




 RepVGG是一种在训练阶段采用多分支结构而在推理阶段转换为单一3x3卷积的网络,通过结构重参数化技术提高了网络的推理速度和内存效率。文章详细介绍了RepVGG的设计理念、工作原理及实验结果。
RepVGG是一种在训练阶段采用多分支结构而在推理阶段转换为单一3x3卷积的网络,通过结构重参数化技术提高了网络的推理速度和内存效率。文章详细介绍了RepVGG的设计理念、工作原理及实验结果。
RepVGG: Making VGG-style ConvNets Great Again
目录
- 提出了一种在训练阶段使用多分支网络结构,但是在inference时只有3x3卷积和Relu激活函数组成的单分支网络结构。
- 网络主要用了一种结构重参数化方法
a structural re-parameterization technique将训练时的多分枝融合为推理时的单分支结构。 - 因为inference时网络很像VGG结构,和使用re-parameterization方法,所以命名为RepVGG.
1. Introduction
1.1 多分支网络结构的缺点
- 多分支的网络结构减少程序的并发性,在推理时的速度慢,降低内存利用率(比如ResNet中残差分支的add、Inception结构的concatenation操作)
- 一些组件比如说深度可分离卷积、channel shuffle(ShuffleNets)会增加内存消耗,并且适用性不好。
1.2 RepVGG优点
很多因素影响推理速度,FLOPs的数量值不能真实反应实际的速度。
-
网络推理时是一条单分支结构。
-
只使用3x3卷积核ReLU激活函数。证明了kernel=3的有效性

-
网络简单,没有复杂的超参数。
-
RepVGG是由RepVGGBlock堆叠的简单网络,能很好的达到速度和精度的折中。证明了该网络在分类和分割上的有效性。
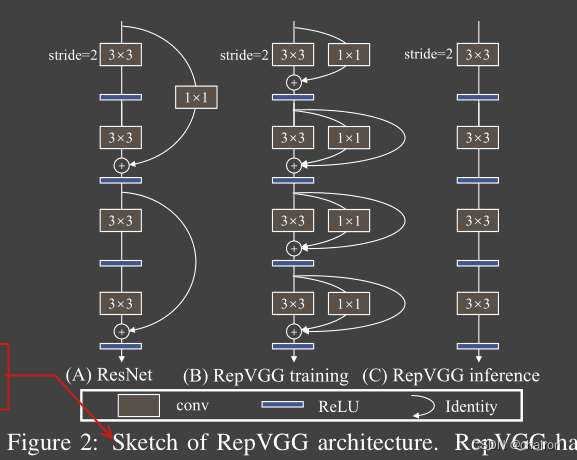
2. Model Re-parameterization(模型重参数化)
2.1. DiracNet
通过对普通卷积进行编码得到的一条单分支网络,也是 一种 re-parameterization method。
W = d i a g ( a ) I + d i a g ( b ) W n o r m W = diag(a)I + diag(b){W_{norm}} W=diag(a)I+diag(b)Wnorm
W W W是最终的卷积参数, a a a和 b b b是一个待学习的参数, W n o r m W_{norm} Wnorm是归一化后的卷积核
另外,之前看过的ACBlock、DO-Conv 、ExpandNet也可以看作是一种模型重参数化方法,他们是把一个block看成一个卷积,去代替普通卷积,是一种component-level improvements 。而本文提出的方法对应一个扁平(plain)的卷积网络来说是很重要的。
2.2 Winograd Convolution
Winograd is a classic algorithm for accelerating 3 × 3 conv (only if the stride is 1).
3. Building RepVGG via Structural Re-param
3.1Simple is Fast, Memory-economical, Flexible
-
Fast:
- == 内存访问成本(MAC)和并发度这两个影响推理速度的关键因素没有被考虑进FLOPs,因此FLOPs其实并不能反应真实的推理速度==
- 此外,在分组卷积中,MAC占用了很大一部分时间。另一方面,在相同的FLOPs下,一个具有高并行度的模型可能比另一个具有低并行度的模型快得多。
-
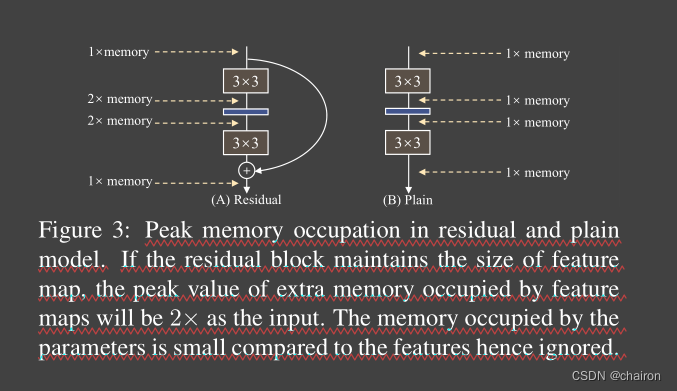
Memory-economical
- 多分支网络结构内存使用是无效率的,因为在add或者concatenate操作之前,每个分支的结果都需要保持,因此会导致内存占用量的峰值变高。
- 相比之下,普通单分支网络允许在操作完成时立即释放输入到特定图层的输入所占用的内存。在设计专门的硬件时,能做更深层次的内存优化,并降低内存单元的成本,这样我们就可以将更多的计算单元集成到芯片上。
-
Flexible
- 比如残差连接,必须要相同size才能add,就需要做一些操作和限制
- 多分枝结构限制了通道减枝(channel pruning)的运用
3.2 对ResNet的一段精辟解释
ResNet,它构造了一个shortcut分支来将信息流建模为 y = x + f ( x ) y = x+ f (x) y=x+f(x),并使用一个残差块来学习 f f f
当x和f (x)的维度不匹配时,它就变成了 y = g ( x ) + f ( x ) y = g (x) +f (x) y=g(x)+f(x),其中 g ( x ) g (x) g(x)是一个由一个1×1conv实现的shortcut。对ResNets成功的一个解释是,这样的多分支体系结构使模型成为一个由许多较浅的模型[36]组成的隐式集成。
ResNet, which explicitly constructs a shortcut branch to model the information flow as y = x + f(x) and uses a residual block to learn f. When the dimensions of x and f(x) do not match, it becomes y = g(x)+f(x), where g(x)is a convolutional shortcut implemented by a 1×1 conv.
RepVGG使用了像是ResNet中的恒等连接的一个分支,并且加了一个1x1卷积分支,共三个卷积分支进行相加: y = x + g ( x ) + f ( x ) y =x+ g (x) +f (x) y=x+g(x)+f(x)
3.3 Re-param for Plain Inference-time Model
训练阶段:
M ( 2 ) = b n ( M ( 1 ) ∗ W ( 3 ) , µ ( 3 ) , σ ( 3 ) , γ ( 3 ) , β ( 3 ) ) + b n ( M ( 1 ) ∗ W ( 1 ) , µ ( 1 ) , σ ( 1 ) , γ ( 1 ) , β ( 1 ) ) + b n ( M ( 1 ) , µ ( 0 ) , σ ( 0 ) , γ ( 0 ) , β ( 0 ) ) . M(2)= bn(M(1)∗ W(3), µ(3), σ(3), γ(3), β(3))+ bn(M(1)∗ W(1), µ(1), σ(1), γ(1), β(1))+ bn(M(1), µ(0), σ(0), γ(0), β(0)) . M(2)=bn(M(1)∗W(3),µ(3),σ(3),γ(3),β(3))
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 893
893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









