




 本文深入探讨了自注意力机制,它在处理输入数据时关注全局信息,但忽略了位置信息。通过Q、K、V向量计算注意力分数,实现序列信息的权重加权。多头自注意力允许捕捉不同相关性,而位置编码则为序列引入位置信息。相较于CNN,自注意力具有更灵活的感受野,与RNN相比,其并行性提供了速度优势。自注意力也被应用于图结构数据,仅考虑相邻节点间的注意力。对于长序列,截断自注意力可以降低计算量。理解这些概念对于掌握Transformer和其他现代NLP模型至关重要。
本文深入探讨了自注意力机制,它在处理输入数据时关注全局信息,但忽略了位置信息。通过Q、K、V向量计算注意力分数,实现序列信息的权重加权。多头自注意力允许捕捉不同相关性,而位置编码则为序列引入位置信息。相较于CNN,自注意力具有更灵活的感受野,与RNN相比,其并行性提供了速度优势。自注意力也被应用于图结构数据,仅考虑相邻节点间的注意力。对于长序列,截断自注意力可以降低计算量。理解这些概念对于掌握Transformer和其他现代NLP模型至关重要。
自注意力机制
1. self-attention
- 关注输入数据的全局信息
- 没有考虑位置信息
- 计算量是序列长度的平方
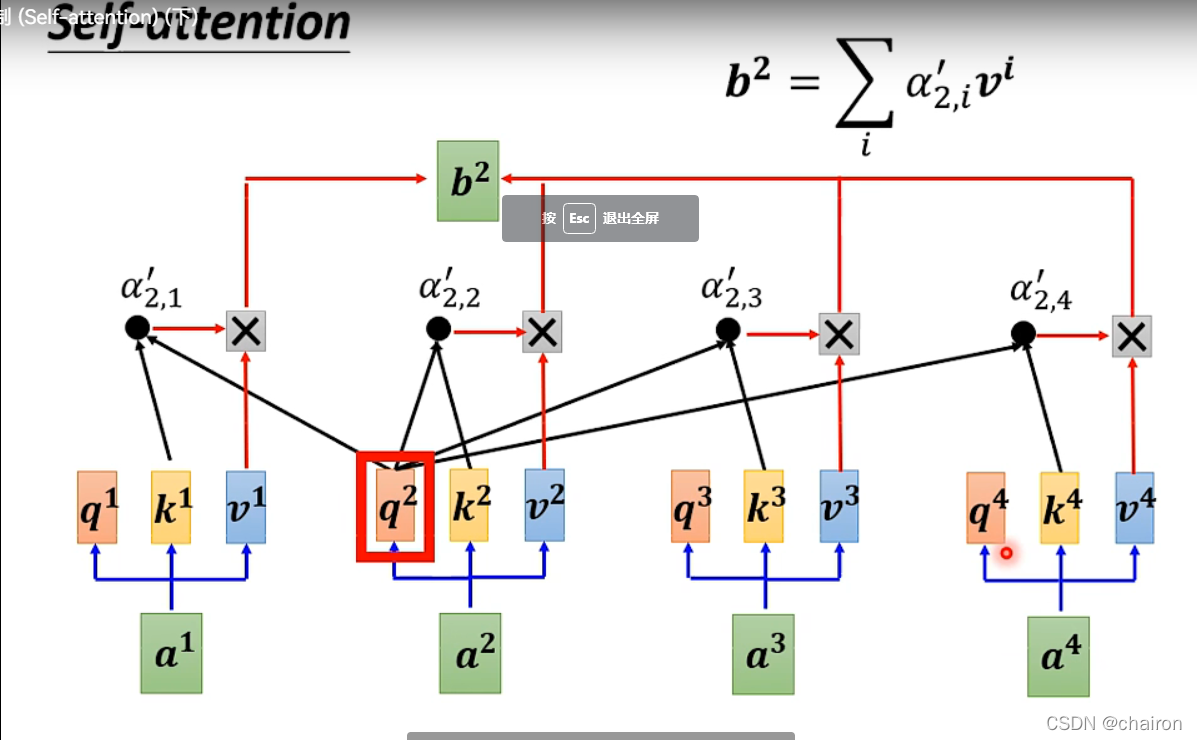
每个输入ai乘以不同的矩阵,得到向量q、k、v,q表示查询向量,用q乘以所有输入的k向量得到的值再进行softmax归一化,作为输入a的权重和输入a的v向量进行点乘,加起来就得到了a对应的输出:bi
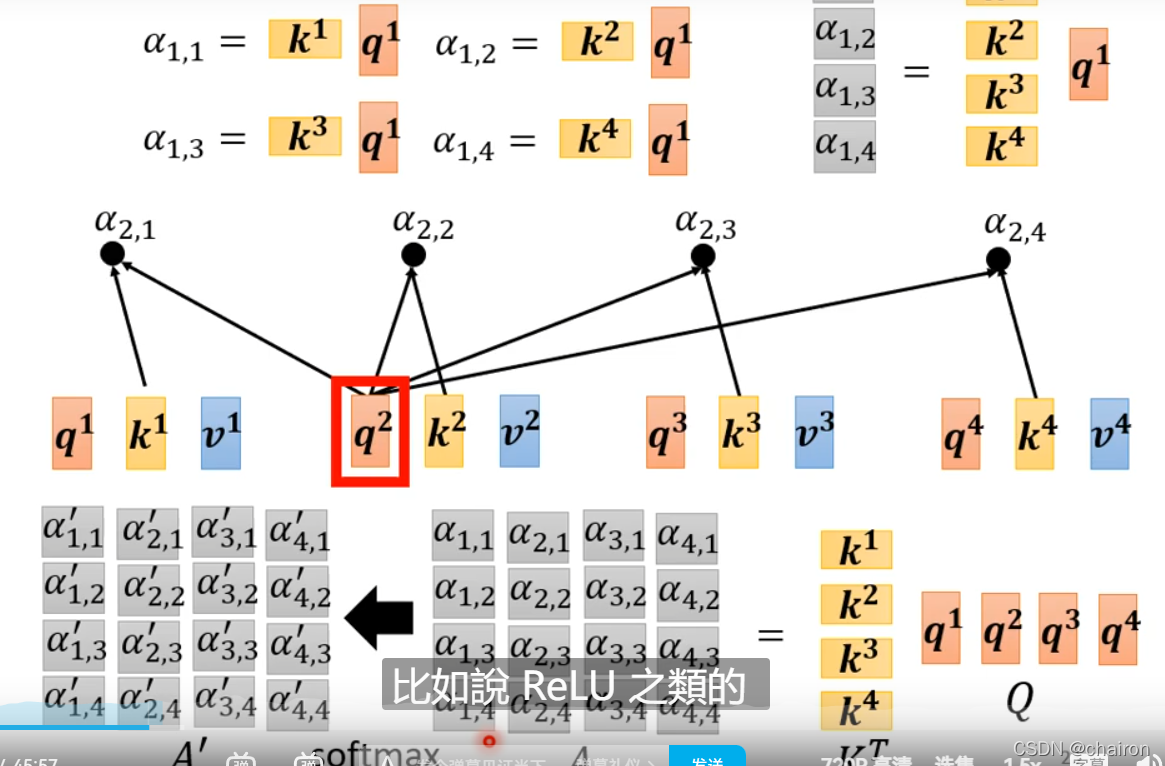
- 把全部输入看成一个向量I,分别乘以WqW^qWq,WkW^kWk,WvW^vWv(模型学习出来的参数),得到Q、K、V
- K的转置乘以Q得到Attention的分数A,再对每一列进行归一化,得到A’
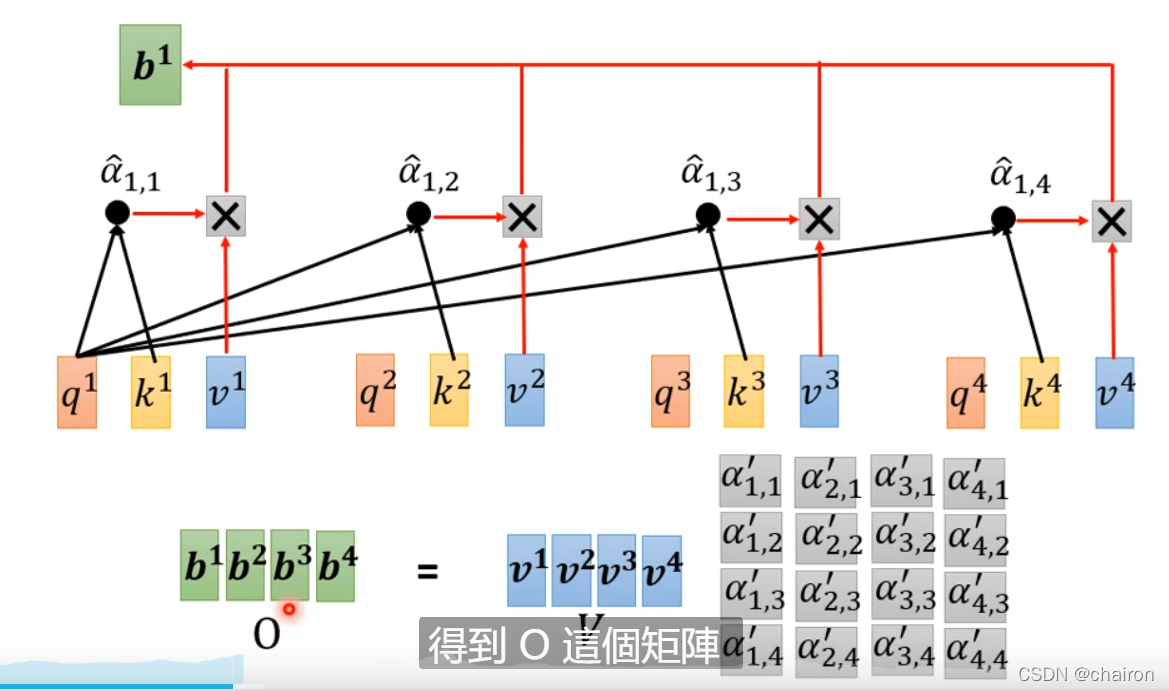
- 将V乘以得到分数矩阵A’,得到输出O
整体过程如下
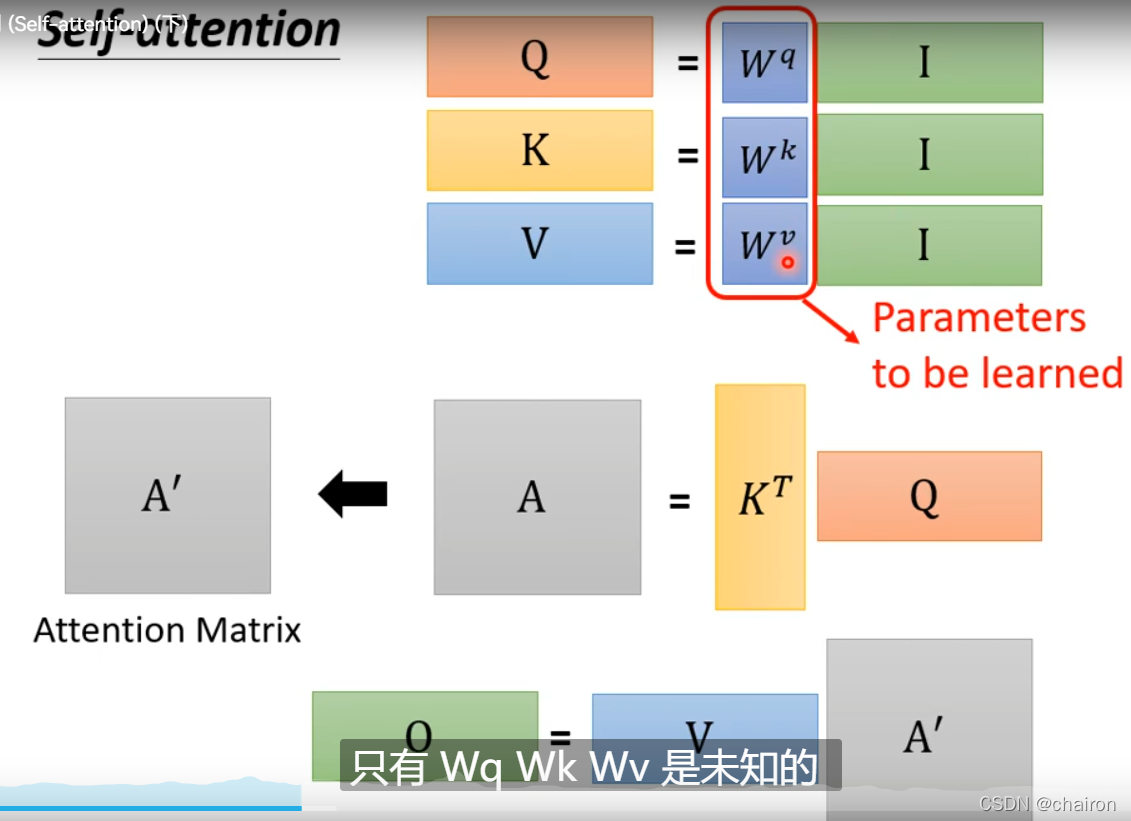
Attention(Q,K,V)=V∗softmax(KTQ)Attention(Q,K,V)=V*softmax(K^TQ)Attention(Q,K,V)=V∗softmax(KTQ)
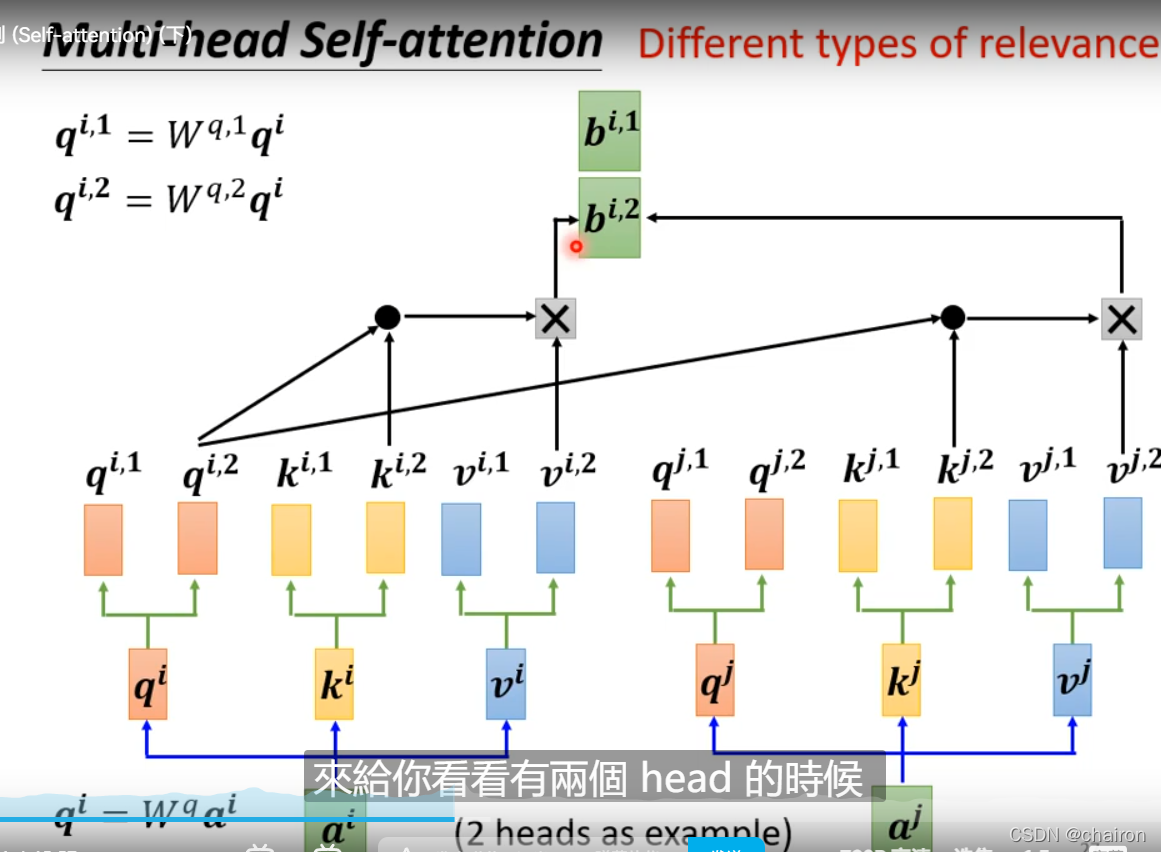
2. Multi-head Self-attention
可能输入之间存在不同的相关性

3. Positional Encoding
-
self-attention 没有考虑位置关系
-
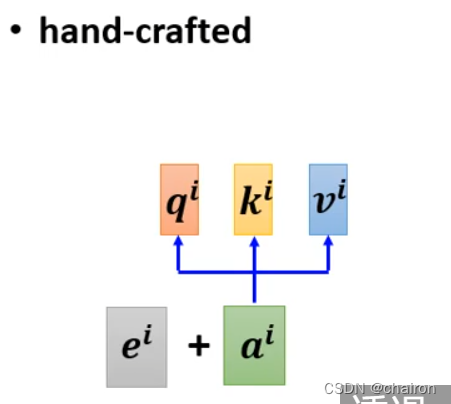
Positional Encoding为每个位置设置一个独一无二的位置向量 eie^iei
-
把ei加入到ai,手工设计的
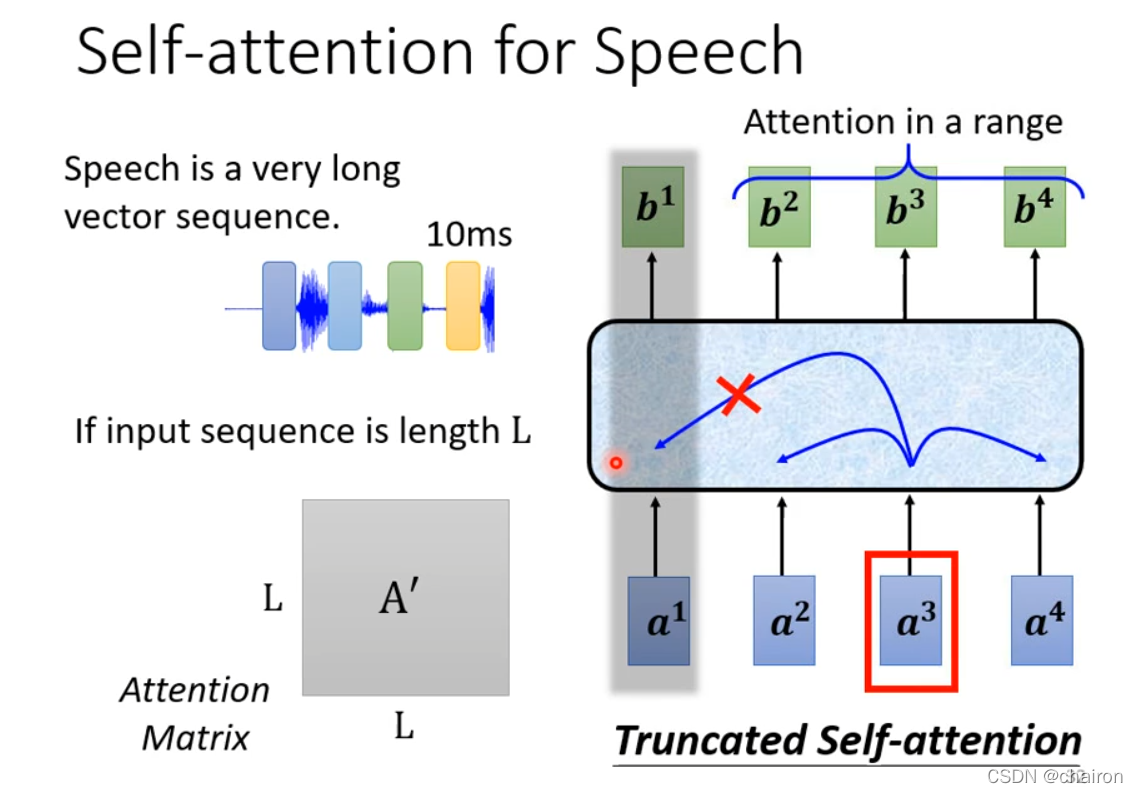
4. TruncatedSelf-attention
有些序列可能会非常长,比如说语音识别,也许没必要关注全局信息,可以只输入一部分信息就可以(比如说的这一小段语音是什么),减少计算量
5. Self-attention VS CNN
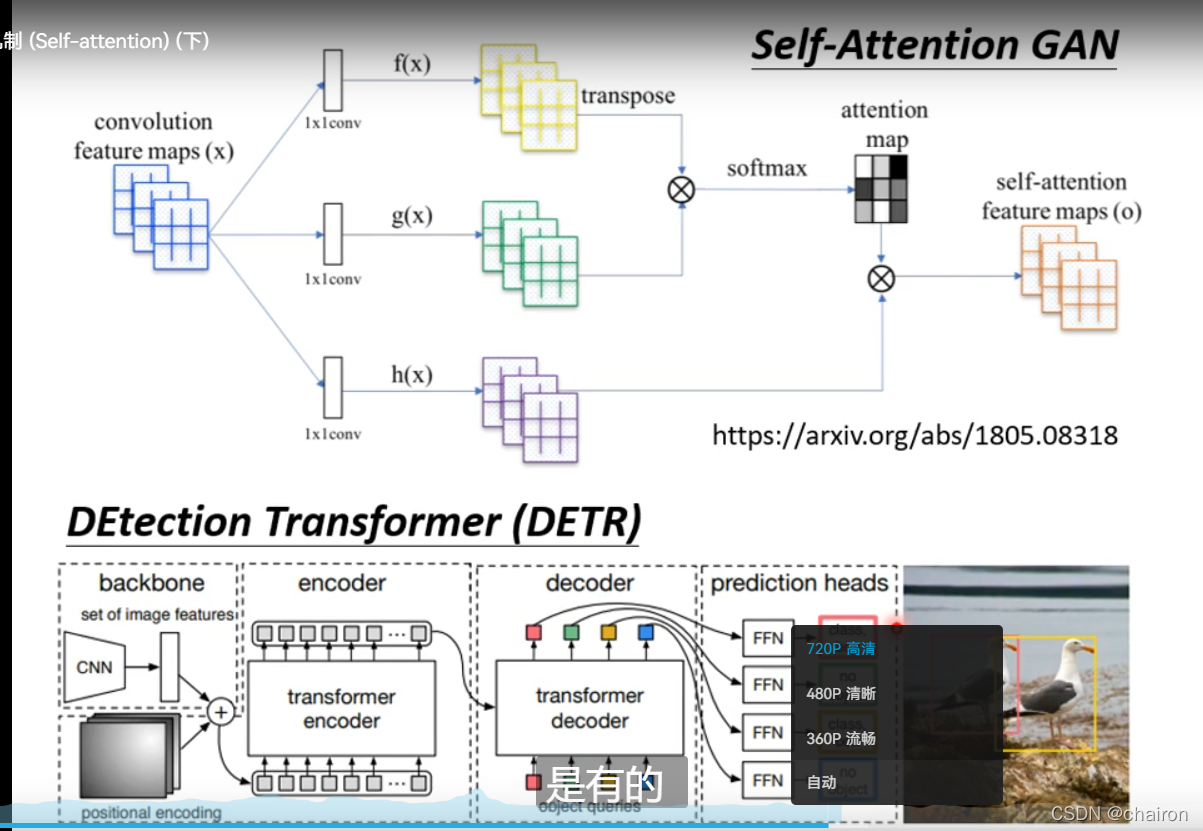
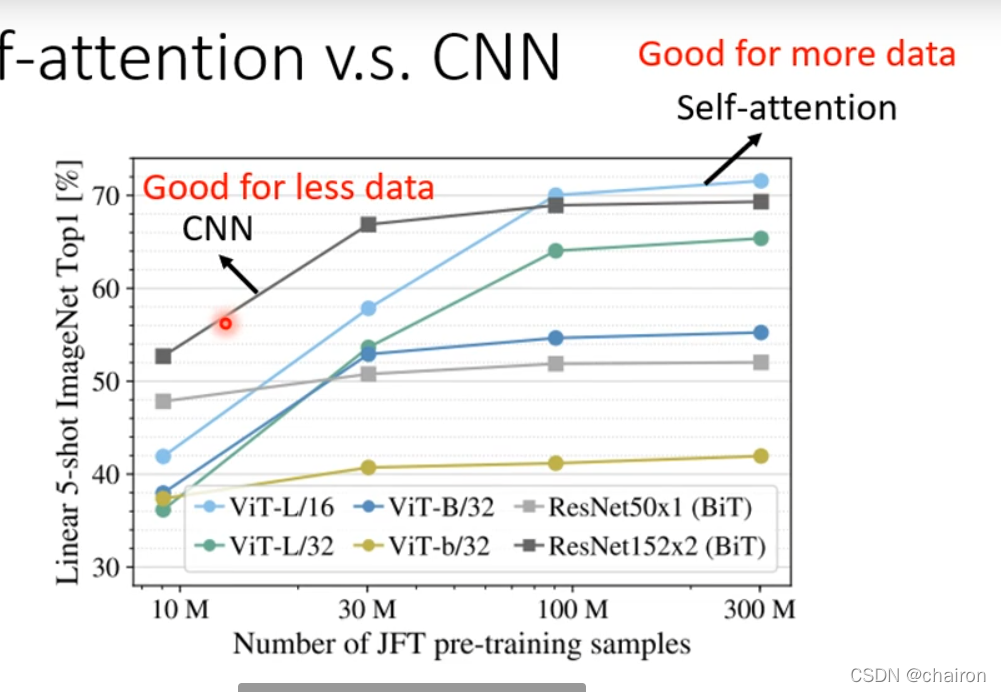
- CNN可以看成简化的Self-attention
- CNN只需要考虑感受野大小里的信息,感受野是人为设计的大小;而Self-attention从全局范围来看,通过学习决定哪些地方重要,自己决定感受野大小
- Self-attention可以看成可以自己学习感受野大小的CNN
- 比较小的模型更适合小的数据集,更灵活的模型需要更大的数据集,所有self-attention需要更大量的数据

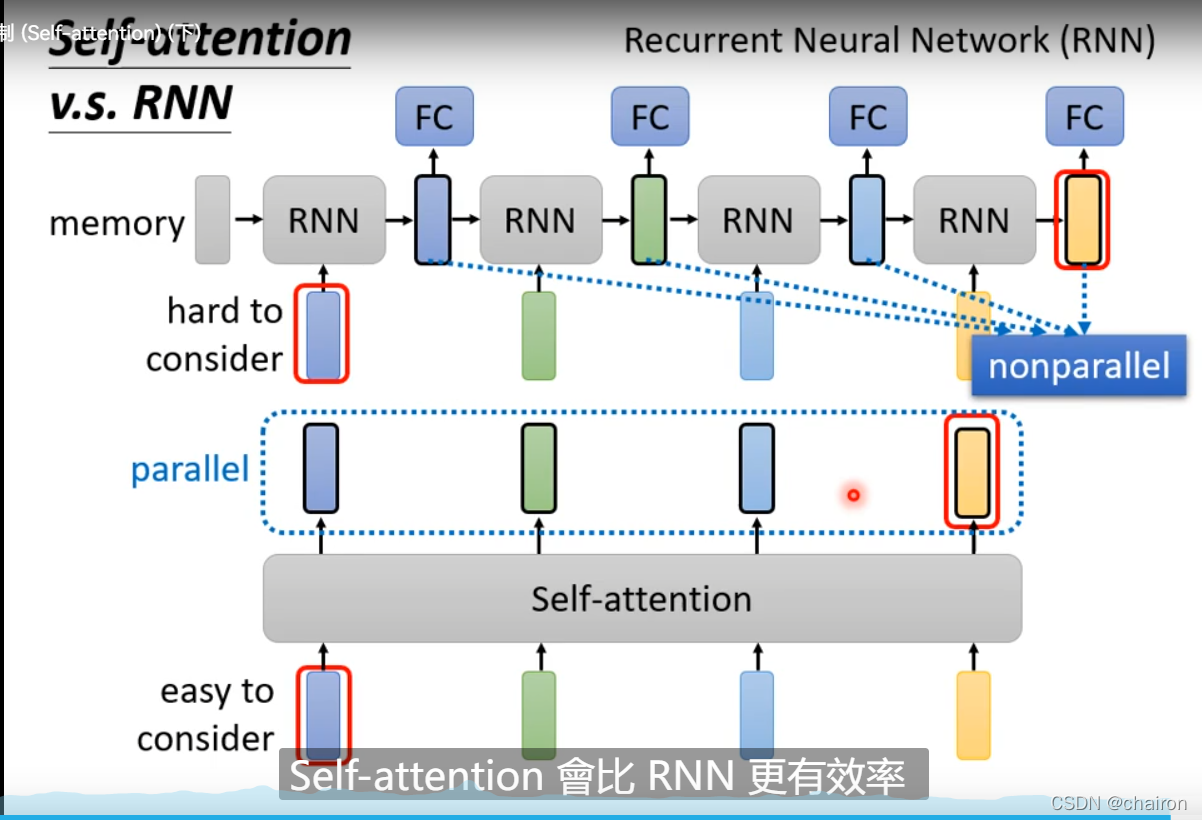
6. Self-atention VS RNN
- RNN也可以考虑全局信息(双向RNN),但是最右边(最后)的输出要考虑最左边(第一个)的输入,就需要把它一直存在memory里不能忘掉;不是并行的,是串行的
- Self-attention不存在这个问题,他的任意输入序列之间是无序的,并行的,“天涯若比邻”,比RNN块
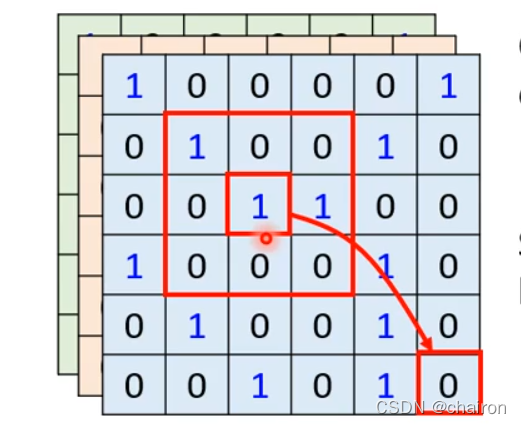
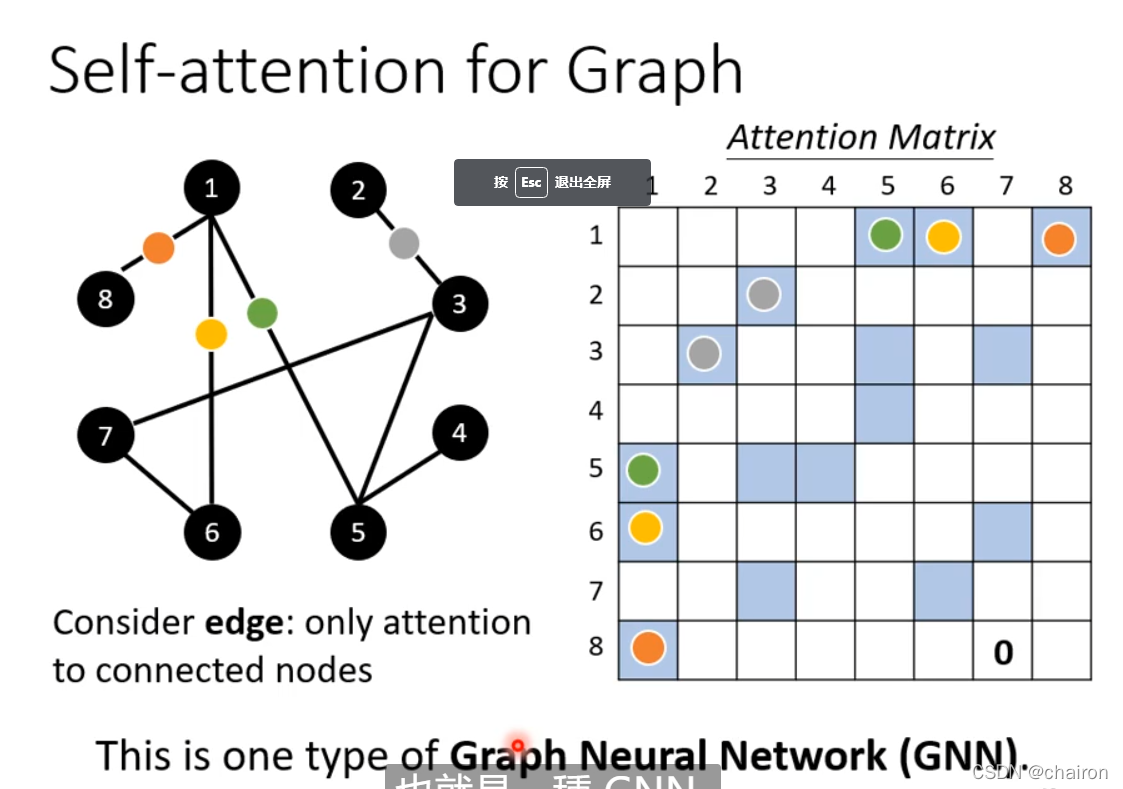
7. Self-attention for Graph
- 将Self-attention用在图上,可以只考虑相连的节点之间的attention

















 1060
1060

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









