroG0xMovDbuOS5T78igKKHJQTDYLtOwXPsp3LGJLVgaSTEG0PtjcEHMA-2ZlgogKK02OTH6KF_2uxOjjg8UtVJeC6EG0Ptf8g0M5',
'H_BDCLCKID_SF_BFESS': 'tJPqoKtbtDI3fP36qR3KhPt8Kpby2D62aKDs2nopBhcqEIL4QTQM5p5yQ2c7LUvtynT2KJnz3Po8MUbSj4QoDjFjXJ7RJRJbK6vwKJ5s5h5nhMJSb67JDMP0-4F8exry523ioIovQpn0MhQ3DRoWXPIqbN7P-p5Z5mAqKl0MLPbtbb0xXj_0D6bBjHujtT_s2TTKLPK8fCnBDP59MDTjhPrMypomWMT-0bFH_-5L-l5js56SbU5hW5LSQxQ3QhLDQNn7_JjOX-0bVIj6Wl_-etP3yarQhxQxtNRdXInjtpvhHR38MpbobUPUDa59LUvEJgcdot5yBbc8eIna5hjkbfJBQttjQn3hfIkj0DKLtD8bMC-RDjt35n-Wqxobbtof-KOhLTrJaDkWsx7Oy4oTj6DD5lrG0P6RHmb8ht59JROPSU7mhqb_3MvB-fnEbf7r-2TP_R6GBPQtqMbIQft20-DIeMtjBMJaJRCqWR7jWhk2hl72ybCMQlRX5q79atTMfNTJ-qcH0KQpsIJM5-DWbT8EjHCet5DJJn4j_Dv5b-0aKRcY-tT5M-Lf5eT22-usy6Qd2hcH0KLKDh6gb4PhQKuZ5qutLTb4QTbqWKJcKfb1MRjvMPnF-tKZDb-JXtr92nuDal5TtUthSDnTDMRhXfIL04nyKMnitnr9-pnLJpQrh459XP68bTkA5bjZKxtq3mkjbPbDfn02eCKuj6tWj6j0DNRabK6aKC5bL6rJabC3b5CzXU6q2bDeQN3OW4Rq3Irt2M8aQI0WjJ3oyU7k0q0vWtvJWbbvLT7johRTWqR4enjb3MonDh83Mxb4BUrCHRrzWn3O5hvvhKoO3MA-yUKmDloOW-TB5bbPLUQF5l8-sq0x0bOte-bQXH_E5bj2qRCqVIKa3f',
'indexPageSugList': '%5B%22%E7%8B%97%E7%8B%97%22%5D',
'cleanHistoryStatus': '0',
'BAIDUID_BFESS': '104BD58A7C408DABABCAC9E0A1B184B4:FG=1',
'BDRCVFR[dG2JNJb_ajR]': 'mk3SLVN4HKm',
'BDRCVFR[-pGxjrCMryR]': 'mk3SLVN4HKm',
'ab_sr': '1.0.1_Y2YxZDkwMWZkMmY2MzA4MGU0OTNhMzVlNTcwMmM2MWE4YWU4OTc1ZjZmZDM2N2RjYmVkMzFiY2NjNWM4Nzk4NzBlZTliYWU0ZTAyODkzNDA3YzNiMTVjMTllMzQ0MGJlZjAwYzk5MDdjNWM0MzJmMDdhOWNhYTZhMjIwODc5MDMxN2QyMmE1YTFmN2QyY2M1M2VmZDkzMjMyOThiYmNhZA==',
'delPer': '0',
'PSINO': '2',
'BA_HECTOR': '8h24a024042g05alup1h3g0aq0q',
}
headers = {
'Connection': 'keep-alive',
'sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="97", "Chromium";v="97"',
'Accept': 'text/plain, */*; q=0.01',
'X-Requested-With': 'XMLHttpRequest',
'sec-ch-ua-mobile': '?0',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36',
'sec-ch-ua-platform': '"macOS"',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Dest': 'empty',
'Referer': 'https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1647837998851_R&pv=&ic=&nc=1&z=&hd=&latest=©right=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&dyTabStr=MCwzLDIsNiwxLDUsNCw4LDcsOQ%3D%3D&ie=utf-8&sid=&word=%E7%8B%97%E7%8B%97',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
############################创建文件夹################################
if os.path.exists('dataset/' + keyword):
print('文件夹 dataset/{} 已存在,之后直接将爬取到的图片保存至该文件夹中'.format(keyword))
else:
os.makedirs('dataset/{}'.format(keyword))
print('新建文件夹:dataset/{}'.format(keyword))
#####################爬取并保存图像文件至本地#########################
count = 1
with tqdm(total=DOWNLOAD_NUM, position=0, leave=True) as pbar:
num = 0 # 爬取第几张
FLAG = True # 是否继续爬取
while FLAG:
page = 30 * count
params = (
('tn', 'resultjson_com'),
('logid', '12508239107856075440'),
('ipn', 'rj'),
('ct', '201326592'),
('is', ''),
('fp', 'result'),
('fr', ''),
('word', f'{keyword}'),
('queryWord', f'{keyword}'),
('cl', '2'),
('lm', '-1'),
('ie', 'utf-8'),
('oe', 'utf-8'),
('adpicid', ''),
('st', '-1'),
('z', ''),
('ic', ''),
('hd', ''),
('latest', ''),
('copyright', ''),
('s', ''),
('se', ''),
('tab', ''),
('width', ''),
('height', ''),
('face', '0'),
('istype', '2'),
('qc', ''),
('nc', '1'),
('expermode', ''),
('nojc', ''),
('isAsync', ''),
('pn', f'{page}'),
('rn', '30'),
('gsm', '1e'),
('1647838001666', ''),
)
response = requests.get('https://image.baidu.com/search/acjson', headers=headers, params=params,
cookies=cookies)
if response.status_code == 200:
try:
json_data = response.json().get("data")
if json_data:
for x in json_data:
type = x.get("type")
if type not in ["gif"]: # 剔除gif格式的图片
img = x.get("thumbURL")
fromPageTitleEnc = x.get("fromPageTitleEnc")
try:
resp = requests.get(url=img, verify=False)
time.sleep(1)
# print(f"链接 {img}")
# 保存文件名
# file_save_path = f'dataset/{keyword}/{keyword}_{num}-{fromPageTitleEnc}.{type}'
file_save_path = f'dataset/{keyword}/{num}.{type}'
with open(file_save_path, 'wb') as f:
f.write(resp.content)
f.flush()
# print('第 {} 张图像 {} 爬取完成'.format(num, fromPageTitleEnc))
num += 1
pbar.update(1) # 进度条更新
# 爬取数量达到要求
if num > DOWNLOAD_NUM:
FLAG = False
print('{} 张图像爬取完毕'.format(num))
break
except Exception:
pass
except:
pass
else:
break
count += 1
craw_single_class('鸟', DOWNLOAD_NUM = 500)
2. 数据增强
比如说:旋转、翻转、增强对比度、高斯噪点、椒盐噪点等
可以通过Python OpenCV来实现。
以下是一些数据增强的代码(效果可能不好,参数需要自己调节)
import random
import os
from PIL import Image, ImageEnhance
import numpy as np
# 图片文件夹路径
srcPath = r'E:\\文档\\24-25(2)教学资料\\深度学习框架与应用\\代码\\Pytorch教学代码\\CNN_Classifier\\dataset\\小熊猫'
dstPath = r'E:\\文档\\24-25(2)教学资料\\深度学习框架与应用\\代码\\Pytorch教学代码\\CNN_Classifier\\dataset\\小熊猫_augmented'
def IncreaseImage(srcPath, dstPath):
for filename in os.listdir(srcPath):
# 拼接完整的文件或文件夹路径
srcFile = os.path.join(srcPath, filename)
dstFile = os.path.join(dstPath, filename)
# 如果是文件就处理
if os.path.isfile(srcFile):
try:
img = Image.open(srcFile)
# img = img.resize((224, 224), Image.LANCZOS)
# 确保目标文件夹存在
os.makedirs(dstPath, exist_ok=True)
# 保存不同变换的图片
img.save(dstFile)
img.transpose(Image.ROTATE_90).save(dstFile.replace('.', '_r90.'))
img.transpose(Image.FLIP_LEFT_RIGHT).save(dstFile.replace('.', '_flipped.'))
img.transpose(Image.FLIP_TOP_BOTTOM).save(dstFile.replace('.', '_flipped_tb.'))
# 使用固定的增强因子
factor = np.random.randint(11, 20) / 10
ImageEnhance.Contrast(img).enhance(factor).save(dstFile.replace('.', '_contrast.'))
ImageEnhance.Color(img).enhance(factor).save(dstFile.replace('.', '_color.'))
ImageEnhance.Sharpness(img).enhance(factor).save(dstFile.replace('.', '_sharp.'))
# 添加黑白噪声
def salt_and_pepper_noise(img, proportion=0.03):
noise_img = img.copy()
pixels = noise_img.load()
height, width = noise_img.size
num = int(height * width * proportion)
for i in range(num):
w = random.randint(0, width - 1)
h = random.randint(0, height - 1)
pixels[h, w] = (0, 0, 0) if random.random() < 0.5 else (255, 255, 255)
return noise_img
salt_and_pepper_noise(img).save(dstFile.replace('.', '_noise.'))
print(f"Processed {dstFile}")
except Exception as e:
print(f"Failed to process {dstFile}: {e}")
# 如果是文件夹就递归
elif os.path.isdir(srcFile):
new_dst_path = os.path.join(dstPath, filename)
IncreaseImage(srcFile, new_dst_path)
if __name__ == '__main__':
IncreaseImage(srcPath, dstPath)
3. 数据集划分
将每个类别图片随机划分为训练集和测试集。
- 假设三个类别,训练集文件夹下就应该包含3个类别的训练集子文件;测试集文件下就应该包含三个类别的测试集子文件。
数据集划分代码:
# import numpy as np
import os
import random
import shutil
path = r'E:\\教学资料\\23-24(2)教学资料\\深度学习框架与应用\\代码\\Pytorch教学代码\\dataset\\动物\\鸟' # 原始数据集的路径
path1 = r'E:\\教学资料\\23-24(2)教学资料\\深度学习框架与应用\\代码\\Pytorch教学代码\\dataset\\动物\\train\\bird' # 训练集
path2 = r'E:\\教学资料\\23-24(2)教学资料\\深度学习框架与应用\\代码\\Pytorch教学代码\\dataset\\动物\\test\\bird' # 测试集
def datasetImage(path, path1,path2):
for filename in os.listdir(path):
if not os.path.exists(path1):
os.makedirs(path1)
if not os.path.exists(path2):
os.makedirs(path2)
pathfile = os.path.join(path, filename)
if os.path.isdir(pathfile):# 如果是文件夹就递归
datasetImage(pathfile, path1, path2)
# 如果是文件就处理
if os.path.isfile(pathfile):
data = os.listdir(path)
t = int(len(data) * 0.8)
for i in range(len(data)):
random.shuffle(data) # 打乱数据
for z in range(len(data)): # 将数据按8:2分到train和test中
print('z:', z, '\n')
pic_path = path + '\\' + data[z]
print('pic_path:', pic_path)
if z < t:
obj_path = path1 + '\\' + data[z]
shutil.copyfile(pic_path, obj_path)
print('train:', obj_path)
else:
obj_path = path2 + '\\' + data[z]
print('test:', obj_path) # 显示分类情况
shutil.copyfile(pic_path, obj_path) # 往train、val中复制图片
if (os.path.exists(pic_path)):
shutil.copyfile(pic_path, obj_path)
if __name__=='__main__':
datasetImage(path,path1,path2)
4.设计模型进行训练
对之前学的CNN模型进行魔改,模型训练框架基本都不变!
- 数据准备
- 设计模型
- 损失函数和优化器
- 模型训练
注意:这里我们没有使用plt函数来绘制损失曲线图,而是使用了tesorboard来记录训练情况。
4.1. 随便乱写的网络
import os
import numpy as np
import numpy as np
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader #For constructing DataLoader
from torchvision import transforms #For constructing DataLoader
from torchvision import datasets #For constructing DataLoader
import torch.nn.functional as F #For using function relu()
from torch.utils.tensorboard import SummaryWriter
# torch.cuda.current_device()
# torch.cuda.empty_cache()
# torch.cuda._initialized = True
batch_size=2
epochs=10
transform=transforms.Compose([transforms.Resize((224,224)),
transforms.ToTensor(),#Convert the PIL Image to Tensor.
transforms.Normalize((0.1307,),(0.3081,))])#The parameters are mean and std respectively.
train_dataset = datasets.ImageFolder('E:\\教学资料_yu\\23-24(2)教学资料\\深度学习框架与应用\\代码\\Pytorch教学代码\\dataset\\动物\\train\\',transform=transform)#获取路径,返回的是所有图的data、label
test_dataset = datasets.ImageFolder('E:\\教学资料_yu\\23-24(2)教学资料\\深度学习框架与应用\\代码\\Pytorch教学代码\\dataset\\动物\\test\\',transform=transform)
train_loader = DataLoader(dataset=train_dataset,batch_size=batch_size,shuffle=True)
test_loader = DataLoader(dataset=test_dataset,batch_size=batch_size,shuffle=False)
writer = SummaryWriter('E:\\教学资料_yu\\23-24(2)教学资料\\深度学习框架与应用\\代码\\Pytorch教学代码\\dataset\\动物\\runs\\log\\', comment='Net')
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1=nn.Conv2d(3,32,kernel_size=5)
self.conv2=nn.Conv2d(32,64,kernel_size=5)
self.conv3=nn.Conv2d(64,128,kernel_size=5,padding=1,bias=False)
self.conv4=nn.Conv2d(128,256,kernel_size=1,padding=1,bias=False)
self.pooling1=nn.MaxPool2d(2)
self.pooling2 = nn.MaxPool2d(2)
self.pooling3 = nn.MaxPool2d(2)
self.pooling4 = nn.MaxPool2d(2)
self.allBN =nn.BatchNorm2d(256)
self.fc=torch.nn.Linear(43264,4)
def forward(self,x):
# Flatten data from (n, 1,224, 224) to (n, )
x=self.conv1(x)
x = F.relu(x)
x=self.pooling1(x)
# x=F.relu(self.pooling(self.conv1(x)))#(n,16,110,110)
x=self.conv2(x)
x = F.relu(x)
x=self.pooling2(x)
#x=F.relu(self.pooling(self.conv2(x)))#(n,32,53,53)
x=self.conv3(x)
x = F.relu(x)
x=self.pooling3(x)
#x=F.relu(self.pooling(self.conv3(x)))#(n,64,25,25)
x=self.conv4(x)
x = F.relu(x)
x=self.pooling4(x)
x=self.allBN(x)
# x = F.relu(self.pooling(self.conv4(x))) # (n,256,13,13)
batch_size = x.size(0) # (n,3,28,28)
out=x.view(batch_size,-1)#flatten
out=self.fc(out)
out = F.dropout(out, 0.6, training=self.training)
return out
model=Net()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#Define device as the first visible cuda device if we have CUDA available.
model.to(device)
# Convert parameters and buffers of all modules to CUDA Tensor.
criterion=torch.nn.CrossEntropyLoss()
optimizer=torch.optim.SGD(model.parameters(),lr=0.01,momentum=0.5)
def train(epoch):
total=0.0
correct=0.0
running_loss=0.0
for batch_id,data in enumerate(train_loader,0):
inputs,target=data
inputs,target=inputs.to(device),target.to(device)
#Send the inputs and targets at every step to the GPU
optimizer.zero_grad()
# forward + backward + update
outputs=model(inputs)
loss=criterion(outputs,target)
loss.backward()
optimizer.step()
running_loss +=loss.item()
#print('[%d,%5d] loss: %.3f' % (epoch + 1, batch_id, running_loss ))
#running_loss = 0.0
predicted = torch.argmax(outputs.data, dim=1)
total += target.size(0)
correct += (predicted == target).sum().item()
accuracy = 100 * correct / total
if (batch_id)% 100==99:
print('[%d,%5d] loss: %.3f' % (epoch+1,batch_id,running_loss/100))
running_loss=0.0
print('Accuracy on train set : %d %% [%d/%d]' % (100 * correct / total, correct, total))
writer.add_scalar('train accuracy',accuracy, epoch)
writer.add_scalar('train loss', running_loss, epoch)
writer.add_graph(model, (inputs,))
writer.flush()
def test():
correct=0
total=0
#predata = []
#lable = []
with torch.no_grad():
for batch_id,data in enumerate(test_loader,0):
inputs,target=data
inputs,target=inputs.to(device),target.to(device)
#Send the inputs and targets at every step to the GPU
outputs=model(inputs)
predicted=torch.argmax(outputs.data,dim=1)
#predata.append(predicted.item())
#lable.append(target.item())
total+=target.size(0)
correct+=(predicted==target).sum().item()
print('Accuracy on test set : %d %% [%d/%d]'%(100*correct/total,correct,total))
#print(predata)
#print(lable)
#print(test_dataset.class_to_idx)
writer.add_scalar('test accuracy', 100*correct/total, epoch)
writer.flush()
if __name__ == '__main__':
for epoch in range(epochs):
train(epoch)
test()
torch.save((model.state_dict(), 'E:\\教学资料_yu\\23-24(2)教学资料\\深度学习框架与应用\\代码\\Pytorch教学代码\\dataset\\动物\\runs\\result\\try.pt')
writer.flush()
writer.close()
#print(train_dataset[0][0].size())
#展示图像,乘标准差加均值,再转回PIL Image(上述过程的逆过程)
# show=transforms.ToPILImage()
# show(train_dataset[0][0]*0.5+0.5)
# print(train_dataset.class_to_idx) #查看类别名,及对应的标签。
# print(train_dataset.imgs) #查看路径里所有的图片,及对应的标签
# print(train_dataset[0][1]) #第1张图的label
# print(train_dataset[0][0])#第1张图的data
结果:
Accuracy on train set : 37 % [150/400]
[9, 299] loss: 1.504
Accuracy on train set : 38 % [231/600]
[9, 399] loss: 1.488
Accuracy on train set : 38 % [309/800]
[9, 499] loss: 1.418
Accuracy on train set : 38 % [383/1000]
Accuracy on test set : 37 % [106/286]
[10, 99] loss: 1.560
Accuracy on train set : 41 % [83/200]
[10, 199] loss: 1.405
Accuracy on train set : 40 % [162/400]
[10, 299] loss: 1.351
Accuracy on train set : 40 % [244/600]
[10, 399] loss: 1.471
Accuracy on train set : 39 % [318/800]
[10, 499] loss: 1.459
Accuracy on train set : 38 % [388/1000]
Accuracy on test set : 38 % [109/286]
tensorboard查看训练曲线: tensorboard --logdir=E:\\教学资料\\23-24(2)教学资料\\深度学习框架与应用\\代码\\Pytorch教学代码\\dataset\\动物\\runs\\log
TensorBoard 2.16.2 at http://localhost:6006/ (Press CTRL+C to quit)
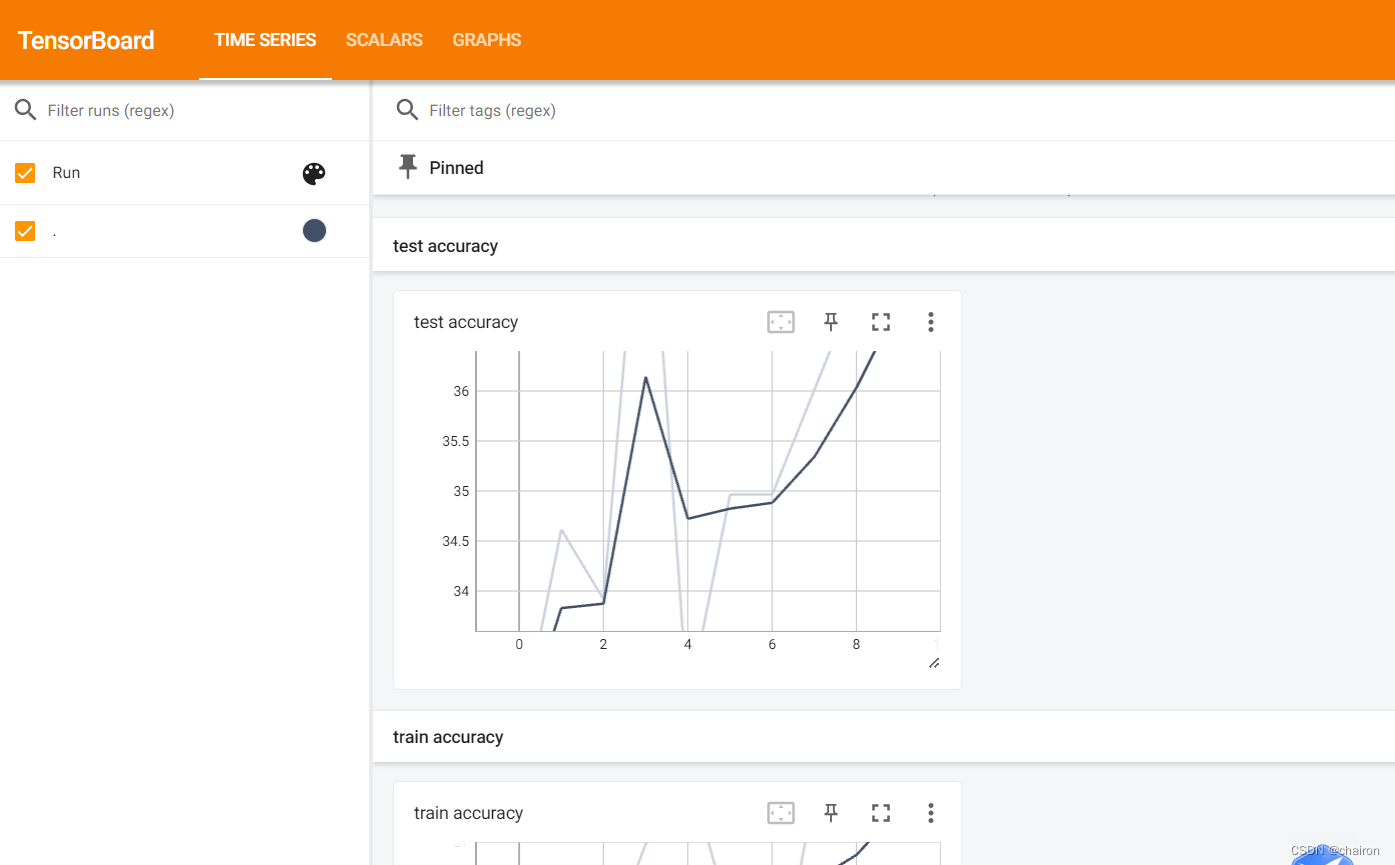
训练结果非常垃圾!
4.2. 借鉴优秀的网络模型(MobileNetV3)
import os
import numpy as np
import numpy as np
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader #For constructing DataLoader
from torchvision import transforms #For constructing DataLoader
from torchvision import datasets #For constructing DataLoader
import torch.nn.functional as F #For using function relu()
from torch.utils.tensorboard import SummaryWriter
# torch.cuda.current_device()
# torch.cuda.empty_cache()
# torch.cuda._initialized = True
batch_size=2
epochs=10
transform=transforms.Compose([transforms.Resize((224,224)),
transforms.ToTensor(),#Convert the PIL Image to Tensor.
transforms.Normalize((0.1307,),(0.3081,))])#The parameters are mean and std respectively.
train_dataset = datasets.ImageFolder('E:\\教学资料_yu\\23-24(2)教学资料\\深度学习框架与应用\\代码\\Pytorch教学代码\\dataset\\动物\\train\\',transform=transform)#获取路径,返回的是所有图的data、label
test_dataset = datasets.ImageFolder('E:\\教学资料_yu\\23-24(2)教学资料\\深度学习框架与应用\\代码\\Pytorch教学代码\\dataset\\动物\\test\\',transform=transform)
train_loader = DataLoader(dataset=train_dataset,batch_size=batch_size,shuffle=True)
test_loader = DataLoader(dataset=test_dataset,batch_size=batch_size,shuffle=False)
writer = SummaryWriter('E:\\教学资料_yu\\23-24(2)教学资料\\深度学习框架与应用\\代码\\Pytorch教学代码\\dataset\\动物\\runs\\log\\', comment='Net')
class hswish(nn.Module):
def __init__(self, inplace=True):
super(hswish, self).__init__()
self.inplace = inplace
def forward(self, x):
f = nn.functional.relu6(x + 3., inplace=self.inplace) / 6.
return x * f
class hsigmoid(nn.Module):
def __init__(self, inplace=True):
super(hsigmoid, self).__init__()
self.inplace = inplace
def forward(self, x):
f = nn.functional.relu6(x + 3., inplace=self.inplace) / 6.
return f
class SeModule(nn.Module):
def __init__(self, in_channels, se_ratio=0.25):
super(SeModule, self).__init__()
self.se_reduce = nn.Conv2d(in_channels, int(in_channels * se_ratio), kernel_size=1, stride=1, padding=0)
self.se_expand = nn.Conv2d(int(in_channels * se_ratio), in_channels, kernel_size=1, stride=1, padding=0)
def forward(self, x):
s = nn.functional.adaptive_avg_pool2d(x, 1)
s = self.se_expand(nn.functional.relu(self.se_reduce(s), inplace=True))
return x * s.sigmoid()
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding, groups=1):
super(ConvBlock, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, groups=groups, bias=False)
self.bn = nn.BatchNorm2d(out_channels)
self.act = hswish()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
class SqueezeExcitation(nn.Module):
def __init__(self, in_channel, out_channel, reduction=4):
super(SqueezeExcitation, self).__init__()
self.pool = nn.AdaptiveAvgPool2d(1)
self.fc1 = nn.Conv2d(in_channel, out_channel // reduction, kernel_size=1, stride=1)
self.relu = nn.ReLU(inplace=True)
self.fc2 = nn.Conv2d(out_channel // reduction, out_channel, kernel_size=1, stride=1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
out = self.pool(x)
out = self.fc1(out)
out = self.relu(out)
out = self.fc2(out)
out = self.sigmoid(out)
return out
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, use_se=True):
super(ResidualBlock, self).__init__()
self.conv1 = ConvBlock(in_channels, out_channels, kernel_size, stride, kernel_size // 2)
self.conv2 = ConvBlock(out_channels, out_channels, kernel_size, 1, kernel_size // 2)
self.use_se = use_se
if use_se:
self.se = SqueezeExcitation(out_channels, out_channels)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
if self.use_se:
out = out * self.se(out)
out += self.shortcut(x)
out = nn.functional.relu(out, inplace=True)
return out
class MobileNetV3(nn.Module):
def __init__(self, num_classes=1000):
super(MobileNetV3, self).__init__()
self.conv1 = ConvBlock(3, 16, 3, 2, 1) # 1/2
self.bottlenecks = nn.Sequential(
ResidualBlock(16, 16, 3, 2, False), # 1/4
ResidualBlock(16, 72, 3, 2, False), # 1/8
ResidualBlock(72, 72, 3, 1, False),
ResidualBlock(72, 72, 3, 1, True),
ResidualBlock(72, 96, 3, 2, True), # 1/16
ResidualBlock(96, 96, 3, 1, True),
ResidualBlock(96, 96, 3, 1, True),
ResidualBlock(96, 240, 5, 2, True), # 1/32
ResidualBlock(240, 240, 5, 1, True),
ResidualBlock(240, 240, 5, 1, True),
ResidualBlock(240, 480, 5, 1, True),
ResidualBlock(480, 480, 5, 1, True),
ResidualBlock(480, 480, 5, 1, True),
)
self.conv2 = ConvBlock(480, 576, 1, 1, 0, groups=2)
self.conv3 = nn.Conv2d(576, 1024, kernel_size=1, stride=1, padding=0, bias=False)
self.bn = nn.BatchNorm2d(1024)
self.act = hswish()
self.pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Linear(1024, num_classes)
def forward(self, x):
out = self.conv1(x)
out = self.bottlenecks(out)
out = self.conv2(out)
out = self.conv3(out)
out = self.bn(out)
out = self.act(out)
out = self.pool(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
model=MobileNetV3(num_classes=3)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#Define device as the first visible cuda device if we have CUDA available.
model.to(device)
# Convert parameters and buffers of all modules to CUDA Tensor.
criterion=torch.nn.CrossEntropyLoss()
optimizer=torch.optim.SGD(model.parameters(),lr=0.01,momentum=0.5)
def train(epoch):
total=0.0
correct=0.0
running_loss=0.0
for batch_id,data in enumerate(train_loader,0):
inputs,target=data
inputs,target=inputs.to(device),target.to(device)
#Send the inputs and targets at every step to the GPU
optimizer.zero_grad()
# forward + backward + update
outputs=model(inputs)
loss=criterion(outputs,target)
loss.backward()
optimizer.step()
running_loss +=loss.item()
# print('[%d,%5d] loss: %.3f' % (epoch + 1, batch_id, running_loss ))
# running_loss = 0.0
predicted = torch.argmax(outputs.data, dim=1)
total += target.size(0)
correct += (predicted == target).sum().item()
accuracy = 100 * correct / total
if (batch_id)% 100==99:
print('[%d,%5d] loss: %.3f' % (epoch+1,batch_id,running_loss/100))
running_loss=0.0
print('Accuracy on train set : %d %% [%d/%d]' % (100 * correct / total, correct, total))
writer.add_scalar('train accuracy',accuracy, epoch)
writer.add_scalar('train loss', running_loss, epoch)
writer.add_graph(model, (inputs,))
writer.flush()
def test():
correct=0
total=0
#predata = []
#lable = []
with torch.no_grad():
for batch_id,data in enumerate(test_loader,0):
inputs,target=data
inputs,target=inputs.to(device),target.to(device)
#Send the inputs and targets at every step to the GPU
outputs=model(inputs)
predicted=torch.argmax(outputs.data,dim=1)
#predata.append(predicted.item())
#lable.append(target.item())
total+=target.size(0)
correct+=(predicted==target).sum().item()
print('Accuracy on test set : %d %% [%d/%d]'%(100*correct/total,correct,total))
#print(predata)
#print(lable)
#print(test_dataset.class_to_idx)
writer.add_scalar('test accuracy', 100*correct/total, epoch)
writer.flush()
if __name__ == '__main__':
for epoch in range(epochs):
train(epoch)
test()
torch.save((model.state_dict(), 'E:\\教学资料_yu\\23-24(2)教学资料\\深度学习框架与应用\\代码\\Pytorch教学代码\\dataset\\动物\\runs\\result\\try1.pt')
writer.flush()
writer.close()
#print(train_dataset[0][0].size())
#展示图像,乘标准差加均值,再转回PIL Image(上述过程的逆过程)
# show=transforms.ToPILImage()
# show(train_dataset[0][0]*0.5+0.5)
# print(train_dataset.class_to_idx) #查看类别名,及对应的标签。
# print(train_dataset.imgs) #查看路径里所有的图片,及对应的标签
# print(train_dataset[0][1]) #第1张图的label
# print(train_dataset[0][0])#第1张图的data
结果:
[9, 499] loss: 0.778
Accuracy on train set : 61 % [618/1000]
Accuracy on test set : 48 % [139/286]
[10, 99] loss: 0.840
Accuracy on train set : 62 % [124/200]
[10, 199] loss: 0.823
Accuracy on train set : 60 % [242/400]
[10, 299] loss: 0.790
Accuracy on train set : 62 % [372/600]
[10, 399] loss: 0.730
Accuracy on train set : 63 % [506/800]
[10, 499] loss: 0.767
Accuracy on train set : 63 % [633/1000]
Accuracy on test set : 51 % [148/286]
tensorboard:
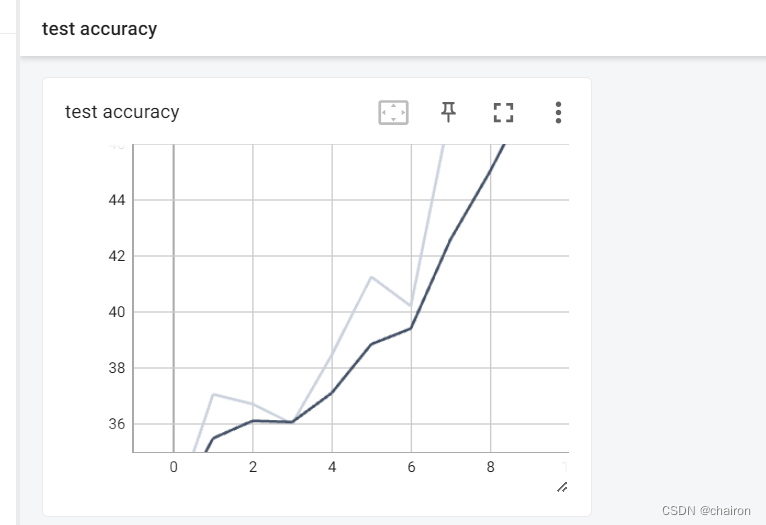
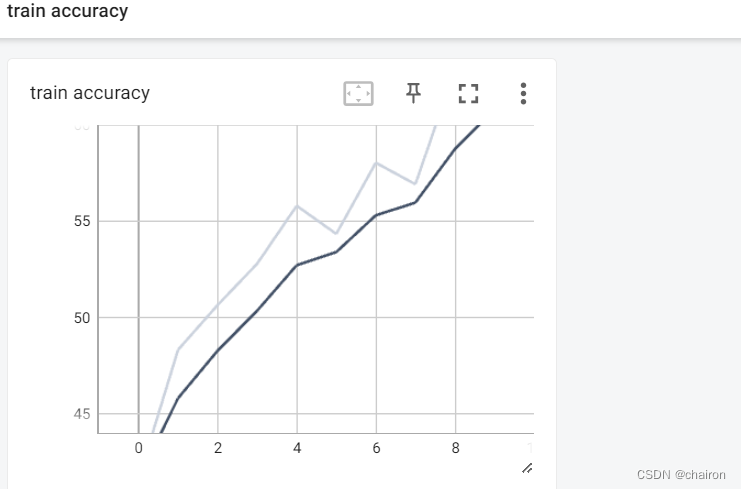
5.训练好的模型进行预测
从网上找一些新数据,让模型输出预测结果:
def eval():
#加载pt文件
model_path='dataset/动物/runs/result/try1.pt'
model_dict=torch.load(model_path,map_location=device)
#加载模型参数
model.load_state_dict(model_dict)
model.eval()
#加载数据
dir = 'F:\教学资料\\23-24(2)教学资料\\深度学习框架与应用\\代码\\Pytorch教学代码\\dataset\\动物\\eval\\'
for filename in os.listdir(dir):
# 拼接完整的文件或文件夹路径
eval_imge_path = os.path.join(dir, filename)
eval_imge = Image.open(eval_imge_path)#读取图片
input_tensor = transform(eval_imge)#转化为tensor
input_batch = input_tensor.unsqueeze(0)
input_batch = input_batch.to(device)#切换到GPU或者cpu
#预测
with torch.no_grad():
outputs = model(input_batch)
predicted = torch.argmax(outputs.data, dim=1)
print('predicted:',predicted.item())
结果:
predicted: 0
predicted: 2
predicted: 1
predicted: 0
predicted: 0
序号对应分别为:

5. 模型封装为ONNX
def onnx_export():
# 加载模型(正确方式)
model_path = 'dataset/动物/runs/result/try2.pt'
model_dict = torch.load(model_path, map_location=device)
#加载模型参数
model.load_state_dict(model_dict)
model.eval() # 设置为评估模式
x = torch.randn(1, 3, 224, 224).to(device)
# 导出ONNX模型
with torch.no_grad():
torch.onnx.export(
model, # 要转换的模型对象
x, # 模型的示例输入
'dataset/动物/runs/result/try2.onnx', # 导出的ONNX文件名
opset_version=11, # ONNX算子集版本
input_names=['input'], # 输入Tensor的名称
output_names=['output'], # 输出Tensor的名称
dynamic_axes={'input': {0: 'batch_size'}, 'output': {0: 'batch_size'}} # 支持动态batch
)
print("ONNX模型导出成功!")
分析:
- 以上只改了网络结构,模型并没有完全收敛。
- 因此还可以增加epoch、batch_size、调整超参数进行优化!
- 另外,爬取数据里面也有错误的数据,记得删除,否则会影响训练,爬取数据背景差异大,这也是训练困难的因素之一!
练习:
请尝试用各种经典网络进行优化模型,训练得到更好的结果!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









