




在上一次的教学中,我们详细讲解了如何使用 SDcomfyui 的图生视频功能。然而,事后我们收到了不少用户在后台的私信反馈,其中很多用户都提到这个功能的学习难度较大。考虑到大家的学习体验,这一次我们决定从最基础的部分开始教学,本次教学内容主要聚焦于最简单的文生图以及图生图工作流的搭建。好了,废话不多说,让我们直接开启本次教程之旅。
在此之前,有个观前提醒需要大家注意:本教程是建立在使用算网云提供的 sdcomfyui flux 镜像的基础之上的哦,平台的网址我们会在文末为大家呈现。
首先,我们要进入算网云的工作后台界面。这个界面就像是整个操作的控制中心,在这里,我们需要进行一系列关键的操作。我们要在众多选项中准确地选择 GPU,这一步就如同为我们后续的工作选择了一个强大的动力引擎。选择好 GPU 后,我们便可以部署我们所需要的镜像了。就是耐心等待容器实例的部署了。这是一个需要一些时间的过程我们要保持耐心。当看到部署状态显示为 “进行中” 时,这就意味着我们离成功又近了一步,此时我们可以点击 “Webui” 进入镜像。
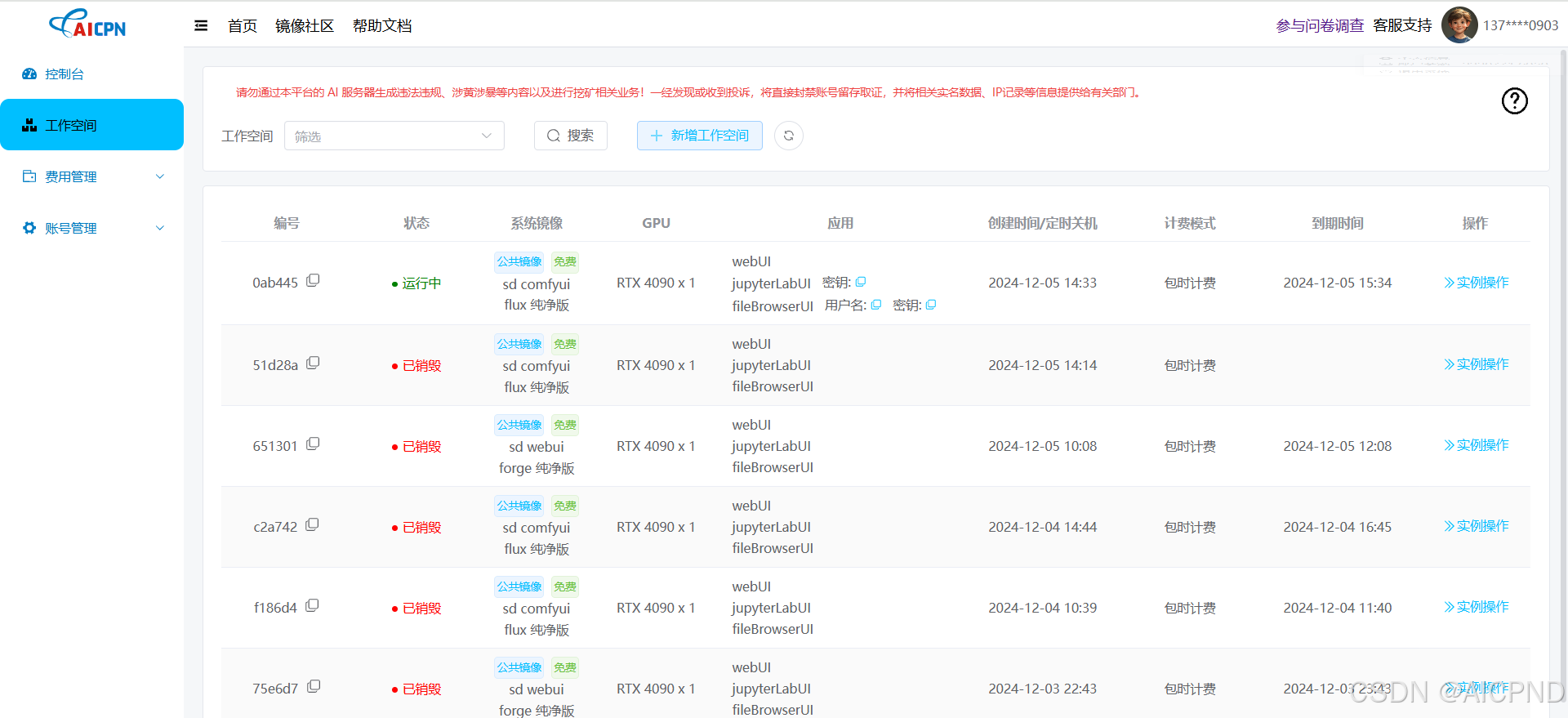
当我们成功进入镜像后,还有一些重要的准备工作要做。首先,我们要激活汉化插件。这个插件的激活就像是为我们打开了一扇方便之门,让我们在操作过程中可以更加顺畅地理解和使用各个功能,避免因语言障碍而产生的困扰。接下来,点击 “清除” 按钮,这一步操作是为了将默认的工作流删除掉。因为我们要重新建立新的工作流,以满足我们本次特定的文生图和图生图需求。
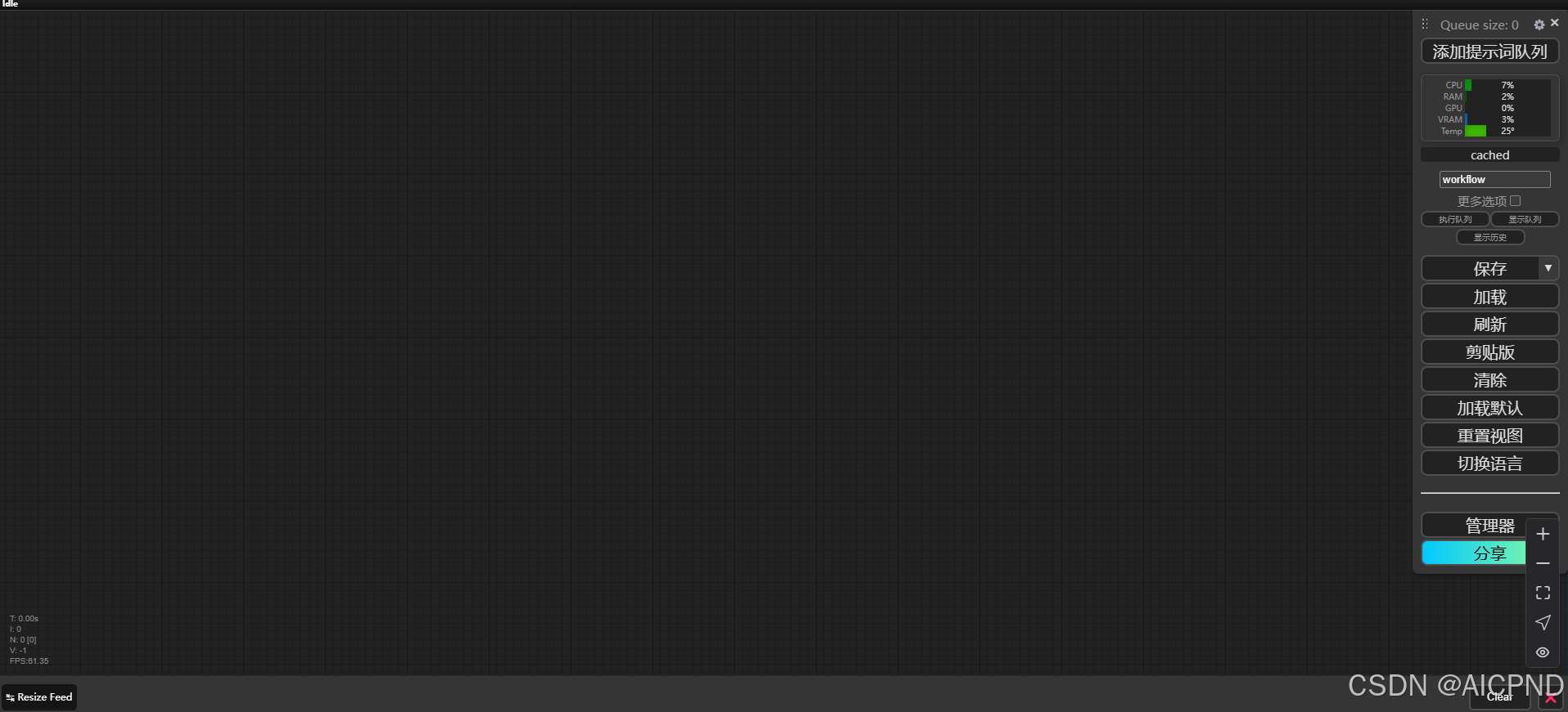
接下来,我们开始搭建文生图工作流。
首先,要新建一个 K 采样器,这个节点
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









