



之前聊过druid连接池中的连接是怎么获取及回收的_获取德鲁伊连接池-优快云博客,今天聊聊springboot默认连接池Hikari的连接获取与回收。
既然要了解Hikari的相关连接信息,那就得找到Hikari中有关数据库连接操作的源码,怎么定位到这个源码,无非就是打印debug日志,从日志中找出相关的日志信息,再使用该信息进行全局扫描(或者直接正向的代码一步一步的F5,最终也是能找到的,这不过个人感觉这样的方式寻找的比较累)。我这边使用的是使用的是日志打印的信息“com.zaxxer.hikari.HikariDataSource.getConnection 123 - HikariPool-1 - Start completed”这行来进行定位,直接找到HikariDataSource源码,然后在getConnection上打上断点进行调试。具体的过程就不贴图展示,反正最后核心的代码无非就三处,一个是增加连接,一个是获取连接,一个是回收连接。代码都在ConcurrentBag类中,分别对应的代码是:
public void add(final T bagEntry)
{
if (closed) {
LOGGER.info("ConcurrentBag has been closed, ignoring add()");
throw new IllegalStateException("ConcurrentBag has been closed, ignoring add()");
}
sharedList.add(bagEntry);
// spin until a thread takes it or none are waiting
while (waiters.get() > 0 && !handoffQueue.offer(bagEntry)) {
yield();
}
}public T borrow(long timeout, final TimeUnit timeUnit) throws InterruptedException
{
// Try the thread-local list first
final List<Object> list = threadList.get();
for (int i = list.size() - 1; i >= 0; i--) {
final Object entry = list.remove(i);
@SuppressWarnings("unchecked")
final T bagEntry = weakThreadLocals ? ((WeakReference<T>) entry).get() : (T) entry;
if (bagEntry != null && bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
return bagEntry;
}
}
// Otherwise, scan the shared list ... then poll the handoff queue
final int waiting = waiters.incrementAndGet();
try {
for (T bagEntry : sharedList) {
if (bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
// If we may have stolen another waiter's connection, request another bag add.
if (waiting > 1) {
listener.addBagItem(waiting - 1);
}
return bagEntry;
}
}
listener.addBagItem(waiting);
timeout = timeUnit.toNanos(timeout);
do {
final long start = currentTime();
final T bagEntry = handoffQueue.poll(timeout, NANOSECONDS);
if (bagEntry == null || bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
return bagEntry;
}
timeout -= elapsedNanos(start);
} while (timeout > 10_000);
return null;
}
finally {
waiters.decrementAndGet();
}
}public void requite(final T bagEntry)
{
bagEntry.setState(STATE_NOT_IN_USE);
for (int i = 0; waiters.get() > 0; i++) {
if (bagEntry.getState() != STATE_NOT_IN_USE || handoffQueue.offer(bagEntry)) {
return;
}
else if ((i & 0xff) == 0xff) {
parkNanos(MICROSECONDS.toNanos(10));
}
else {
yield();
}
}
final List<Object> threadLocalList = threadList.get();
threadLocalList.add(weakThreadLocals ? new WeakReference<>(bagEntry) : bagEntry);
}核心代码中的核心属性数据类型:
private final CopyOnWriteArrayList sharedList;
private final ThreadLocal> threadList;
private final SynchronousQueue handoffQueue;
核心代码就差不多是上面那些,很简洁,我们来大致看下上面核心代码的逻辑:
1、新增连接:连接是先放入到sharedList中,然后看下有没有等待获取连接的线程,如果有的话,再往handoffQueue队列里面放入该连接。(新增连接的触发点有2个,一个是获取连接borrow里面,还有一个是在定时任务houseKeeperTask里面)
2、获取连接:先从threadList中看看当前线程有没有连接,如果有的话直接使用该连接,没有的话再从sharedList中获取连接,sharedList中再没获取到的话,就从handoffQueue获取连接,如果handoffQueue中没有连接的话,会进行等待一段超时时间(默认30s),如果在超时时间内还未获取到的话那就进行返回null。
3、回收连接:先是直接将连接的状态置为“未使用”,(注意,这个连接对象其实还是在sharedList中的,并没有从sharedList中移除,所以直接将状态置为“未使用”的话,其他线程在sharedList中是可以重新获取到的)然后再判断是否有等待线程,如果有的话就往handoffQueue放,如果没有等待线程的话就将该连接放入到threadList中。
好了,大致逻辑也清楚了,现在思考几个问题:为什么说Hikari比druid性能要高?为什么Hikari的核心代码中存储连接要高这么多的属性,又是sharedList,又是threadList,还有个handoffQueue,就不能像druid一样直接搞个数组来存连接?
一开始调代码的时候看到下面这这段代码:
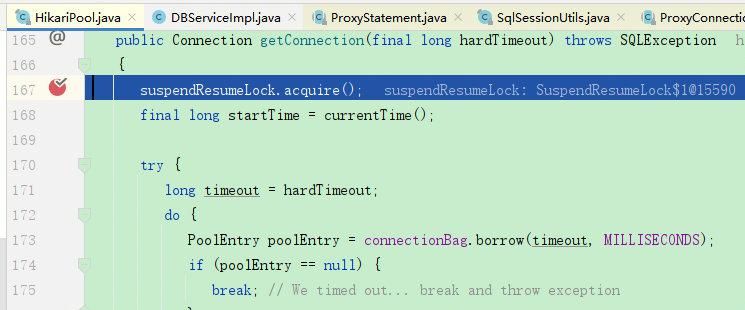
获取连接的时候一上来就获取个锁,当时就在想这一上来就搞个锁,connectionBag里面优化的再好应该也不会提升多少性能啊,怎么都说Hikari性能比druid高很多?后来发现我错怪Hikari了,这个获取锁的方法点进去是个空方法,也就是说默认的情况下,这里并没有锁:

(至于为什么这里要有这行代码,是为了另一种场景,这个以后再聊)
所以Hikari连接池是无锁的,个人觉得这一点是比druid连接池性能高的主要原因,也正是因为是无锁的,才会导致存储连接的时候有sharedList又有handoffQueue,因为当一个线程遍历了一遍sharedList的时候发现没有可用的连接后,这个线程可以尝试从handoffQueue中等待新增的连接或者其他线程释放的连接(因为新增连接或者回收连接的时候都会判断释放有等待线程,如果有的话会将连接放入handoffQueue中)。那为什么又要又个threadList?这个也是为了提高性能,从逻辑上来讲不要threadList也是可以的,但是有了这个后,性能又能更提高一些,想象一下当一个方法中有多个查询,第一个查询后释放连接,连接回收放入到了threadList中,然后第二个查询发现threadList中有连接,那是不是可以直接使用?这样就不需要再到sharedList再次遍历一遍了(因为遍历sharedList中的连接,每个连接都得进行一次cas操作)。
再思考下代码中的2个细节点:
1、threadList为什么设计成ThreadLocal<List<Object>>,而不是ThreadLocal<Object>?
2、Borrow方法中有个注释:
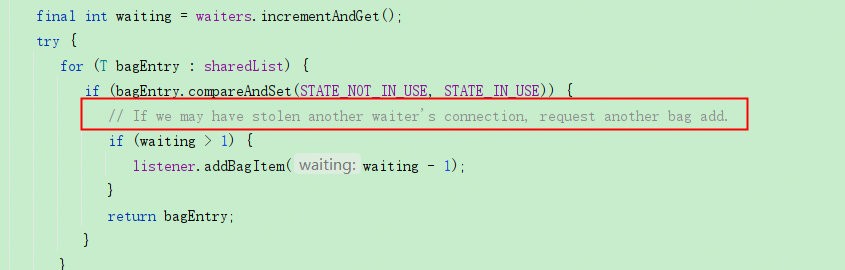
这个注释里为什么叫偷了其他等待线程的连接?什么情况下会偷其他线程的连接?
针对第一个问题,个人感觉应该是针对事务传播为Propagation.REQUIRES_NEW的情况,因为如果一个事务中嵌套了一个Propagation.REQUIRES_NEW事务,那这个嵌套的事务是要开启一个新的连接,这样的话一个线程就相当于对应了多个连接了,如果是使用ThreadLocal的话就会乱套了。
第二个问题:
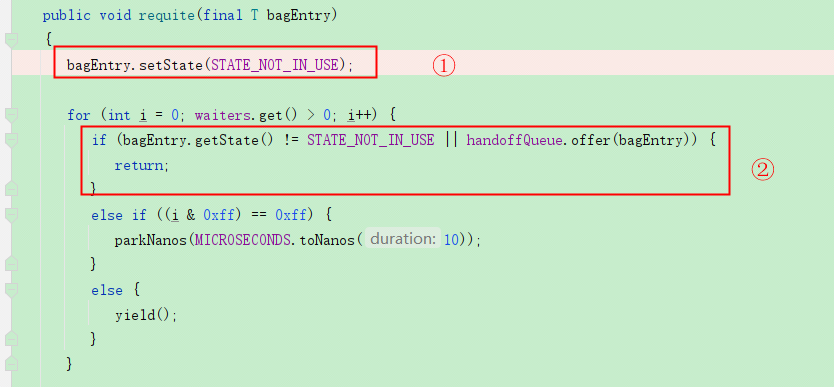
当有线程在等待连接时,waiters.get()大于0,正常来说其他线程释放的连接最好的情况是直接给到这个等待连接的线程(通过handoffQueue来交付这个连接),但是因为一开始就是将这个连接给置为“未使用”状态,而且前面说过这个连接对象其实还是在sharedList中的,所以就有可能当一个线程进来获取连接的时候,这个时候另一个线程正在释放连接,代码走完了上面第一步,第二步还未执行,这个连接就有可能被新来的线程给截胡了,然后等待连接的那个线程还要继续等待,这就是所谓的“stolen another waiter's connection”。
总结一下:
Hikari连接池性能卓越,主要归功于其无锁设计。该设计采用 sharedList 和 handoffQueue 来管理数据库连接的存储,并通过 threadList 进一步提升性能。

















 1435
1435

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









