




自学阿里云acp学习笔记
大数据开发与治理平台概述
现在痛点:
咨询成果落地不足、工具能力不足、服务程度不高、成效可视度低
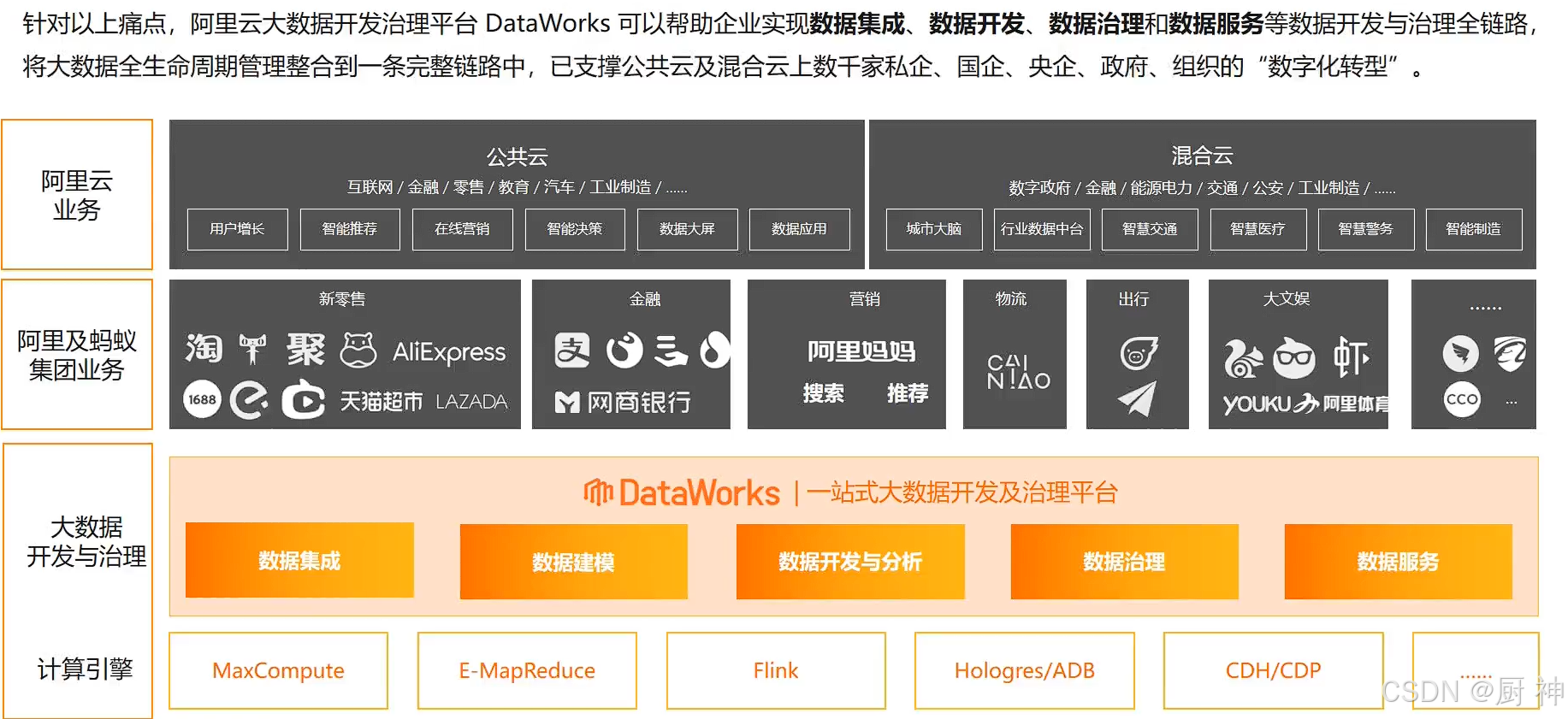
大数据开发治理平台DataWorks,基于MaxCompute、Hologres、EMR、AnalyticDB、CDP等大数据引擎,为数据仓库、数据湖、湖仓一体等解决方案提供统一的全链路大数据开发治理平台。
产品优势:
- 学习成本低
- 人效提升快
- 产品功能全
dataworks产品架构:
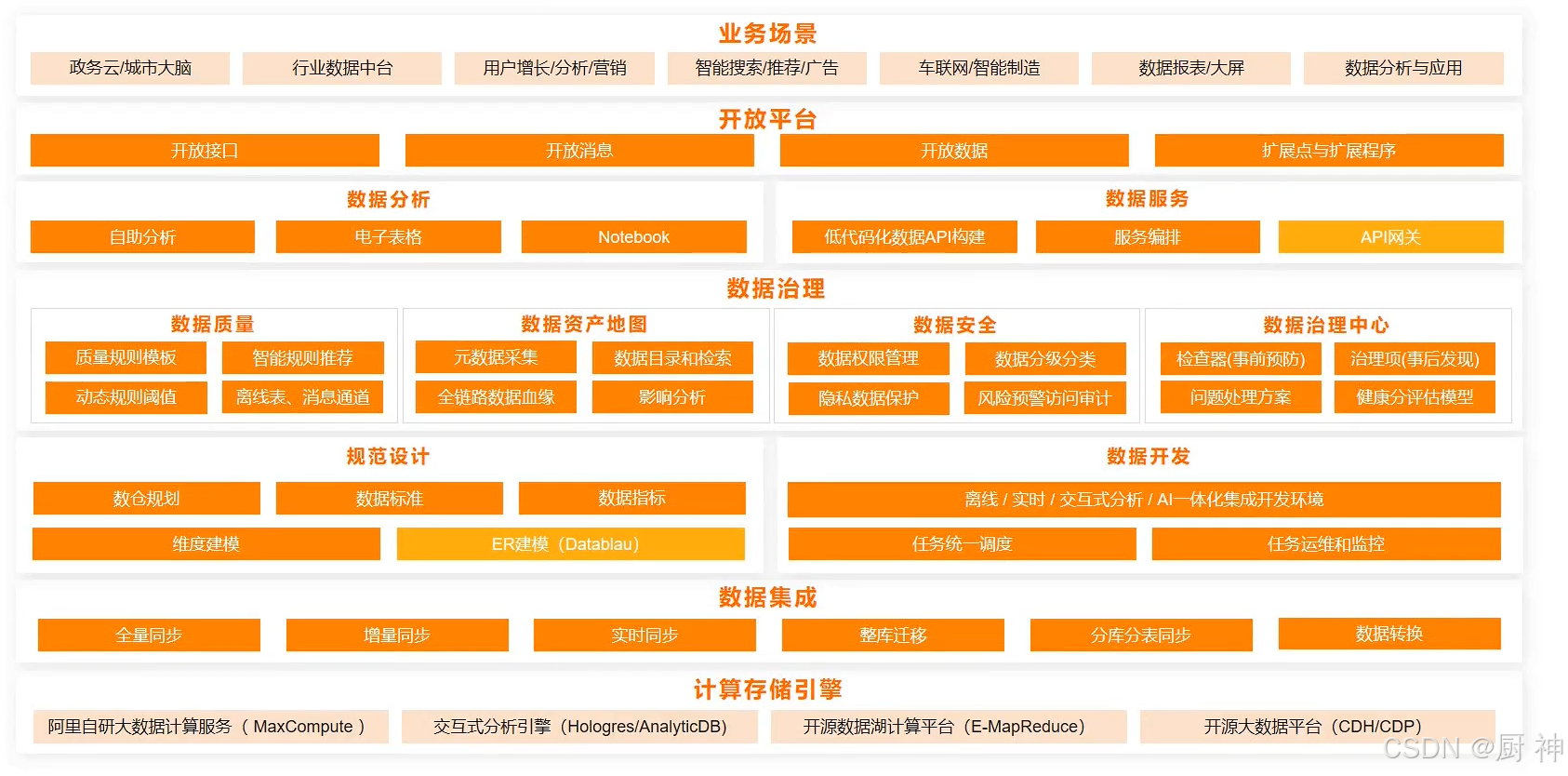
将API服务直接放到网关
以上直接应对多种场景
智能实时数据仓库
实时+离线两种计算模式
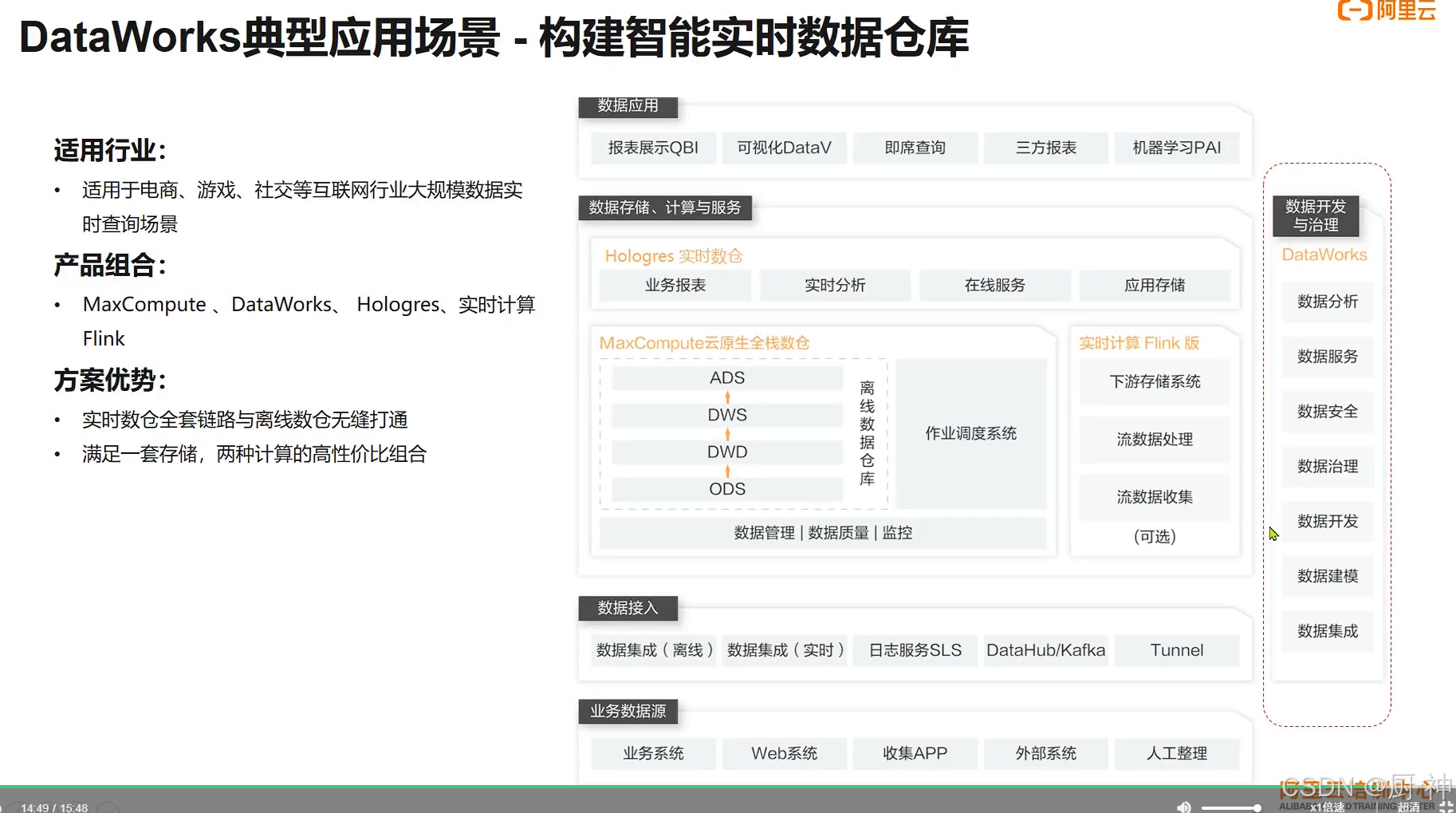
数据接入Dataworks+数据开发+flink数据计算+数据应用(实时QBI,离线DataV)等
Dataworks工作空间和MaxCompute工作空间的模式
- 简单模式:1个dataworks对应一个maxcompute
- 标准模式:1个dataworks对应多个maxcompute(一个开发,多个生产,相互隔离,可以对表权限进行严格控制,提升代码规范)
每天晚上11:30转实例
提交才会进入调度系统
数据集成
提供多种异构数据源之间的高速稳定的数据移动和同步能力
使用场景:
- 对接业务数据库:搬站上云
- 实时数仓:流式数据汇聚
- 平台融合:云上各个产品之间的数据同步
- 云上计算数据回流存储数据库:容灾备份
同步:有多种方式:
- 向导模式:下一步下一步
- 脚本模式:reader和writer通道,有精细化管理
- API创建:调用openAPI,按照代码来同步
实时同步不支持同步视图
离线同步任务流程:
新建同步节点-配置数据来源去向-配置字段映射关系-配置数据通道-配置调度属性-提交发布运行
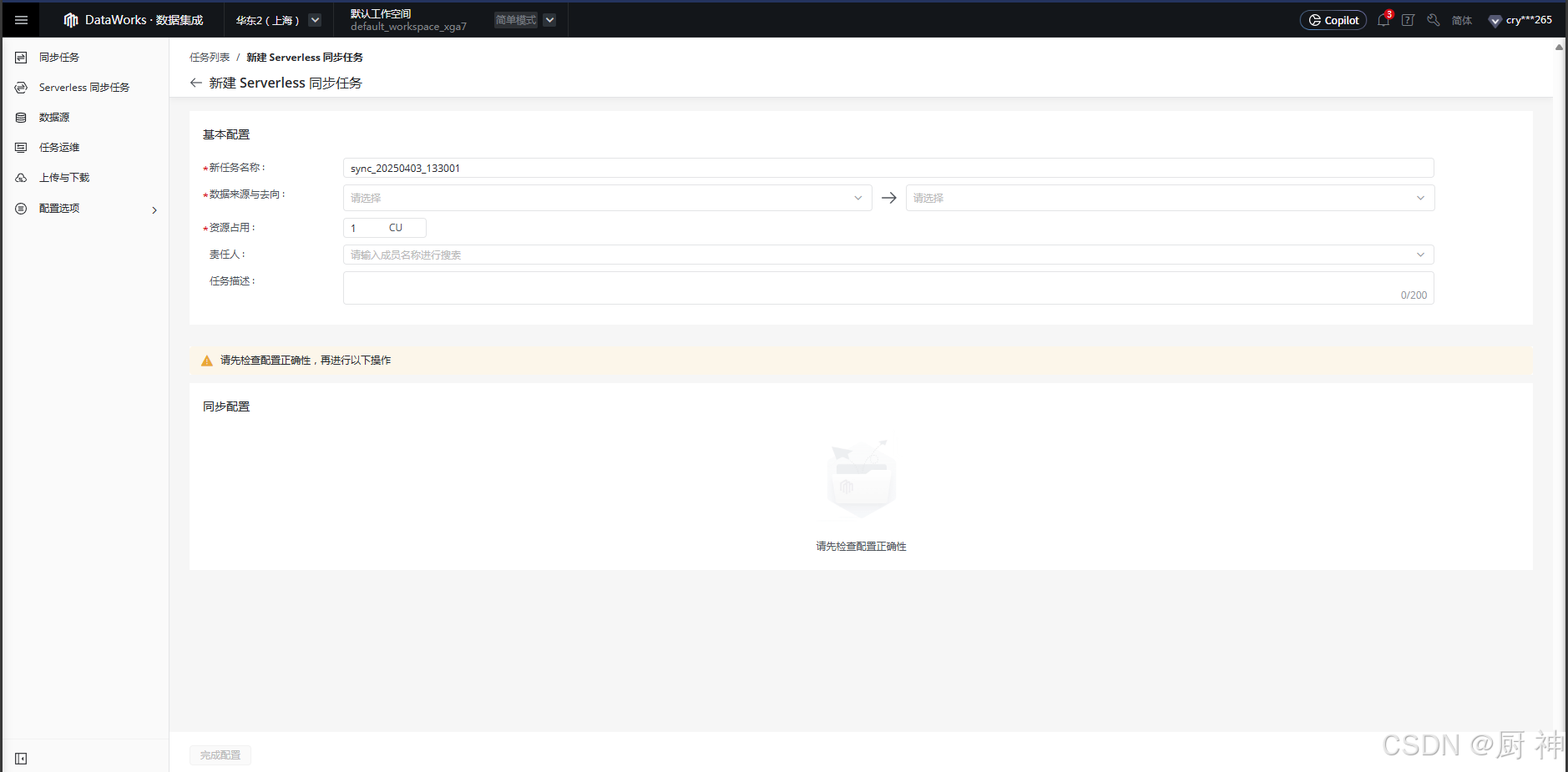
数据过滤在增量同步的时候用,没设置默认全量同步
切分键默认主键,只能是整形,字符串、float不支持,不是整形,会被忽略,相当于没有填
脚本模式创建:
创建离线同步节点-转脚本并导入模板(不可逆)-配置同步任务(编辑json)-配置调度属性-配置数据集成资源组-提交并发布任务
配置整库增量数据实时同步:
创建整库实时同步节点-设置同步来源和规则-设置目标表-DDL消息处理规则设置-运行资源设置-提交并发布任务
数据建模
- 范式建模法:实体-属性-关系-ER模型,高度计欸勾画,规范性好,相对容易扩展,无冗余,但是不利于对接BI、不利于下钻、物理设计常与业务不匹配
- 维度建模法:按照实时表、维表来构建数据仓库、数据集市:星形模型、雪花模型,面向业务,可以快速交互,但是需要预处理,有大量冗余数据,一旦业务变化,需要重新定义维度。
数据分层:
| 名称 | 功能 |
|---|---|
| ods | 贴源数据层 |
| dwd | 明细数据层 |
| dws | 汇总数据层 |
| dim | 公共维度层 |
| ads | 应用数据层 |
智能数据建模:
将数据进行结构化管理
数仓规划、数据标准、维度建模、数据指标
将已有的物理表逆向生成模型
数据开发与运维
数据开发:
进入数据开发页面,创建业务流程:手动触发/周期调度任务
之后在DataStudio数据开发页面,提交-发布-在运维中心调度任务
| 名称 | 功能 |
|---|---|
| DI离线同步 | 配置离线同步任务 |
| RI实时同步 | 配置实时同步任务 |
| ODPS SQL | 于TB级数据+实时性要求不高+分布式处理场景 |
| ODPS SQL | 脚本开发模式,作为一个整体提交运行,可以保证一个执行计划依次排队依次执行,充分利用MaxCompute资源 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











