







-
bottleneck
将信息压缩再放大的神经网络结构,可以有效降低模型参数量
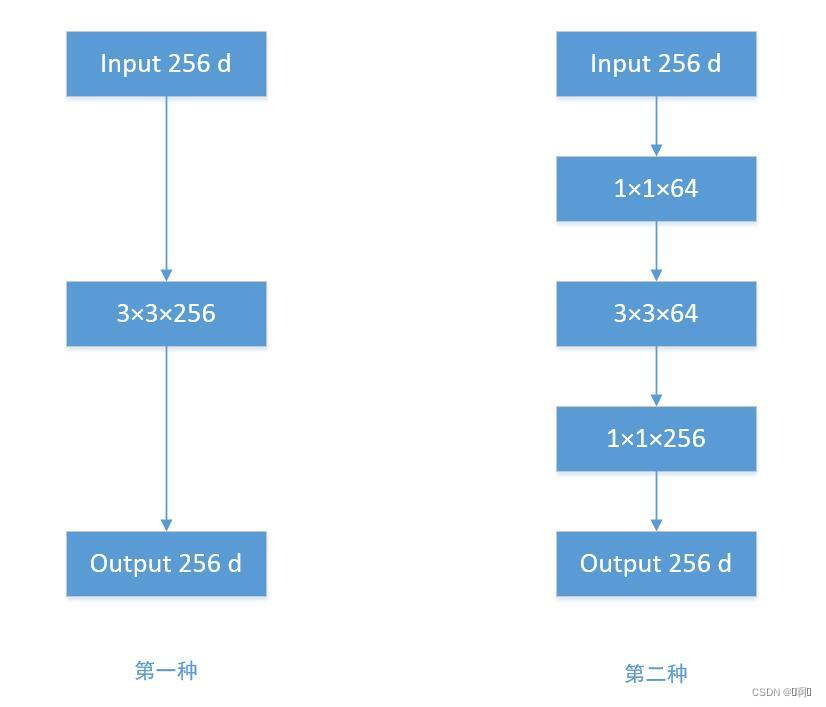
-
左边是对输入进行常规卷积,右边是对输入先进行PW(Pointwise_Convolution,可参考我的上一篇博客),之后用小卷积核进行特征提取,最后同样用PW升维。两边的输出形状一致,但是右边具有更小的参数量
-
残差网络加上bottleneck,可以训练更小的参数量、更深的模型
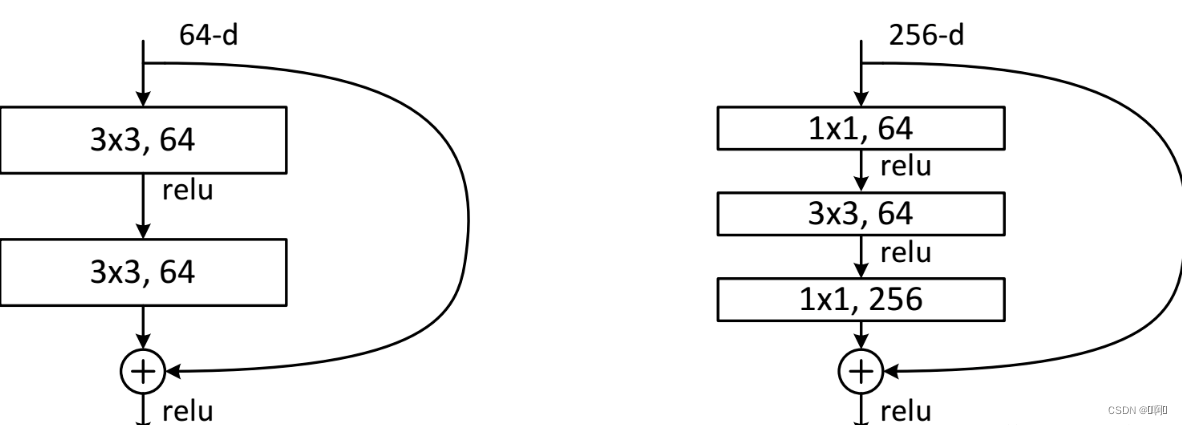
-
其中两个1X1fliter分别用于降低和升高特征维度,主要目的是为了减少参数的数量,从而减少计算量,且在降维之后可以更加有效、直观地进行数据的训练和特征提取,对比如下图所示。
- FFN —
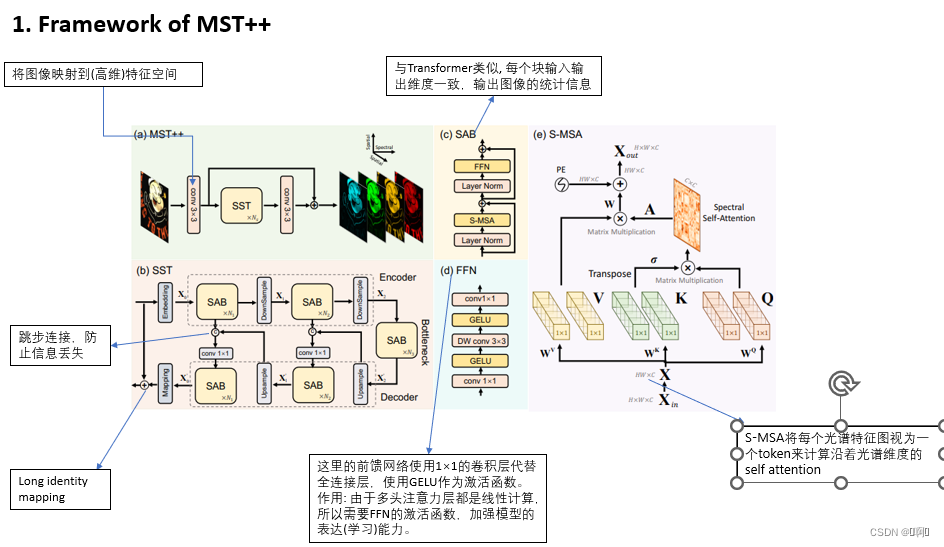
为什么需要VKQ三个矩阵,直接用输入的特征进行self-attention不可以吗?如果非要用,为什么不是四个五个,而是三个呢?
- 三个矩阵将原始输入往不同的向量空间进行投影,如果直接用输入的feature做self-attention和加权的话,其实还是在feature空间做变换(因为整个过程都是矩阵乘法),基本没有可学习的余地,引入三个矩阵后,增大了学习参数,使得学习出来的变换空间更加的通用。
- Q(query)代表自身的期望(表示了对哪种feature感兴趣),
K(key)代表自己是哪种feature,因为别人也要进行self-attention,
V(value)是给自己打个分,用于后面的加权,其实这个可以不要,直接用输入的feature进行加权,
待续…


















 440
440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









