







前言
回顾之前讲述了python语法编程 必修入门基础和网络编程,多线程/多进程/协程等方面的内容,后续讲到了数据库编程篇MySQL,Redis,MongoDB篇,和机器学习,全栈开发,数据分析,爬虫数据采集/自动化和抓包前面没看的也不用往前翻,系列文已经整理好了:
1.跟我一起从零开始学python(一)编程语法必修
2.跟我一起从零开始学python(二)网络编程
3.跟我一起从零开始学python(三)多线程/多进程/协程
4.跟我一起从零开始学python(四)数据库编程:MySQL数据库
5.跟我一起从零开始学python(五)数据库编程:Redis数据库
6.跟我一起从零开始学python(六)数据库编程:MongoDB数据库
7.跟我一起从零开始学python(七)机器学习
8.跟我一起从零开始学python(八)全栈开发
9.跟我一起从零开始学python(九)数据分析
10.跟我一起从零开始学python(十)Hadoop从零开始入门
11.跟我一起从零开始学python(十一)简述spark
12.跟我一起从零开始学python(十二)如何成为一名优秀的爬虫工程师
13.跟我一起从零开始学python(十三)爬虫工程师自动化和抓包

适用于零基础学习和进阶人群的python资源:
① 腾讯认证python完整项目实战教程笔记PDF
② 十几个大厂python面试专题PDF
③ python全套视频教程(零基础-高级进阶JS逆向)
④ 百个项目实战+源码+笔记
⑤ 编程语法-机器学习-全栈开发-数据分析-爬虫-APP逆向等全套项目+文档
本系列文根据以下学习路线展开讲述,由于内容较多,:
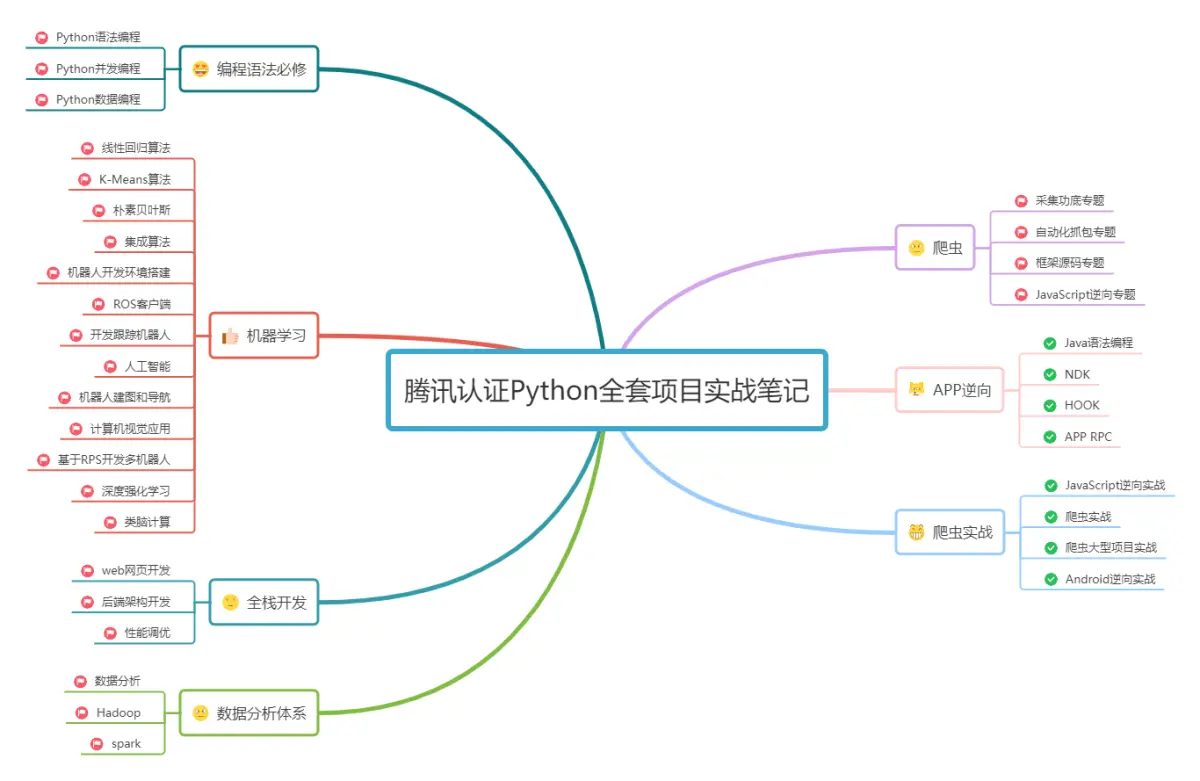
框架源码专题
一丶scrapy框架
一丶框架基本使用
Scrapy是一个用于爬取网站数据的Python框架。它提供了一套强大的工具和API,可以简化爬取、处理和存储数据的过程。下面我将详细解释Scrapy框架的基本使用。
1.安装Scrapy:
首先,确保已在Python环境中安装了pip(Python包管理器)。然后,可以使用以下命令在命令行中安装Scrapy:
pip install scrapy
2.创建Scrapy项目:
在命令行中,使用以下命令创建一个新的Scrapy项目:
scrapy startproject project_name
这将在当前目录下创建一个名为project_name的文件夹,其中包含Scrapy项目的基本结构。
3.定义爬虫:
在Scrapy项目中,爬虫是用于定义如何爬取特定网站的类。在项目的spiders目录中,可以创建一个新的Python文件来定义你的爬虫。下面是一个简单的示例:
import scrapy
class MySpider(scrapy.Spider):
name = 'example'
start_urls = ['http://www.example.com']
def parse(self, response):
# 在这里处理网页响应,提取数据等
pass
在上面的示例中,我们定义了一个名为MySpider的爬虫,指定了名称为example,并指定了起始URL为http://www.example.com。在parse方法中,你可以处理网页响应,并提取你需要
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 924
924

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









