







pytorch作为目前最火爆的深度学习框架,卷积函数无疑是最为常用的,它具有很强的特征提取功能,与通信中的卷积形式上不太一样,深度学习中的卷积实质上是对矩阵进行互运算
卷积核,在网络中起到将图像从像素空间映射到特征空间的作用,可认为是一个映射函数,像素空间中的值经过卷积核后得到响应值,在特征提取网络中,基本都是使用最大池化来选择最大响应值进入下一层继续卷积,其余响应值低的都进入待定。也就是说,我们认定只有响应值大的才会对最终的识别任务起作用。
Conv2d(in_channels, out_channels, kernel_size, stride=1,padding=0, dilation=1, groups=1,bias=True, padding_mode=‘zeros’)
in_channels:输入的通道数
out_channels: 输出的通道数
kernel_size:卷积核的大小,整数,代表卷积核大小为kernel_size*kernel_size,如果是元组:如(2,3),代表卷积核的高和宽为2和3
(前三项是必填项)
stride:kernel移动的步长,默认是1
padding: 设置在输入外层填充0,默认不填充, 若值为1,在上下左右各填充一层0
当然也可以使用元组定义在高和宽的不同填充数,8×8 经过(2,3)后大小为12×14
12 = 8 + 2 * 2
dilation:这个参数决定了是否采用空洞卷积,默认为1(不采用)
groups:分组卷积
bias: 是否将一个 学习到的 bias 增加输出中,默认是 True
padding_mode : 字符串类型,接收的字符串只有 “zeros” 和 “circular”。
简单使用
import torch
import numpy as np
X = torch.randn([16,3,64,64])#输入的格式为(b,c_in,h,w)
conv2 = torch.nn.Conv2d(3,64,3,stride=1,padding= 0)
Y = conv2(X)#输出的格式为(b,c_out,h,w)
Y.shape
torch.Size([16, 64, 62, 62])
conv2.weight.data.shape#查看模型的权重
torch.Size([64, 3, 3, 3])
以下参考D2L


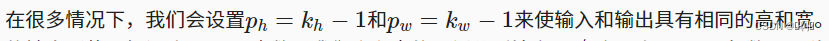
当stride = 1时,默认padding = 0, 这样每次卷积后输出的高宽都减少2, 使用padding = 1可保持输入输出形状一致。
stride

import torch
import numpy as np
X = torch.randn([16,3,64,64])
conv2 = torch.nn.Conv2d(3,64,kernel_size=3, padding=1, stride=2)
Y = conv2(X)
print(Y.shape)
torch.Size([16, 64, 32, 32])



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









