




 本文深入探讨了流式计算中的window机制,包括watermark的概念及其在处理乱序数据中的作用,详细介绍了滚动窗口、滑动窗口和会话窗口的原理和应用场景。同时,文章通过两个具体的业务案例展示了如何利用Flink SQL解决实时计算问题,讨论了增量计算和全量计算的差异,以及高级优化策略,如Mini-batch优化、倾斜优化和状态复用等。
本文深入探讨了流式计算中的window机制,包括watermark的概念及其在处理乱序数据中的作用,详细介绍了滚动窗口、滑动窗口和会话窗口的原理和应用场景。同时,文章通过两个具体的业务案例展示了如何利用Flink SQL解决实时计算问题,讨论了增量计算和全量计算的差异,以及高级优化策略,如Mini-batch优化、倾斜优化和状态复用等。
一、摘要
- 概述流式计算跟批计算,以及实时数仓和离线数仓的区别;引出流式计算中的window计算定义以及挑战
- 介绍实时计算中的Watermark概念,以及如何产生、传递,还有一些典型的生产实践中遇到的问题
- 介绍三种最基本的window类型,以及他们的实现原理;同时会结合业务场景介绍一些高级优化的功能和原理
- 结合两个真实业务场景的需求,讲解window是如何解决实际生产问题的(字节Flink使用量峰值90亿QPS)
QPS:全名 Queries Per Second,意思是“每秒查询率”,是一台服务器每秒能够响应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准
二、概述流式计算机制
简述流式计算的基本概念,与批式计算相比的难点和挑战
数据价值:实时性越高,数据价值越高
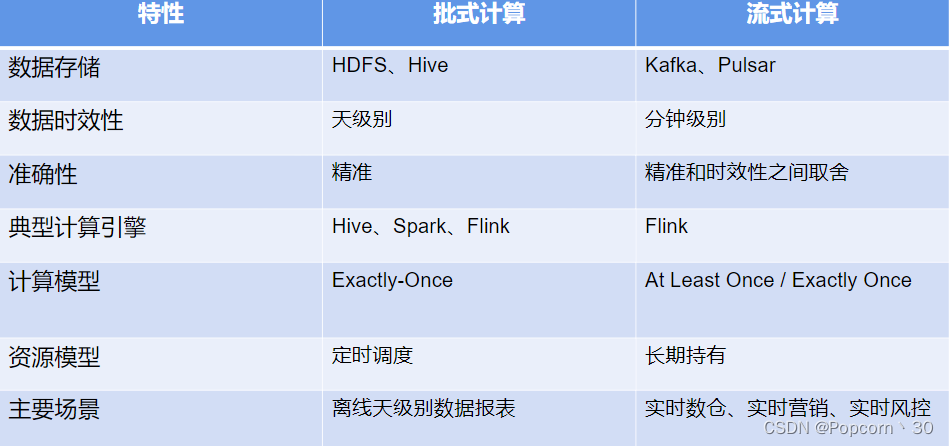
2.1批处理
批处理模型典型的数仓架构为T+1架构,即数据计算时天级别的,当天只能看到前一天的计算结果
通常使用的计算引擎为Hive或者Spark等。计算的时候,数据是完全ready的,输入和输出都是确定性的
2.2实时处理
实时计算:处理时间窗口
数据实时流动,实时计算,窗口结束直接发送结果,不需要周期调度任务。
处理时间(Processing time):数据在流式计算系统中真正处理时所在机器的当前时间。
处理时间这是在系统中观察事件的时间
事件时间(Event time):数据产生的时间,比如客户端、传感器、后端代码等上报数据时的时间。
事件时间这是事件实际发生的时间

实时计算:事件时间窗口(传入,运算,到输出时间总和)
数据实时进入到真实事件发生的窗口中进行计算,可以有效的处理数据延迟和乱序。
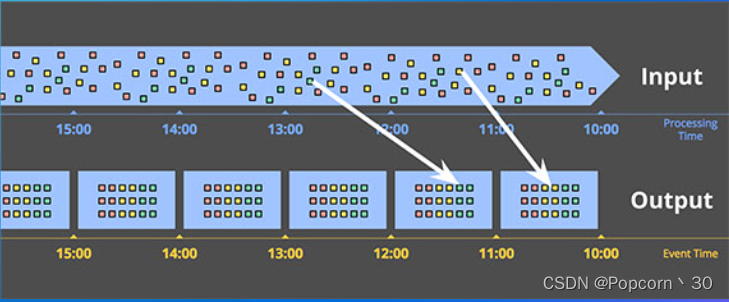
窗口真实结束时间(延迟与乱序)衡量:watermark
在数据中插入—些watermark,来表示当前的真实时间。
在数据存在乱序的时候,watermark就比较重要了,它可以用来在乱序容忍和实时性之间做一个平衡。
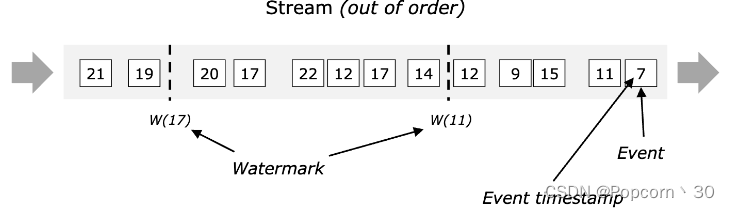
三、watermark(水印)
Watermark的含义、生成方法、传递机制,以及—些典型场景的问题和优化
概念:表示系统认为的当前真实的事件时间
3.1产生watermark
可以通过Watermark Generator 来生成
一般是从数据的事件时间来产生,产生策略可以灵活多样,最常见的包括使用当前事件时间的时
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1843
1843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









