



 本文深入探讨了大数据处理中的Shuffle阶段,从MapReduce的Shuffle概述开始,详细介绍了Spark中的Shuffle算子,如repartition、groupBy等,并讨论了Shuffle的实现历程,包括Hash Shuffle、Sort Shuffle和TungstenSortShuffle的优缺点。接着,文章阐述了Shuffle过程,包括写数据、读数据以及优化技术,如Zero Copy和Netty Zero Copy。最后,提到了Push Shuffle的必要性和Magnet实现原理,以提高性能和稳定性。
本文深入探讨了大数据处理中的Shuffle阶段,从MapReduce的Shuffle概述开始,详细介绍了Spark中的Shuffle算子,如repartition、groupBy等,并讨论了Shuffle的实现历程,包括Hash Shuffle、Sort Shuffle和TungstenSortShuffle的优缺点。接着,文章阐述了Shuffle过程,包括写数据、读数据以及优化技术,如Zero Copy和Netty Zero Copy。最后,提到了Push Shuffle的必要性和Magnet实现原理,以提高性能和稳定性。
01.Shuffle概述
MapReduce概述
·2004年,谷歌发布了《MapReduce:Simplified Data Processing on Large Clusters》论文
·在开源实现的MapReduce中,存在Map、Shuffle、Reduce三个阶段。
·Map阶段,是在单机上进行的针对一小块数据的计算过程,简单来说呢,就是按照给定的方法进行筛选分类;
·Shuffle 阶段,在map阶段的基础上,进行数据移动,为后续的reduce阶段做准备,也就是说,map阶段将几个小块数据分类完成后,shuffle将同类型的数据进行合并;
·Reduce阶段,对移动后的数据进行处理,依然是在单机上处理一小份数据,举个例子,对Shuffle得到的合并后的数据进行count,得到sum值。
Shuffle对性能非常重要体现在以下几个方面:
·MR次网络连接--每一个reduce都要访问所有的map来获取对应的数据,同样带来的还有等次的网络请求
·大量的数据移动--MR次数据移动
·数据丢失风险--移动和计算的过程中,存在丢失的风险
·可能存在大量的排序操作
·大量的数据序列化、反序列化操作--消耗大量cpu
·数据压缩--在存储大量数据过程中,压缩与解压缩也会占用大量CPU
02.Shuffle算子
- 常见的触发shuffle的算子
- repartition
- coalesce、repartition
- ByKey
- groupByKey、reduceByKey、aggregateByKey、combineByKey、sortByKeysortBy
- Join
- cogroup、join
- Distinct
- distinct
- repartition
tip : distinct算子可以看作特殊的bykey算子
Spark中对shuffle的抽象 - 宽依赖、窄依赖
窄依赖: 父RDD的每个分片至多被子RDD中的一个分片所依赖
宽依赖: 父RDD中的分片可能被子RDD中的多个分片所依赖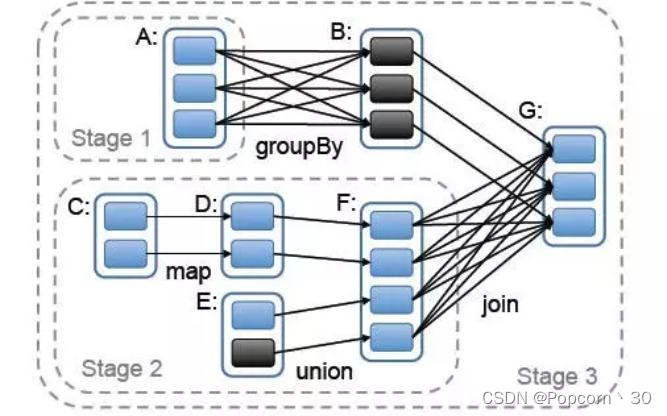
- 算子使用例子
val text = sc.textFile("mytextfile.txt")
val counts = text
.flatMap(line => line.split(" "))
.map(word => (word,1))
.reduceByKey(_+_)
counts.collect
-
Shuffle Dependency
- 创建会产生shuffle的RDD时,RDD会创建Shuffle Dependency来描述Shuffle相关的信息
- 构造函数
- A single key-value pair RDD, i.e. RDD[Product2[K, V]],
- Partitioner (available as partitioner property),
- Serializer,
- Optional key ordering (of Scala’s scala.math.Ordering type),
- Optional Aggregator,
- mapSideCombine flag which is disabled (i.e. false) by default.
-
Partitioner
- 用来将record映射到具体的partition的方法
- 接口
- numberPartitions
- getPartition
- Aggregator
- 在map侧合并部分record的函数
- 接口
- createCombiner:只有一个value的时候初始化的方法
- mergeValue:合并一个value到Aggregator中
- mergeCombiners:合并两个Aggregator
03.Shuffle过程
Shuffle实现的发展历程
spark中的shuffle变迁过程
- HashShuffle
- 优点:不需要排序
- 缺点:打开,创建的文件过多
- SortShuffle
- 优点:打开的文件少、支持map-side combine
- 缺点:需要排序
- TungstenSortShuffle
- 优点:更快的排序效率,更高的内存利用效率
- 缺点:不支持map-side combine
Hash Shuffle - 写数据
每个partition会映射到一个独立的文件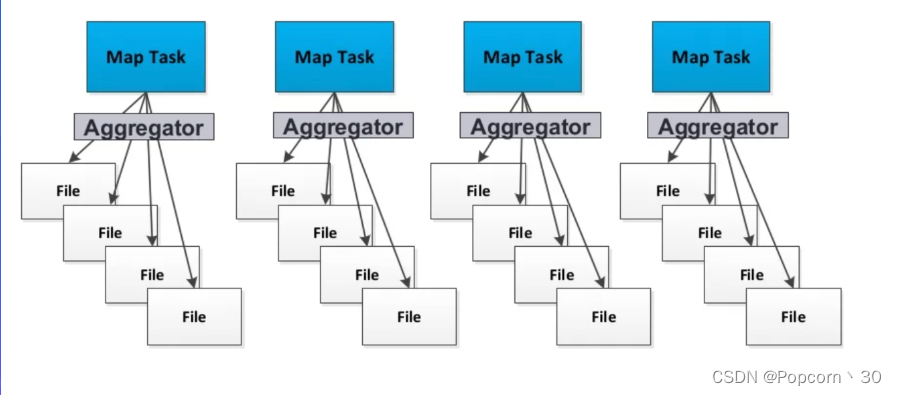
Hash Shuffle - 写数据优化
每个partition会映射到一个文件片段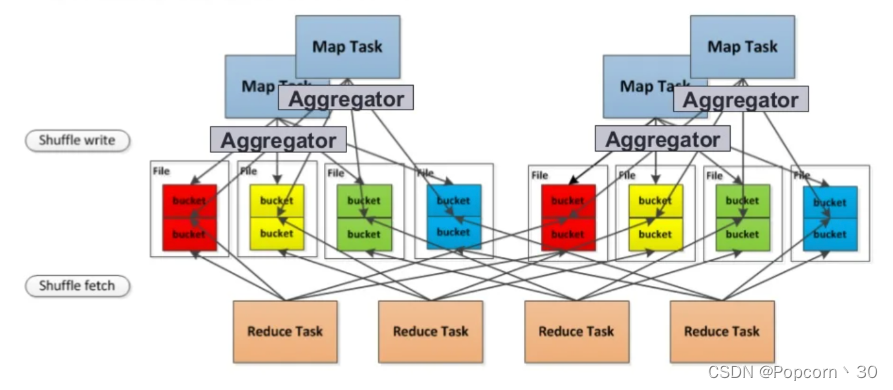
Sort shuffle:写数据
每个task生成一个包含所有partiton数据的文件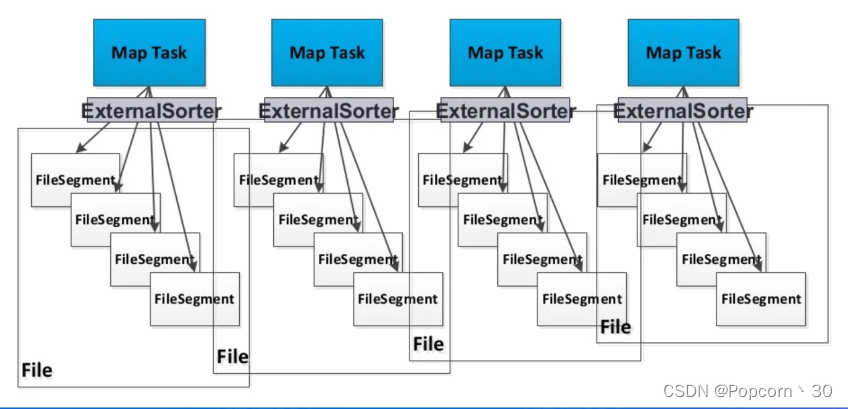
Shuffle - 读数据
每个reduce task分别获取所有map task生成的属于自己的片段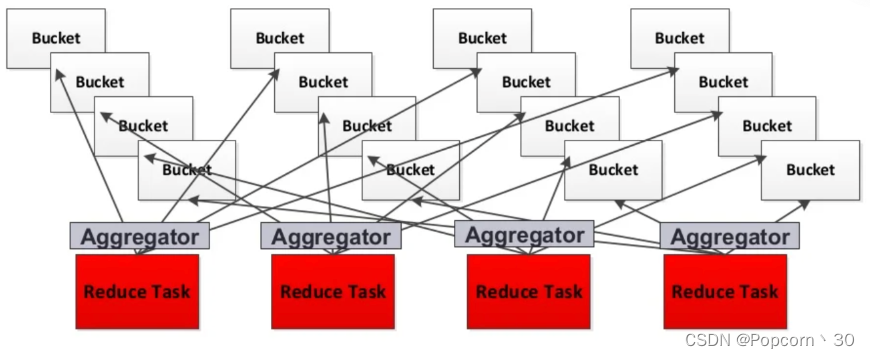
Shuffle过程的触发流程示例
val text = sc.textFile("mytextfile.txt")
val counts = text
.flatMap(line => line.split(""))
.map(word => (word,1))
.reduceByKey(_+_)
counts.collect
Shuffle Handle的创建
Register Shuffle时做的最重要的事情是根据不同条件创建不同的shuffle Handle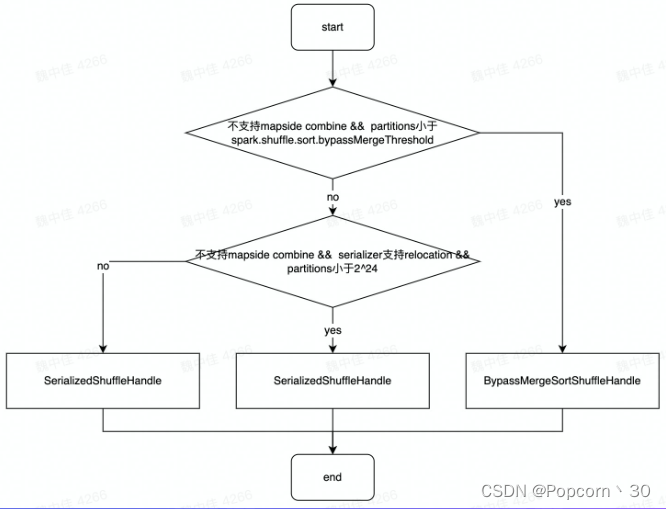
Shuffle Handle与Shuffle Writer的对应关系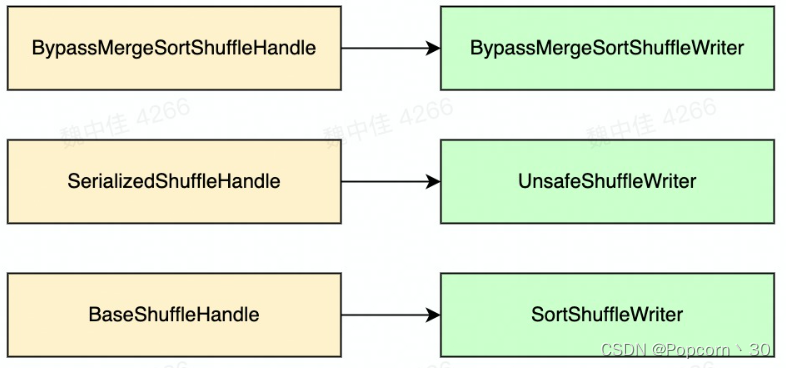
Writer实现 - BypassMergeShuffleWriter
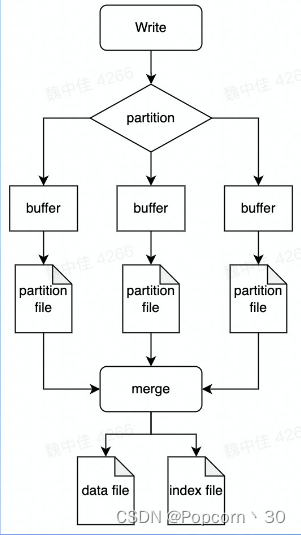
特点:
- 不需要排序,节省时间
- 写操作的时候会打开大量文件
- 类似于Hash Shuffle
Writer实现- UnsafeShuffle Writer
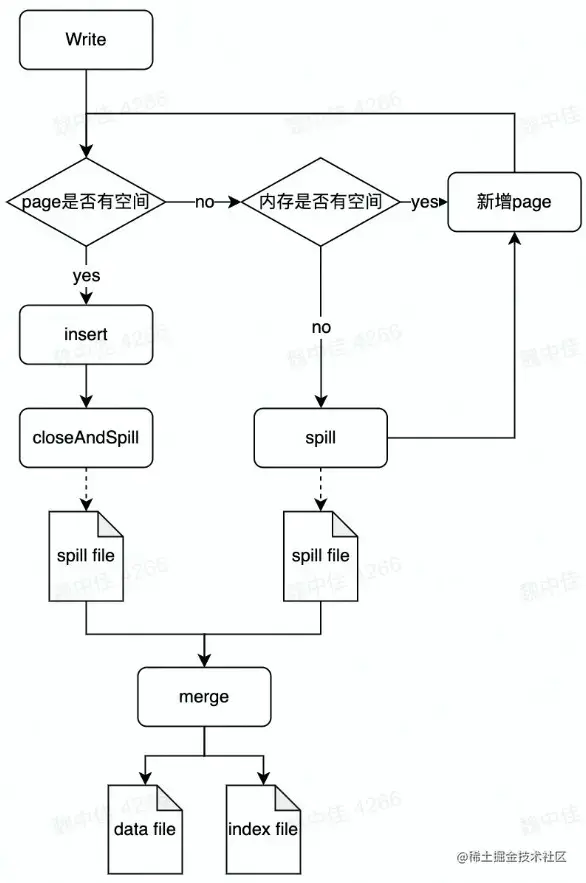
特点:
- 使用类似内存页储存序列化数据
- 数据写入后不再反序列化
Writer FIЛ - SortShuffle Writer
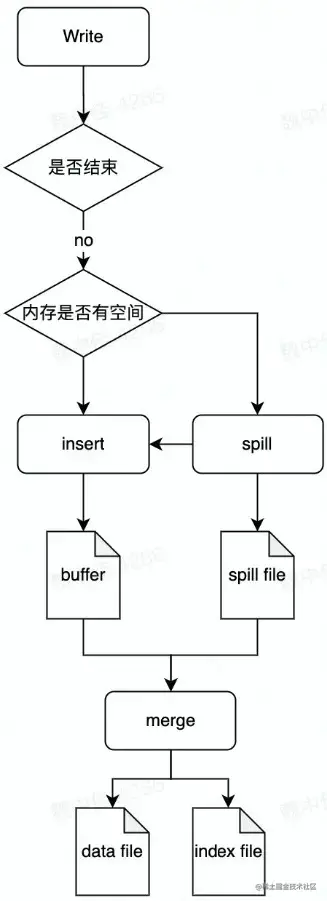
特点:
- 支持combine
- 需要combine时,使用PartitionedAppendOnlyMap,本质是个HashTable
- 不需要combine时PartitionedPairBuffer本质是个array
Reader实现 - 网络时序图
- 使用基于netty的网络通信框架
- 位置信息记录在MapOutputTracker中
- 主要会发送两种类型的请求
- OpenBlocks请求
- Chunk清求或Stream请求
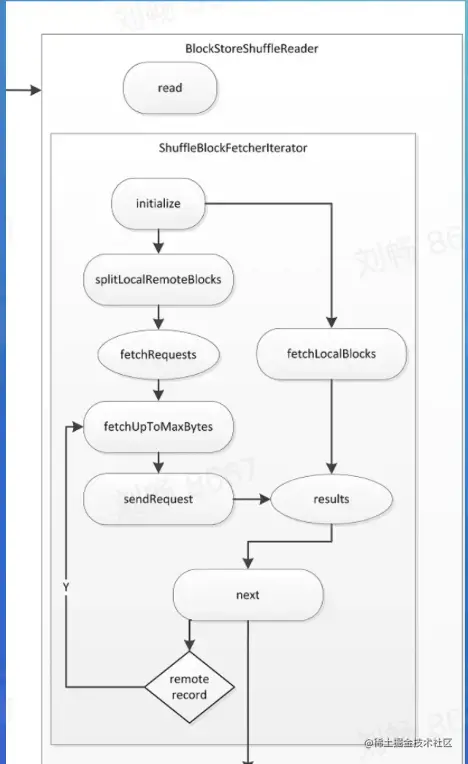
Reader 实现 - ShuffleBlockFetchIterator
- 区分local和remote节省网络消耗
- 防止 OOM
- maxBytesInFlight
- maxReqsInFlight
- maxBlocksInFlightPer Address
- maxReqSizeShuffleToMem
- maxAttemptsOnNettyOOM
Read 实现 - External Shuffle Service
ESS作为一个存在于每个节点上的agent为所有Shuffle Reader提供服务,从而优化了Spark作业的资源利用率,MapTask在运行结束后可以正常退出。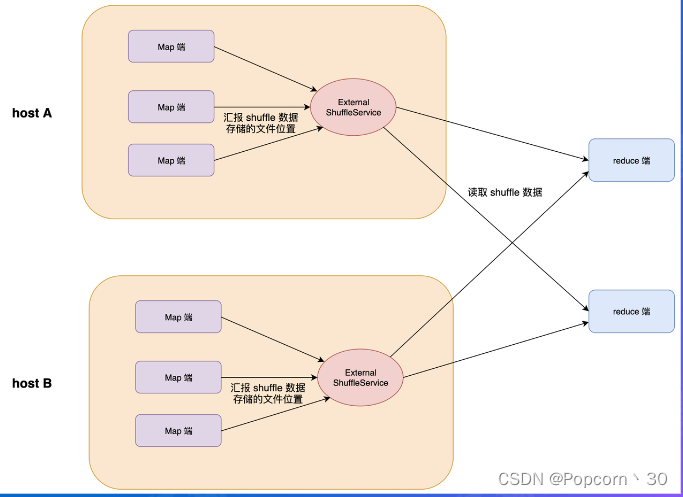
Shuffle优化使用的技术Zero Copy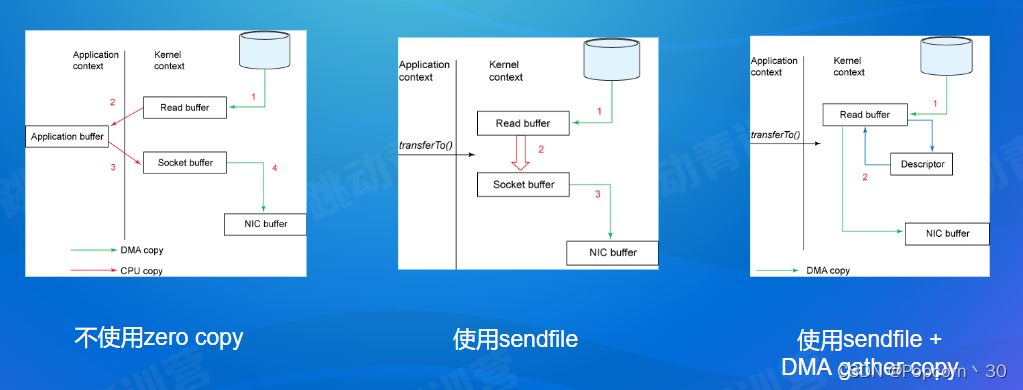
Shuffle优化使用的技术: Netty Zero Copy
- 可堆外内存,避免JVM堆内存到堆外内存的数据拷贝。
- CompositeByteBuf 、Unpooled. wrappedBuffer、ByteBuf.slice ,可以合并、包装、切分数组,避免发生内存拷贝
- Netty 使用FileRegion实现文件传输,FileRegion 底层封装了FileChannel#transferTo() 方法,可以将文件缓冲区的数据直接传输到目标Channel,避免内核缓冲区和用户态缓冲区之间的数据拷贝
常见问题
- 数据存储在本地磁盘,没有备份
- IO并发:大量RPC请求(M*R)
- IO吞吐:随机读、写放大(3X)
- GC频繁,影响NodeManager
04.Push Shuffle
为什么需要Push Shuffle ?
▪️ Avg IO size太小,造成了大量的随机IO,严重影响磁盘的吞吐
▪️ MR次读请求,造成大量的网络连接,影响稳定性
Magnet实现原理
- Spark driver组件,协调整体的shuffle操作
- map任务的shuffle writer过程完成后,增加了-个额外的操作push. merge,将数据复制一份推到远程shuffle服务上
- magnet shuffle service是一个强化版的ESS。将隶属于同一个shuffle partition的block,会在远程传输到magnet后被merge到一个文件中
- reduce任务从magnet shuffle service接收合并好的shuffle数据
- bitmap:存储已merge的mapper id,防止重复merge
- position offset:如果本次block没有正常merge,可以恢复到上一个block的位置
- currentMapld:标识当前正在append的block,保证不同mapper 的block能依次append

















 2721
2721

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









