




Diffusion Model(扩散模型)
Diffusion Model(扩散模型)是一种基于概率生成模型的深度学习方法,通过模拟数据从噪声中逐步去噪生成样本的过程,实现高质量数据生成。其核心思想借鉴了物理学中的扩散现象,结合神经网络实现复杂数据分布的学习与采样。以下从原理、特点、应用及挑战等方面展开介绍:
一、核心原理
- 前向扩散过程(Forward Process)
-
逐步加噪:对输入数据(如图像)逐步添加高斯噪声,使其逐渐转化为纯噪声。
-
马尔可夫链建模:每一步噪声添加仅依赖前一步状态,最终数据分布趋近于高斯分布。
-
数学表达:
-
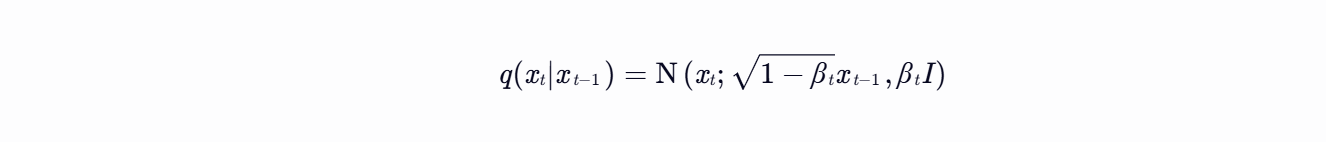
2. 反向去噪过程(Reverse Process)
-
噪声预测与去除:训练神经网络(如UNet)预测每一步的噪声分量,逐步去除噪声恢复数据。
-
参数化建模:反向过程建模为条件高斯分布:
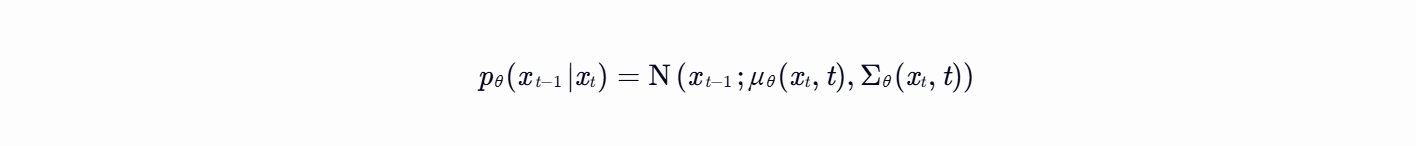
3. 训练目标
-
噪声预测损失:最小化预测噪声与真实噪声的均方误差(MSE):
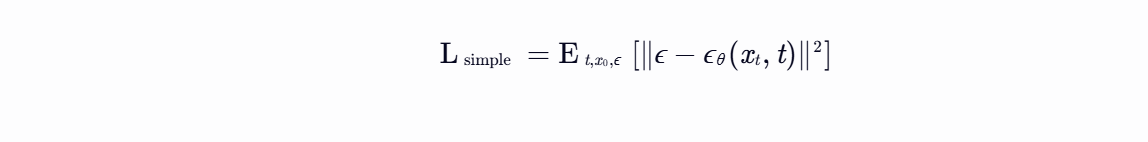
二、模型特点
- 生成质量高
- 通过多步去噪逐步细化样本,生成结果更接近真实数据分布,尤其在图像生成领域表现优异。
- 训练稳定性强
- 无需对抗训练,避免了GAN的模式崩溃、训练不稳定等问题。
- 理论支撑扎实
- 基于概率建模,具有较好的数学可解释性。
- 计算成本高
- 生成过程需多次迭代,推理速度较慢;训练时需处理高维数据,计算资源需求大。
三、典型应用
- 图像生成
- 生成高分辨率、多样化的图像,如Stable Diffusion、DALL-E 3等模型。
- 图像修复与超分辨率
- 通过去噪过程修复缺失区域或提升图像分辨率。
- 音频与视频生成
- 扩展至音频信号处理、视频帧生成等领域。
- 跨模态任务
- 结合文本条件生成图像(如Stab
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 808
808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









