




 本文介绍了Apache Flink如何实现Exactly-Once语义,详细阐述了数据流和动态表的概念,状态快照与恢复机制,以及端到端的Exactly-once实现,包括两阶段提交协议在Flink中的应用。此外,还探讨了Flink在账单计算服务中的使用,展示了其在处理数据一致性上的优势。
本文介绍了Apache Flink如何实现Exactly-Once语义,详细阐述了数据流和动态表的概念,状态快照与恢复机制,以及端到端的Exactly-once实现,包括两阶段提交协议在Flink中的应用。此外,还探讨了Flink在账单计算服务中的使用,展示了其在处理数据一致性上的优势。
一、内容介绍
数据流和动态表
- Stream: 数据流
- Dynamic Table: 动态表
- Continuous Queries: 连续查询
- Append-only Stream: Append-only 流(只有 INSERT 消息)
- Retract Stream: Retract 流(同时包含 INSERT 消息和 DELETE 消息)
- Upsert Stream: Upsert 流(同时包含 UPSERT 消息和 DELETE 消息)
- Changelog: 包含 INSERT/UPDATE/DELETE 等的数据流
- State: 计算处理逻辑的状态
Exactly-Once 和 Checkpoint
- Application Consistency Guarantees: 作业一致性保证
- At-most-once:每条数据消费至多一次(出现故障啥也不做)
- At-least-once:每条数据消费至少一次(可能存在重复消费)
- Exactly-once: 每条数据都被消费且仅被消费一次(仿佛故障从未发生)
- Checkpoint: Flink 实现各个计算逻辑状态快照算法,也可指一次状态快照
- Checkpoint barrier: 用于标识状态快照的制作,也将数据划分成不同的消费区间
- Checkpoint Alignment: 等待多个上游的Checkpoint barrier到达的现象
- JobManager: 负责协调和管理 Checkpoint
端到端 Exactly-Once 实现
- Two-phase commit protocol: 两阶段提交协议
- Transaction: 一系列保证原子性操作的集合,即操作同时执行或者都不执行
- Kafka: 消息中间件
- State Backend: 用于管理和保存状态到远端可靠存储
Flink 案例讲解
- Deduplication:去重,在 state 保留的时间内对重复消息进行去重
- Aggregation:聚合操作,比如求和、求最大值等
二、数据流和动态表
如何在数据流上执行SQL语句,说明流式处理中状态的概念
简介:动态表是数据流的SQL表达
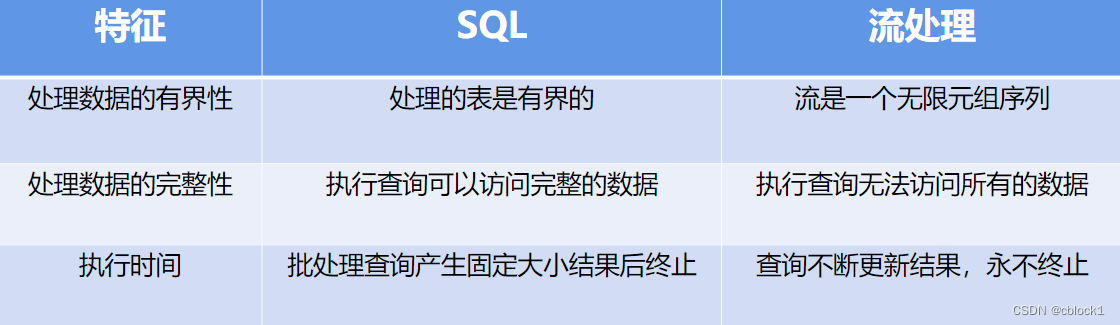
2.1数据流和动态表转换

- Stream: 数据流
- Dynamic Table: 动态表
- Continuous Queries: 连续查询
- State 状态
流到动态表
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









