



在某些特殊情况下,我们可能希望将kafka的消费者停止消费,比如说某台服务有问题,我们不想停止进程,但是又不想要进行消息消费;或者说数据库或者其他的中间件有点问题,需要临时紧急处理下,那可能需要先将消息暂停一下消费,等处理好后再将消息放进来。
想要停止消费,就要先获取消费者的container,在container里面有提供2个方式进行停止消费:stop()和pause();
使用方式如下:
@Autowired
private KafkaListenerEndpointRegistry kafkaListenerEndpointRegistry;
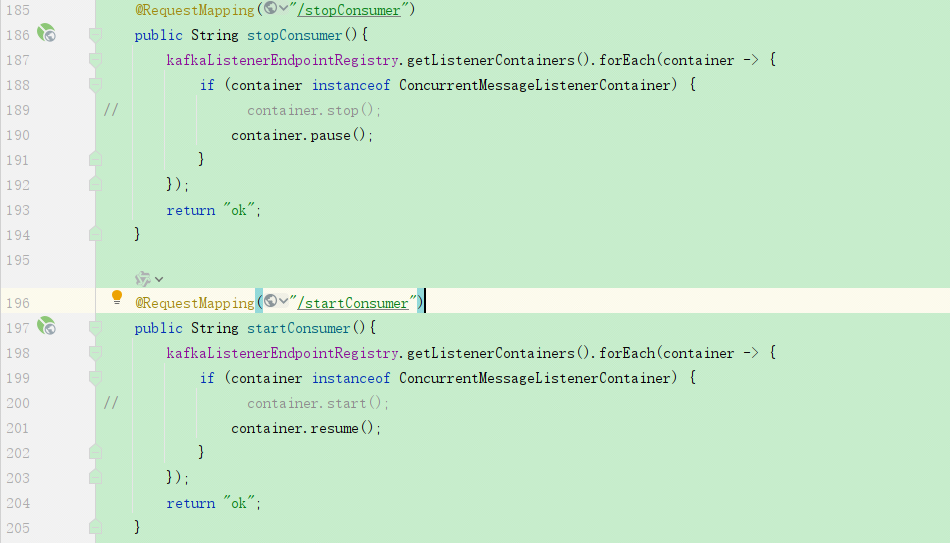
(上面截图中的使用是针对所有的消费者都进行暂停消费,其实还有一种指定消费者进行暂停消费:kafkaListenerEndpointRegistry.getListenerContainer("cftest_demo_topic1"),这里面的cftest_demo_topic1是在@KafkaListener注解中配置的id)
既然有stop()和pause()2种方式,那就扒一扒这2种方式的区别。
1、pause()
点到源码里去看,发现这个其实就是设置了一个标志位。

然后在kafka消费线程进行拉取消息的时候会判断该标志位,如果是暂停的话,就会针对消费者对应的分区不做处理:就是在创建请求的时候不会对分区做请求,以此来达到暂停消费的效果。
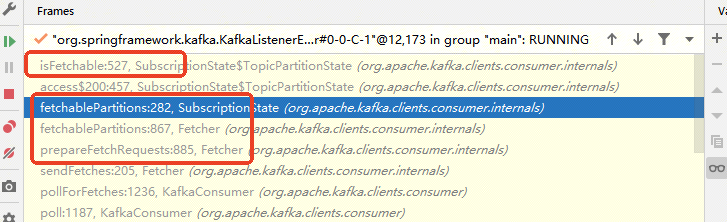
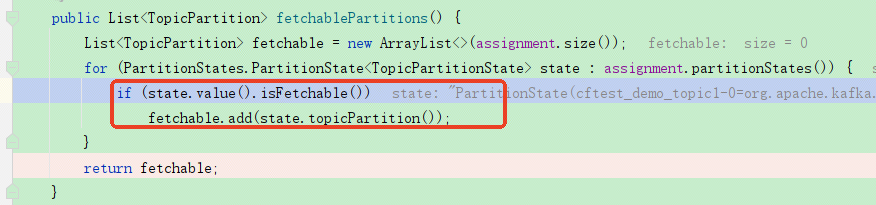

从上面代码可以判断,pause只是暂停了消息的消费,相关的其他的消费者与kafka服务端的心跳连接什么的,是不影响的。也就是消息都还只是堆积在kafka中,只有进行调用了resume()恢复后消息才会继续消费。
2、stop()
stop与pause不一样,这个是停止消费,是将消费者的container直接移除,相当于在kafka那将该消费者移除了,是会触发kafka的rebalance的。
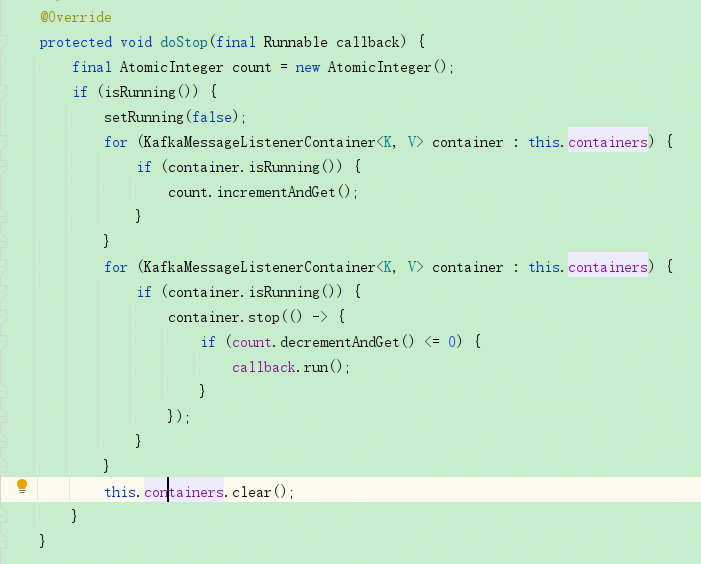
使用stop的话对应的消费者原来的分区会重新分配到其他的消费者,消息是还会消费的,只不过不是在本服务上消费。
总结一下:pause是暂停消费,消息会堆积在kafka中,不会触发rebalance,对应的恢复消费操作是resume()。stop是停止消费,相当于将该服务从kafka上下线掉,会触发rebalance,消息会分到其他的消费者进行消费。对应的启动消费操作是start()。如果是生产上某个中间件有问题,需要紧急修复处理,比如redis、mysql有问题,那么使用pause暂停消费,等修复后再进行resume。如果只是某台服务有问题,需要排查问题,建议可以使用stop()停止消费,将消息打到其他的没问题的服务上进行消费,等处理好后再进行start()。

















 617
617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









