









 本文介绍了计算机视觉中的形状匹配算法,包括三种实现方法:CV_CONTOURS_MATCH_I1、CV_CONTOURS_MATCH_I2 和 CV_CONTOURS_MATCH_I3,并详细解释了这些方法如何利用Huinvariants进行形状比较。
本文介绍了计算机视觉中的形状匹配算法,包括三种实现方法:CV_CONTOURS_MATCH_I1、CV_CONTOURS_MATCH_I2 和 CV_CONTOURS_MATCH_I3,并详细解释了这些方法如何利用Huinvariants进行形状比较。
计算机视觉中,目前有哪些成熟的匹配定位算法
这个链接涉及到模板匹配的实际问题, 高票答主提到的ESM, 结构特征ASM的, 我都是第一次看到. 即便是我之前在下面提到的ICP算法也没有实际去应用过,计算机视觉的道路任重而道远啊.
computer and machine vision
computer vision algorithms and applications,
加上对应opencv2 cookbook 涉及到的大部分算法
关于寻找shape特征(feature)的方法总结
Compares two shapes.
-
C++:
double
matchShapes
(InputArray
contour1, InputArray
contour2, int
method, double
parameter
)
-
Python:
cv2.
matchShapes
(contour1, contour2, method, parameter
) → retval
-
C:
double
cvMatchShapes
(const void*
object1, const void*
object2, int
method, double
parameter=0
)
-
Parameters: - object1 – First contour or grayscale image.
- object2 – Second contour or grayscale image.
- method – Comparison method: CV_CONTOURS_MATCH_I1 , CV_CONTOURS_MATCH_I2 orCV_CONTOURS_MATCH_I3 (see the details below).
- parameter – Method-specific parameter (not supported now).
The function compares two shapes. All three implemented methods use the Hu invariants (see HuMoments() ) as follows (  denotes object1,:math:B denotes object2 ):
denotes object1,:math:B denotes object2 ):
-
method=CV_CONTOURS_MATCH_I1
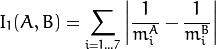
-
method=CV_CONTOURS_MATCH_I2
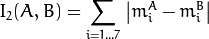
-
method=CV_CONTOURS_MATCH_I3
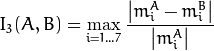
where
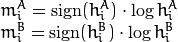
and 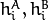 are the Hu moments of and
are the Hu moments of and  , respectively.
, respectively.

















 36万+
36万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









