






LangChain
LangChain 是一个开源的框架,旨在帮助开发者使用大型语言模型(LLms)和聊天模型构建端到端的应用程序。提供了一套工具、组件和接口,以简化创建由这些模型支持的应用程序的过程。LangChain的核心概念包括组件(Components)、链(Chains)、模型输入/输出(Model I/O)、数据连接(Data Connection)、内存(Memory)、和代理(Agent)等。
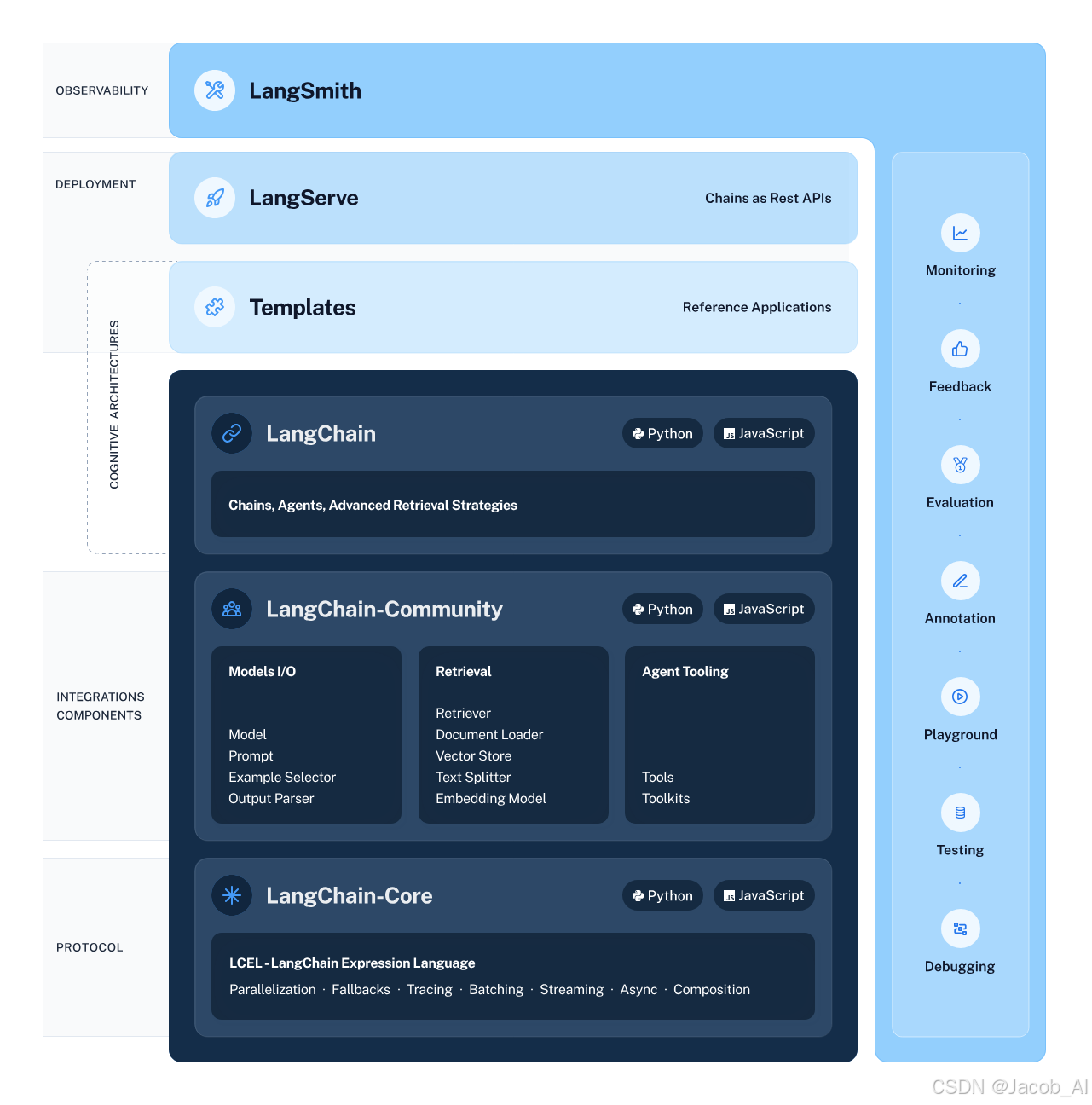
1、组件(Components)
- 模型输入/输出(Model I/O):负责管理与语言模型交互,包括输入(提示,Prompts)和格式化输出(输出解析器,Output Parsers);
- 数据连接(Data Connection):管理向量数据存储、内容数据获取和转换,以及向量数据查询;
- 内存(Memory):用于存储和获取对话历史记录的功能模块;
- 链(Chains):串联Memory、Model I/O 和Data Connection,以实现串行化的连续对话和推理流程;
- 代理(Agents):基于链进一步串联工具,将语言模型的功能和本地、云服务能力结合;
- 回调(Callbacks):提供了一个回调系统,可连接到请求的各个阶段,便于进行日志记录、追踪等数据导流。
2、模型输入/输出(Model I/O)
- LLMs:与大预言模型进行接口交互,如OpenAI,Coherent等;
- Chat Modes:聊天模型是语言模型的变体,他们可以聊天信息列表为输入和输出,提供更结构化的消息;
3、数据连接(Data Connection)
- 向量数据存储(Vector Stores):用于构建私域知识库;
- 内容数据获取(Document Loaders):获取内容数据;
- 转换(Transformers):处理数据转换;
- 向量数据查询(Retrievers):查询向量数据;
4、内存(Memory)
- 用于存储对话历史记录,以便在连续对话中保持上下文;
5、链(Chains)
- 是组合在一起以完成特定任务的一系列组件;
6、代理(Agents)
- 基于链的工具,结合了语言模型的能力和本地、云服务;
7、回调(Callbacks)
- 提供了一个系统,可以在请求的不同阶段进行日志记录、追踪等;
LangChain可以构建哪些应用
LangChain 作为一个强大的框架,旨在帮助开发者利用大型语言模型(LLMs)构建各种端到端的应用程序。以下是一些可以使用 LangChain 开发的应用类型:
1、聊天机器人(Chatbots):
- 创建能够与用户进行自然对话的聊天机器人,用于客户服务、娱乐、教育或其他交互式场景。
2、个人助理(Personal Assistants):
- 开发智能个人助理,帮助用户管理日程、回答问题、执行任务等。
3、文档分析和摘要(Document Analysis and Summarization):
- 自动分析和总结大量文本数据,提取关键信息,为用户节省阅读时间。
4、内容创作(Content Creation):
- 利用语言模型生成文章、故事、诗歌、广告文案等创意内容。
5、代码分析和生成(Code Analysis and Generation):
- 帮助开发者自动生成代码片段,或者提供代码审查和优化建议。
6、工作流自动化(Workflow Automation):
- 通过自动化处理日常任务和工作流程,提高工作效率。
7、自定义搜索引擎(Custom Search Engines):
- 结合语言模型的能力,创建能够理解自然语言查询的搜索引擎。
8、教育和学习辅助(Educational and Learning Aids):
- 开发教育工具,如智能问答系统、学习辅导机器人等,以辅助学习和教学。
9、数据分析和报告(Data Analysis and Reporting):
- 使用语言模型处理和分析数据,生成易于理解的报告和摘要。
10、语言翻译(Language Translation):
- 利用语言模型进行实时翻译,支持多语言交流。
11、情感分析(Sentiment Analysis):
- 分析文本中的情感倾向,用于市场研究、社交媒体监控等。
12、知识库和问答系统(Knowledge Bases and Q&A Systems):
- 创建能够回答特定领域问题的智能问答系统。
自定义调用本地大模型方法
1、类属性定义
- max_token: 定义类模型可以处理的最大令牌数;
- do_sample: 指定是否在生成文本时采用采样策略;
- temperature: 控制生成文本的随机性,较高的值会产生更多的随机性;
- top_p: 一种替代temperature的采样策略,这里设置为0.0,意味着不适用;
- tokenizer: 分词器,用于将文本转换为模型可以理解的令牌;
- model: 存储加载的模型对象;
- history: 存储对话历史;
2、构造函数
- init: 构造函数初始化了父类的属性;
3、属性方法
- _llm_type: 返回模型的类型,即ChatGLM3;
4、加载模型的方法
- load_model: 方法用于加载模型和分词器。首先长是从指定的路径加载分词器,然后加载模型并将模型设置为评估模式。这里的模型和分词器是从Hugging Face 的 transforms库中加载的;
5、调用方法
- _call: 一个内部方法,用于调用模型。它被设计为可以被子类覆盖。
- invoke: 这个方法使用模型进行聊天。他接受一个提示和一个历史记录,并返回模型的回复后和更新狗的历史记录。这里使用了模型方法chat来生成回复,并设置了采样、最大长度和温度等参数;
6、流式方法
- stream: 这个方法允许模型逐步返回回复,而不是一次次那个返回所有的内容。这对于长回复或者需要实时显示回复的场景很有用。它通过模型的方法stream_chat实现,并逐块返回回复;
class ChatGLM3(LLM):
max_token:int=8192
do_sample:bool=True
temperature:float=0.3
top_p=0.0
tokenizer:object=None
model:object=None
history=[]
def __init__(self):
super().__init__()
@property
def _llm_type(self):
return "ChatGLM3"
def load_model(self,modelPath=None):
# 配置分词器
tokenizer = AutoTokenizer.from_pretrained(modelPath,trust_remote_code=True,use_fast=True)
# 加载模型
model = AutoModel.from_pretrained(modelPath,trust_remote_code=True,device_map="auto")
model = model.eval()
self.model = model
self.tokenizer = tokenizer
def _call(self,promt,config={},history=[]):
if not isinstance(prompt,str):
prompt = prompt.to_string()
response,history = self.model.chat(
self.tokenizer,
prompt,
history = history,
do_sample = self.do_sample,
max_length = self.max_token,
temperature = self.temperature
)
self.history = history
return AIMessage(content = response)
def stream(self,promt,config={},history=[]):
if not isinstance(prompt,str):
prompt = prompt.to_string()
preResponse = ""
for response,new_history in self.model.stream_chat(self.tokenizer,prompt):
if preRespone == "":
result = response
else:
result = response[len(preResponse):]
preResponse = response
yield result

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









