




由于闪存存在不可靠因素,因此在系统层面的SSD软硬件上需要采取一些手段来解决闪存的不可靠问题。
5.3.1 ECC纠错
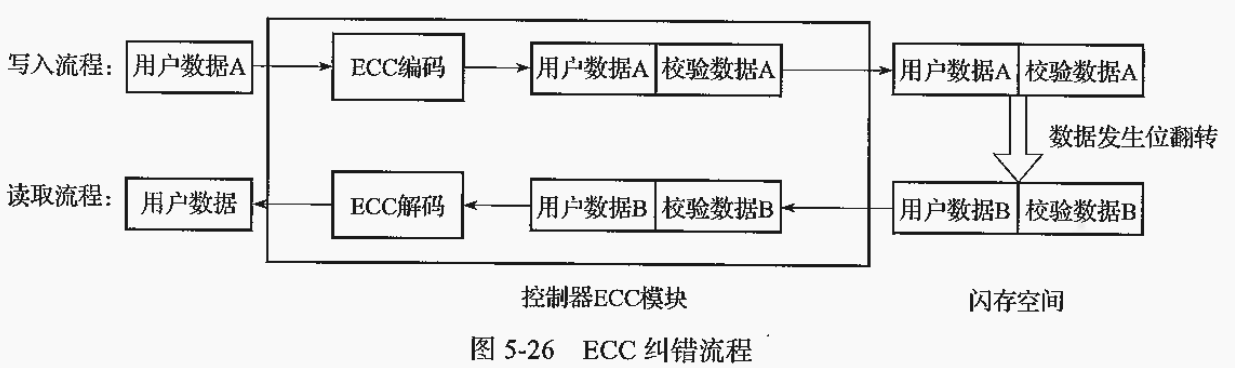
使用闪存ECC纠错引擎来纠正闪存数据出错位。
- 将数据A写入闪存前,先进行ECC编码,并把数据A+校验数据A一起写入闪存。
- 假如由于某些原因,闪存的数据发生了bit翻转,数据A变成了数据B。
- 读取用户数据的时候,数据B+校验数据B会经过纠错引擎,假如翻转的个数没有超过ECC的纠错能力,经过ECC纠错可以得得原始的数据A;假如翻转的个数超过了ECC的纠错能力,解码出来的将会是其他数据,此时假如没有其他纠错手段,用户数据A将会丢失。
主流的纠错算法有,BCH、LDPC,BCH只支持硬解码,LDPC不仅支持硬解码,还支持软解码,纠错能力更强。
5.3.2 重读
重读即为,当纠错算法通过ECC纠正不过来的时候,固件就采取改变施加在控制极的参考电压
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 807
807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









