




 本文深入探讨数据处理核心问题,解析数据位置与长度,详解寄存器与内存定位,介绍数据来源及寻址方式,总结数据长度指定方法,涵盖寄存器、Xptr与伪指令,为理解数据与内存处理提供全面指南。
本文深入探讨数据处理核心问题,解析数据位置与长度,详解寄存器与内存定位,介绍数据来源及寻址方式,总结数据长度指定方法,涵盖寄存器、Xptr与伪指令,为理解数据与内存处理提供全面指南。
至此,我们已经学习了七章和数据、内存相关的章节,此处我们需要进行一下总结。
首先提出标题中提到的数据处理的两个基本问题:
- 处理的数据在哪个地方?
- 要处理的数据有多长?
我们首先对寄存器进行一个分类:
- 寄存器(reg):ax,bx,cx,dx,sp,bp,si,di
- 段寄存器(sreg):ds,cs,ss,es
bx,si,di,bp
前面三个我们已经学习过了。
把这几个放在一起,显然是为了说内存定位。
这四个均可以单独定位内存,也可以两两组合,但是需要注意以下的写法是错的:
mov ax,[bx+bp]
mov ax,[si+di]
也就是说bx可以和si、di组合,bp也可以和si、di组合,但是bx和bp不能组合,si和di也不能组合。
那么bp是干什么的呢?
它对应的段地址是ss,而不是ds。
也可以看成栈的调用。
数据从哪来
这是我们的第一个问题的最源头。
实际上,数据的来源有三个:CPU内部、内存、端口
CPU内部和内存,是我们之前学过的。端口将在后面学习。
汇编中数据位置的表达
一共有三种:
立即数
即直接在汇编指令中的数据,也就是idata。
比如:
mov ax,1023H
这里的1023H就是一个立即数。
这些数据,在被执行前,是和指令一起放在指令缓冲器中。
寄存器
段地址加偏移地址
这两个是之前讲了很多的了,此处不再赘述。
寻址方式
这个我们之前说了很多,此处做一下总结:
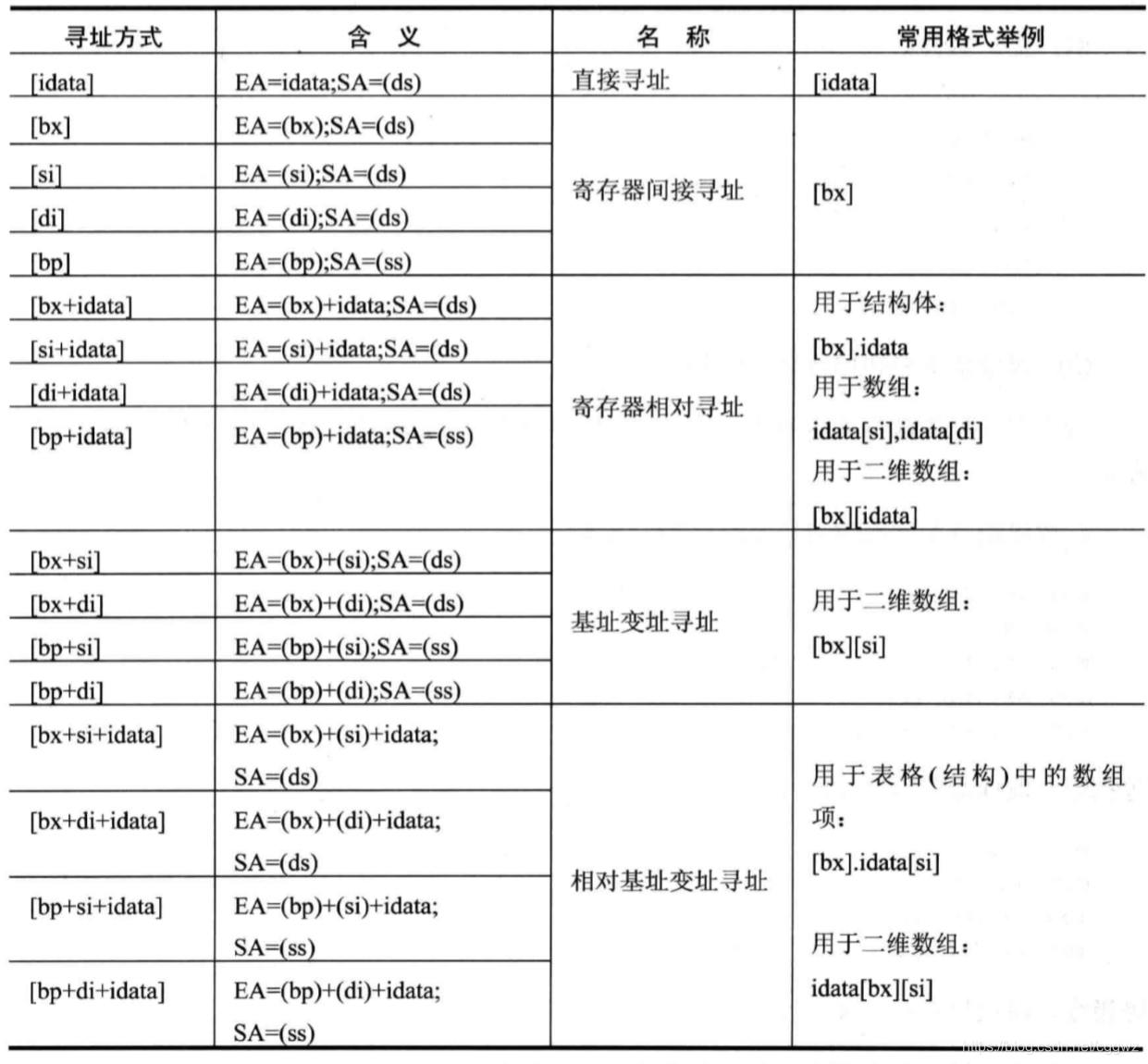
处理的数据有多长
前面我们相当于回答了第一个问题。
此处我们回答一下第二个问题。
我们知道,在我们之前的学习中,我们处理的基本数据有两种类型:word和byte
那么我们是如何通过指令来体现要处理的数据有多长呢?
通过寄存器名来指定
这个很好理解了。
如果是整个寄存器,如ax,bx,那么我们要处理的数据就是word。
那么如果是一半,比如:ah,al,bh,bl,那么我们要处理的数据就是byte
X ptr
这里的X可以是byte或word,可以用于在没用寄存器情况下指定大小。
举个例子:
mov byte ptr [bx],2
其他方法
有些指令是有默认的操作数据大小,比如push只操作word
div指令
div就是除法的意思。
那么,我们在使用div时,有三个值得注意的地方:
- 除数:有8位和16位两种,在一个reg或内存单元中
- 被除数:默认时ax或ax和dx。如果除数是8位,则被除数位16位,存放在ax;如果除数是16位,被除数是32位,存放在ax和dx中,高位在dx中,低位在ax中
- 结果:如果除数是8位,则al存储商,ah存储余数;如果除数是16位,ax存储商,dx存储余数
使用的格式如下:
div reg
div 内存单元
伪指令dd
dd的意思是define dword(double word),也就是定义双字,和之前db、dw类似。
双字也就是两个字的大小。
dup
这也是一个伪指令,是配合dw、db、dd使用的,用来重复填充。
使用方法如下:
db 重复次数 dup (重复的字节数据)
dw 重复次数 dup (重复的字数据)
dd 重复次数 dup (重复的双字数据)
我们举个例子:
db 3 dup (0,1,2)
db 0,1,2,0,1,2,0,1,2
这上面两个语句是等价的。
结束语
第八章是对前面的总结,到这里也就告一段落了。

















 1404
1404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









