





PrototypeFormer: 探索原型关系的学习用于小样本图像分类
引用:He F, Li G, Si L, et al. PrototypeFormer: Learning to Explore Prototype Relationships for Few-shot Image Classification[J]. arxiv preprint arxiv:2310.03517, 2023.
论文地址:下载地址
论文代码:暂时没有提供(重金求址! 反正我没有查到)
Abstract
小样本图像分类在解决新类别中样本有限导致分类性能不佳的问题上受到广泛关注。然而,许多研究采用复杂的学习策略和多样化的特征提取方法来应对这一挑战。在本文中,我们提出了一种名为PrototypeFormer的方法,该方法旨在通过探索原型之间的关系来显著提升传统的小样本图像分类方法。具体来说,我们利用Transformer架构构建了一个原型提取模块,旨在提取在小样本分类中更具区分性的类别表示。此外,在模型训练过程中,我们提出了一种基于对比学习的优化方法,以在小样本学习场景中优化原型特征。尽管该方法简单,却表现出色,无需任何复杂的技巧。我们在多个流行的小样本图像分类基准数据集上进行了实验,结果表明,我们的方法优于目前所有的最新方法。特别是,在miniImageNet数据集的5路5样本和5路1样本任务上,我们的方法分别达到了97.07%和90.88%的准确率,分别比当前的最新结果高出7.27%和8.72%。代码将在后续公开发布。
1 Introduction
神经网络在大规模图像分类任务中取得了显著成功。然而,小样本图像分类领域,模型必须在有限标记样本(例如,每个类别只有五个或一个样本)的情况下快速适应新的数据分布,这仍然是一个挑战。由于其在医学图像分析和机器人等领域的广泛应用前景,小样本学习1吸引了计算机视觉和机器学习社区的广泛关注。
近年来,小样本学习方法主要通过增强样本/特征或利用新颖的神经模块来改善模型的泛化能力。许多方法2 3 4 5 6 7利用生成模型来生成新样本或增强特征空间,旨在逼近实际数据分布,从而最终促进小样本学习。设计复杂的特征表示模块也是提升低样本类别模型性能的一种有效途径。具体来说,CAN8利用跨注意力机制以一种传递式的方式获取具有增强类别特征的丰富样本嵌入,而DN49、DMN410和MCL11采用局部特征表示代替全局表示,以获得更具区分性的特征表示。
沿着特征表示学习方法的研究方向,我们引入了一个原型提取模块,以增强原型嵌入。与早期的特征表示方法不同,我们的研究深入探讨了每个类别内部以及整个任务之间的复杂关系,以得出更具区分性的原型表示。
学习原型嵌入12 13对于小样本分类非常有用。ProtoNet12引入了一种方法,使用原型点来封装整个类别的特征嵌入,而13则提出了加强原型点概念的方法。然而,它们在学习稳健类别特征时忽略了原型关系。在本文中,我们深入研究了原型点之间的相互关系,考虑了类内和类间的关系。我们首先引入了一个新颖的原型提取模块,通过子原型的自注意力机制学习类内样本的关系,这些子原型通过平均样本特征子集获得。该模块通过考虑同类样本子集之间的特征关系,捕捉到更具代表性的类别特征。
为了进一步增强小样本场景下类别特征的稳健性,我们引入了“原型对比损失”——一种专门设计用于捕捉类间原型相互作用的新型对比损失。我们方法的核心概念是“子原型”,它在小样本场景中代表正类和负类的嵌入。通过在对比学习框架中使用这些子原型,我们旨在培养更具区分性的表示。具体而言,对比学习策略确保了相似的类别嵌入在特征空间中更加接近,而不同的类别嵌入则被推远,从而增强了我们代表性原型的区分能力。
此外,一些研究14 15已经证明了CLIP预训练模型在小样本学习中的卓越特征提取能力。我们也将CLIP的图像编码器集成到我们的方法中,作为强大的特征提取模块。

图 1:探索同类样本和不同类别样本之间的特征关系,以构建任务特定的特征表示
我们总结了以下几个贡献:
- 原型提取模块
我们为小样本学习引入了一种新颖且简单的网络架构,采用可学习的原型提取模块来提取原型表示。 - 原型对比损失
我们通过对支持集子集的线性组合形成子原型。随后,我们基于这些子原型使用原型对比损失来优化模型,以获得更稳健的原型表示。 - 实现最先进的性能
我们在多个公开的小样本基准数据集上评估了我们的方法,结果表明,所提出的方法在三个流行的数据集上均优于当前最新的小样本学习方法。值得注意的是,我们在miniImageNet数据集上实现了高达8.72%的显著性能提升。
2 Related Work
2.1 Few-shot Learning
近年来,深度神经网络的快速发展主要得益于大规模标注数据集的支持。然而,数据收集和人工标注的高成本使得小样本学习成为广泛关注的焦点。
小样本学习通常分为基于优化的方法和基于度量的方法。基于度量的方法的主要思想是定义特定的度量标准,以类似于最近邻算法的方式对样本进行分类。Siamese网络16使用共享的特征提取器从支持集和查询集中提取特征表示,随后为每一对支持集和查询集单独计算分类相似度。原型网络12为每类样本计算原型点,并通过计算查询样本与每个原型点的L2距离来进行分类。在关系网络17中,创新性地引入了可学习的非线性分类器用于样本分类。CAN8通过计算样本的跨注意力机制,提高了网络对分类目标的关注度,从而提升了模型性能。此外,为了减少样本背景的干扰,DN49和DMN410通过比较局部描述符之间的相似性,消除不包含分类目标的局部描述符。类似的努力还包括COSOC18,其通过区分分类目标和背景元素来增强分类性能。HCTransformers19提出了分层级联Transformer架构,旨在解决大规模模型在小样本学习中面临的过拟合挑战。同时,FewTURE20也采用了Transformer架构,以从图像的主要目标中提取关键特征。
在广义小样本学习领域,已经有大量研究1421利用预训练模型来提高小样本学习的有效性。在我们的研究中,我们也整合了预训练的CLIP模型22,以增强模型的特征提取能力。然而,关键的区别在于我们的模型采用元学习的方法进行训练。
2.2 Sample Relation
不同类别样本之间存在多样化的样本关系,目前大多数模型都是基于建立这些样本关系的基础构建的。许多研究的目标是使模型在各种类别样本关系中都能具有强大的泛化性能,从而最小化邻域风险。CAN8和OLTR23通过利用个别样本之间的相关性,将样本特定的关系纳入共享上下文中。IEM24分析了样本之间的局部相关性,并为这些相关性执行了内存存储更新。IRM25通过探索样本不变特征与伪特征之间的相关性来减少邻域风险。
在跨领域任务中,26通过舍弃特定样本关系,探讨了样本关系在不同领域之间的可迁移性。类似地,27通过使用深度对抗性解耦自编码器探索了领域不变和类别不变的关系,从而完成跨领域分类任务。BatchFormer28通过在训练过程中隐式探索小批量样本之间的关系,在数据稀缺任务中取得了显著的提升。在mixup3中,样本通过线性插值来捕捉样本之间的类别不变关系。在我们的工作中,我们通过样本的线性组合来探索它们之间与任务相关的关系。
2.3 Contrative Learning
近年来,对比学习取得了显著的成功。InstDisc29提出在无监督学习框架中使用实例区分任务作为基于类别的区分任务的替代方案。MOCO30通过构建动态字典并执行基于动量的更新策略,实现了对下游任务的良好迁移能力。对比学习在时间序列任务中展现了其广泛性和灵活性,涵盖了音频和文本数据等领域。大量研究303122展示了对比学习在无监督学习和计算机视觉领域的泛化研究中的积极作用。
对比学习的目标是将同一类别的样本拉近,同时将不同类别的样本分开,从而为样本特征提取构建合适的模式。在任务训练中,我们利用对比学习方法来提取任务中的类别关系,从而增强小样本学习的分类性能。
3 Method
在本节中,我们首先描述与小样本学习相关的问题定义。随后,介绍我们提出的方法。最后,我们深入讨论了我们方法中的两个重要组成部分:原型提取模块和原型对比损失。
3.1 Problem Formulation
情境训练不同于深度神经网络的传统训练方法。在传统的深度神经网络训练中,我们通常是逐个样本进行训练。而在情境训练中,我们通常按任务逐个训练神经网络。情境训练机制32已被证明可以促进跨类别学习可迁移的知识。
在小样本学习中,我们通常将数据集划分为训练集、验证集和测试集。训练集、验证集和测试集之间的类别没有重叠。因此,我们将训练集中的类别称为已见类别,而将验证集和测试集中的类别称为未见类别。在训练阶段,我们从训练集中随机采样,创建支持集和查询集。我们用 S S S 表示支持集,用 Q Q Q 表示查询集。在支持集 S S S 中,有 N N N 个类别,每个类别包含 K K K 个样本。我们将查询集 Q Q Q 视为未标记样本,并使用支持集 S S S 中的已标记样本对 Q Q Q 中的未标记样本进行分类。支持集 S S S 包含 N N N 个类别,每个类别有 K K K 个样本。在测试阶段,我们遵循相同的程序,将测试集划分为支持集和查询集,类似于训练阶段的操作。这使我们能够以与训练过程一致的方式评估模型在未见类别上的小样本学习性能。我们通常将满足上述设置的任务称为 N N N 路 K K K 样本任务。在我们的工作中,我们使用上述问题定义来训练和评估模型。
3.2 Overview
我们对支持集进行线性组合,并通过原型提取模块应用非线性映射。此外,我们使用对比学习策略优化原型提取模块,以获得更优的原型表示。图2展示了我们方法的概览。
如图2所示,我们通过冻结的CLIP特征提取网络处理支持集和查询样本,以获得图像嵌入。随后,我们对支持集样本进行线性组合,生成 C 1 K C_1K C1K 个子支持集。同时,为每个支持集和子支持集添加一个原型标记,该原型标记是通过计算相应嵌入集合的平均值获得的。每个支持集和子支持集分别被输入到原型提取模块,以获得编码的原型和子原型。我们保留这些原型和子原型,同时丢弃来自支持集的样本嵌入。我们通过对比损失计算保留的子原型来获得 L P r o t o t y p e L_{Prototype} LPrototype,而 L C l a s s i f i e r L_{Classifier} LClassifier 则通过计算查询样本与原型的嵌入来获得。最后,我们将 L P r o t o t y p e L_{Prototype} LPrototype 和 L C l a s s i f i e r L_{Classifier} LClassifier 相加,形成最终的优化目标。
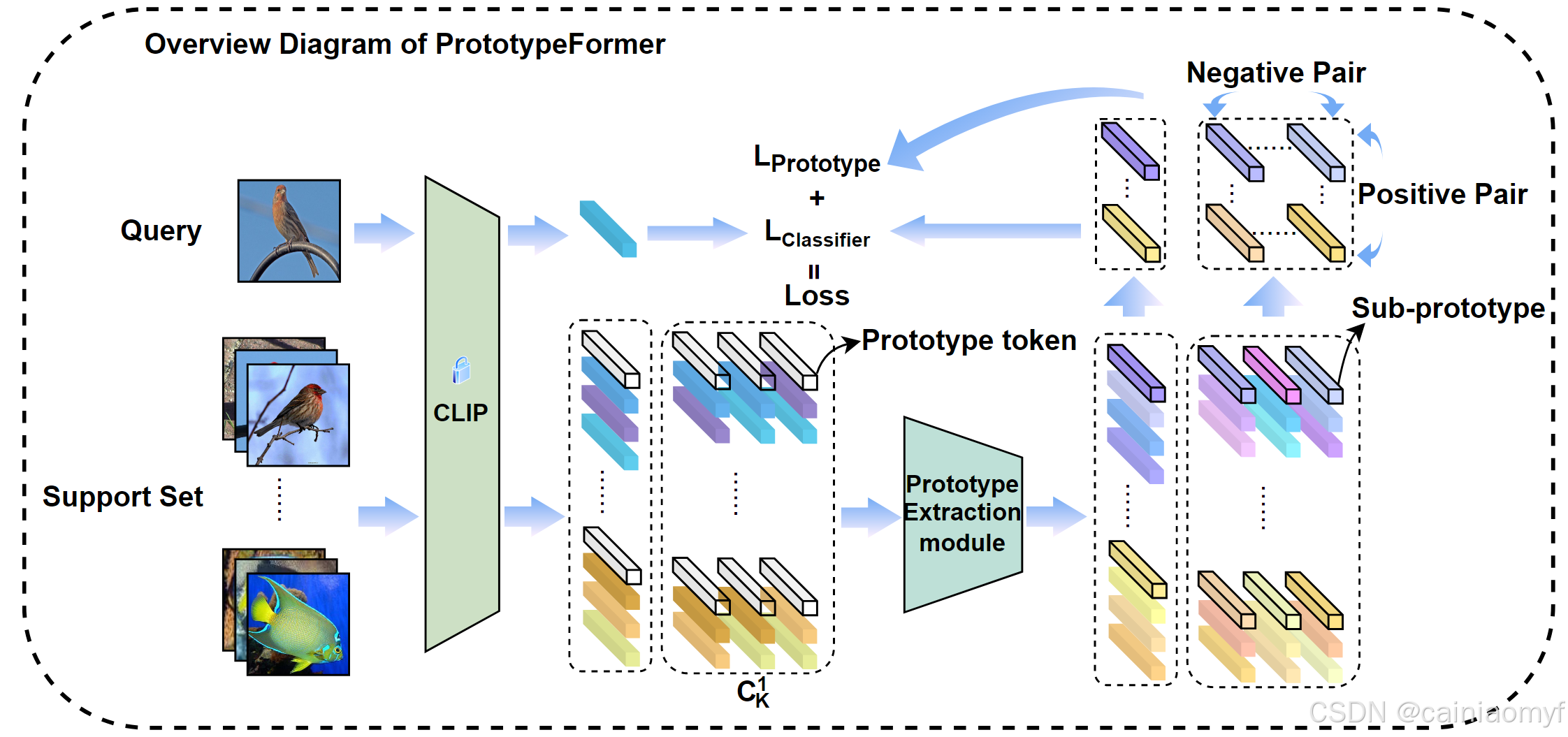 图 2:此图展示了本文提出的方法的整体流程图。我们对支持集进行线性组合,并通过原型提取模块获得子原型。子原型用于计算原型对比损失
L
prototype
L_{\text{prototype}}
Lprototype,而原型则用于计算分类损失
L
classifier
L_{\text{classifier}}
Lclassifier。我们将
L
prototype
L_{\text{prototype}}
Lprototype 和
L
classifier
L_{\text{classifier}}
Lclassifier 相加以获得最终的优化目标。
图 2:此图展示了本文提出的方法的整体流程图。我们对支持集进行线性组合,并通过原型提取模块获得子原型。子原型用于计算原型对比损失
L
prototype
L_{\text{prototype}}
Lprototype,而原型则用于计算分类损失
L
classifier
L_{\text{classifier}}
Lclassifier。我们将
L
prototype
L_{\text{prototype}}
Lprototype 和
L
classifier
L_{\text{classifier}}
Lclassifier 相加以获得最终的优化目标。
3.3 Prototype Extraction Module
在本节中,我们将详细介绍我们提出的原型提取模块。此外,我们还将对我们的方法与现有的类特征提取方法进行比较分析。
首先,我们介绍原型表示,这是最早出现在小样本学习中的类特征表示。在 N N N 路 K K K 样本任务中,我们假设存在一个类别 C C C,在支持集 S S S 中,存在一个子集 S C = { x 1 , x 2 , … , x K ∣ y = C } S_C = \{x_1, x_2, \dots, x_K | y = C\} SC={x1,x2,…,xK∣y=C}。我们将特征提取网络表示为 f f f。在这种情况下,我们可以将原型网络中的类特征表示定义如下:
P r o t o t y p e ( C ) = 1 K ∑ i = 1 K f ( x i ) , x i ⊂ S C P rototype (C) = \frac{1}{K} \sum_{i=1}^{K} f(x_i), x_i \subset S_C Prototype(C)=K1i=1∑Kf(xi),xi⊂SC
原型点的方法提供了一种简单且有效的类特征表示方式。然而,特征提取网络中使用的全局平均池化层可能会引入噪声,导致原型点偏离其真实表示,从而产生偏差。为了解决这个问题,DN49 和 DMN410 移除了特征提取网络中的全局平均池化层。它们使用局部描述符代替图像的全局特征表示,并利用判别性最近邻算法获取图像中最具代表性的局部描述符,作为样本的特征表示。
然而,我们认为图像背景在图像分类性能中具有一定的影响,并且还提供了一些与类别相关的上下文特征。因此,我们提出了一种新的类特征提取模块,称为原型提取模块,以替代当前的小样本类特征表示。在 ViT33 中,图像被划分为补丁,并使用 Transformer34 来计算这些补丁之间的关联性,从而得到整个图像的特征表示。受 ViT 的启发,我们简单地将图像视为输入 Transformer 的补丁集合,从而获得整个类别的特征表示。原型提取模块的基本架构如图 3 所示。我们用 ϕ \phi ϕ 表示原型提取模块,并可以将其表达为以下形式:
P r o t o t y p e ( C ) = ϕ ( x t o k e n , f ( x 1 ) , f ( x 2 ) , … , f ( x K ) ) , x i ⊂ S C P rototype (C) = \phi (x_{token}, f (x_1) , f (x_2) , \dots, f (x_K)), x_i \subset S_C Prototype(C)=ϕ(xtoken,f(x1),f(x2),…,f(xK)),xi⊂SC
其中, x t o k e n x_{token} xtoken 表示该类别的原型标记,其可以表示为:
x t o k e n = 1 K ∑ i = 1 K f ( x i ) , x i ⊂ S C x_{token} = \frac{1}{K} \sum_{i=1}^{K} f(x_i), x_i \subset S_C xtoken=K1i=1∑Kf(xi),xi⊂SC

图 3:原型提取模块采用了 Transformer 结构34,将原型标记和来自支持集中同类图像的嵌入作为输入,以获得该类别的原型和子原型。
最后,我们使用一种简单的度量学习分类方法来对查询样本进行分类。具体来说,我们计算查询样本的嵌入与特征空间中原型点之间的距离,以衡量查询样本与各类别之间的相似性。该距离度量用于分类,其中查询样本被分配到在特征空间中与其嵌入最接近的类别。该分类方法可以用以下公式形式化:
arg min c ⊂ C L 2 ( x q u e r y , P r o t o t y p e ( c ) ) \arg \min_{c \subset C} L2 (x_{query}, P rototype (c)) argc⊂CminL2(xquery,Prototype(c))
分类损失通过交叉熵损失进行优化,分类损失的公式如下:
L o s s c l a s s i f y = − ∑ c = 1 N y c log ( e − L 2 ( x q u e r y , P r o t o t y p e ( c ) ) ∑ i = 1 N e − L 2 ( x q u e r y , P r o t o t y p e ( i ) ) ) Loss_{classify} = - \sum_{c=1}^{N} y_c \log \left( \frac{e^{-L2(x_{query}, P rototype(c))}}{\sum_{i=1}^{N} e^{-L2(x_{query}, P rototype(i))}} \right) Lossclassify=−c=1∑Nyclog(∑i=1Ne−L2(xquery,Prototype(i))e−L2(xquery,Prototype(c)))
其中, y c y_c yc 是样本真实类别标签的独热编码。
3.3 Prototype Contrastive Loss
为了增强原型提取模块的泛化能力,我们从对比学习中汲取灵感,提出了原型对比损失。对比损失最早由 Hadsell 等人提出35,并为后续非常成功的对比学习奠定了基础30 31。对比损失的主要思想是构建正样本和负样本对,正样本对在特征空间中被拉近,而负样本对则被推远。
在小样本学习中,通过从支持集 S S S 中同一类别提取 K − 1 K-1 K−1 个样本,我们可以得到 K K K 个不同的子支持集:
S c i = { x c 1 , … , x c ( i − 1 ) , x c ( i + 1 ) , … , x c K } , i = 1 , 2 , … , K , c ⊂ C S_{ci} = \{x_{c1}, \dots, x_{c(i-1)}, x_{c(i+1)}, \dots, x_{cK}\}, \quad i = 1, 2, \dots, K, \quad c \subset C Sci={xc1,…,xc(i−1),xc(i+1),…,xcK},i=1,2,…,K,c⊂C
然后,我们将从同一类别样本构建的这 K K K 个子支持集依次传入原型提取模块,以获得该类别的 K K K 个子原型。我们将从同类支持集样本中获得的 K K K 个子原型用作正样本对。同时,我们将从不同类别的子支持集中获得的子原型作为负样本对。我们可以将构建的正样本对表示为:
P o s c = { p c 1 , p c 2 , … , p c K } , C = 1 , 2 , … , N P_{os}^{c} = \{p_{c1}, p_{c2}, \dots, p_{cK}\}, \quad C = 1, 2, \dots, N Posc={pc1,pc2,…,pcK},C=1,2,…,N
因此,我们可以使用构建的正样本对和负样本对得到原型对比损失,如下所示:
L
p
r
o
t
o
t
y
p
e
=
exp
(
1
N
⋅
∑
i
,
j
=
1
K
L
2
(
p
c
i
,
p
c
j
)
+
I
∑
m
≠
n
∑
i
,
j
=
1
K
L
2
(
p
m
,
i
,
p
n
,
j
)
+
I
)
L_{prototype} = \exp \left( \frac{1}{N} \cdot \sum_{i,j=1}^{K} L2(p_{ci}, p_{cj}) + I \sum_{m \neq n} \sum_{i,j=1}^{K} L2(p_{m,i}, p_{n,j}) + I \right)
Lprototype=exp
N1⋅i,j=1∑KL2(pci,pcj)+Im=n∑i,j=1∑KL2(pm,i,pn,j)+I
因为当
K
=
1
K = 1
K=1 时,支持集中每个类别仅包含一个样本,导致
∑
i
,
j
=
1
K
L
2
(
p
c
i
,
p
c
j
)
=
0
\sum_{i,j=1}^{K} L2(p_{ci}, p_{cj}) = 0
∑i,j=1KL2(pci,pcj)=0。为了避免这种情况,我们添加了恒等元
I
I
I 来防止这种情况的发生。
模型在训练阶段的总体损失为:
L
o
s
s
=
L
o
s
s
c
l
a
s
s
i
f
i
e
r
+
L
o
s
s
p
r
o
t
o
t
y
p
e
Loss = Loss_{classifier} + Loss_{prototype}
Loss=Lossclassifier+Lossprototype
4 Experiments
在本节中,我们将在多个小样本学习基准数据集上评估所提出的方法,并与当前最先进的方法进行比较。此外,我们还将进行消融实验和可视化实验,以进一步分析和验证PrototypeFormer的有效性。
4.1 Datasets
miniImageNet32 是 ImageNet 数据集的一个子集,并且在小样本学习研究中被广泛使用。该数据集包含 100 个类别,每个类别包含 600 张图像,总计 60,000 张图像。数据集被划分为 64 个类别用于训练集,16 个类别用于验证集,以及 20 个类别用于测试集。
tieredImageNet 是相较于 miniImageNet 更大的 ImageNet 数据集子集。该数据集包含 608 个类别,总计 779,165 张图像。对于小样本学习,数据集被分为三个子集,351 个类别用于训练集,97 个类别用于验证集,160 个类别用于测试集。
Caltech-UCSD Birds-200-201136,也称为 CUB,是当前细粒度分类和识别研究的基准图像数据集。该数据集包含 11,788 张鸟类图像,涵盖 200 个鸟类亚种。我们将其划分为 100、50 和 50 个类别分别用于训练、验证和测试。
4.2 Experimental Settings
为了获得更好的图像特征,我们使用 ViT-Large/14 作为图像特征提取的主干网络,并搭配 CoOp14 和 Clip-Adapter15 中使用的相同的 CLIP 预训练模型。由于小样本学习中的数据有限,原型提取模块采用了两层 Transformer 架构,并且不包含位置编码。在训练阶段,我们冻结特征提取网络,仅训练本文提出的原型提取模块,以保留预训练 CLIP 模型的图像特征提取能力,并获得具有优秀类别特征表示的原型提取模块。
在训练阶段,我们保持传统的情境训练方法,并在 5-way 5-shot 和 5-way 1-shot 任务设置上进行训练。此外,我们使用 Adam 优化器37 来优化模型。我们将优化器的初始学习率设置为 0.0001,动量权重系数 β 1 \beta_1 β1 和 β 2 \beta_2 β2 以及优化器的 ϵ \epsilon ϵ 参数分别设置为其默认值 0.9、0.999 和 1 × 1 0 − 8 1 \times 10^{-8} 1×10−8。在梯度更新策略中,我们采用梯度累积算法,即每累积 10 个批次的梯度后再执行一次参数更新。我们将模型训练 100 个 epoch,每个 epoch 包含 500 个批次,每个批次代表一个任务。在图像增强过程中,我们首先调整图像大小,然后应用中心裁剪,以获得 224 × 224 像素的图像输入。
在测试阶段,为了确保公平性,我们遵循小样本学习的评估方法,没有进行任何更改。我们从测试集中随机抽取 2000 个任务。对于每个任务,我们从每个类别中提取 15 个查询样本来评估我们的方法。为了确保结果的可靠性,我们报告了具有 95% 置信区间的平均准确率。
4.3 Results
按照小样本学习的标准实验设置,我们在 5-way 1-shot 和 5-way 5-shot 任务上进行了实验,以评估我们的方法。实验结果如表 1 所示。
如表 1 所示,我们的方法在 miniImageNet 数据集的 5-way 5-shot 和 5-way 1-shot 任务上均优于当前最先进的结果。令人兴奋的是,在 5-way 5-shot 任务中,我们的方法在该数据集上相较于当前最先进的方法取得了 7.27% 的准确率提升。同时,我们的方法在 5-way 1-shot 任务中也比现有最优方法提升了 6.84% 的准确率。我们的方法在 tieredImageNet 数据集和 CUB-200 数据集的 5-way 5-shot 任务中相较于现有方法也取得了显著的改进。观察表格可以发现,与 5-way 5-shot 任务相比,我们的方法在 5-way 1-shot 任务中的性能略有逊色。我们认为这是由于 5-way 1-shot 任务中缺少正样本对,这阻碍了原型提取模块准确表示类别特征的能力。
| Model | miniImageNet 5-way 5-shot | miniImageNet 5-way 1-shot | tieredImagenet 5-way 5-shot | tieredImagenet 5-way 1-shot | CUB-200 5-way 5-shot | CUB-200 5-way 1-shot |
|---|---|---|---|---|---|---|
| MAML 38 | 64.31 ± 1.1% | 47.15 ± 1.75% | 71.10 ± 1.67% | 52.07 ± 0.90% | - | - |
| Prototypical Network 12 | 78.44 ± 0.21% | 60.76 ± 0.39% | 80.11 ± 0.91% | 66.25 ± 0.34% | - | - |
| HCTransformers 19 | 89.19 ± 0.13% | 74.61 ± 0.20% | 91.72 ± 0.11% | 79.57 ± 0.20% | - | - |
| DeepEMD 39 | 82.41 ± 0.56% | 65.91 ± 0.82% | 86.03 ± 0.58% | 71.16 ± 0.87% | 88.69 ± 0.50% | 75.65 ± 0.83% |
| MCL 11 | 83.99% | 67.51% | 86.02% | 72.01% | 93.18% | 85.63% |
| POODLE 40 | 85.81% | 75.56% | 86.96% | 79.67% | 93.80% | 89.88% |
| FRN 41 | 82.83 ± 0.13% | 66.45 ± 0.19% | 86.89 ± 0.14% | 72.06 ± 0.20% | 92.92 ± 0.10% | 83.55 ± 0.19% |
| PTN 42 | 88.43 ± 0.67% | 82.60 ± 0.97% | 89.14 ± 0.71% | 84.70 ± 1.14% | - | - |
| FewTURE 20 | 86.38 ± 0.49% | 72.40 ± 0.78% | 89.96 ± 0.55% | 76.32 ± 0.87% | - | - |
| EASY 43 | 89.14 ± 0.1% | 84.04 ± 0.2% | 89.76 ± 0.14% | 84.29 ± 0.16% | 93.79 ± 0.10% | 90.56 ± 0.19% |
| iLPC 44 | 88.82 ± 0.42% | 83.05 ± 0.79% | 92.46 ± 0.42% | 88.50 ± 0.75% | 94.11 ± 0.30% | 91.03 ± 0.63% |
| Simple CNAPS 45 | 89.80% | 82.16% | 89.01% | 78.29% | - | - |
| Ours | 97.07 ± 0.11% | 90.88 ± 0.31% | 95.00 ± 0.19% | 90.87 ± 0.40% | 94.25 ± 0.16% | 89.04 ± 0.35% |
表 1:miniImageNet、tieredImagenet 和 CUB-200 数据集在 5-way 1-shot 和 5-way 5-shot 设置下的小样本学习分类准确率,置信区间为 95%。 (‘-’ 表示未报告)
4.4 Ablation Study
为了验证我们方法的有效性,我们从多个角度对所提出的方法进行了消融实验。
为了验证原型提取模块的有效性,我们在两种条件下进行了消融实验:移除原型提取模块和保留原型提取模块作为我们方法的一部分。实验结果如表2所示,“CLIP” 代表移除原型提取模块并仅保留 CLIP 预训练模型的条件。从表2可以看出,CLIP 预训练模型由于其在小样本学习中的强大零样本知识迁移能力,表现出良好的小样本图像分类性能。此外,与对比方法相比,我们提出的方法显示了显著的性能提升。
 表 2:此消融实验旨在验证原型提取模块的有效性。
表 2:此消融实验旨在验证原型提取模块的有效性。
如表 3 所示,在 miniImageNet 数据集的 5-way 5-shot 和 5-way 1-shot 设置中,有无包含原型对比损失的实验结果表明,原型对比损失对模型的优化有积极作用。

表 3:该表展示了关于模型中是否包含原型对比损失的对比实验。
另外,在表 4 中,我们在 2 层、4 层和 6 层 transformer 模块下对原型提取模块进行了消融实验。实验结果表明,随着 transformer 模块层数的增加,模型性能逐渐提升。

表 4:在 miniImageNet 数据集上,使用 2、4 和 6 层 Transformer 模块的原型提取模块的消融实验。
5 Visualization
在本节中,我们使用在 miniImageNet 数据集的 5-way 5-shot 任务上训练的模型进行了可视化分析。如图 4 所示,我们随机从测试集中的 8 个任务中提取样本,并使用 t-SNE 进行可视化。在可视化中,我们仅使用圆形符号显示 15 个查询集样本。我们使用三角形符号表示通过对支持集样本的嵌入取平均值获得的原型点。此外,我们使用五角星符号表示通过本文提出的原型提取模块获得的原型。
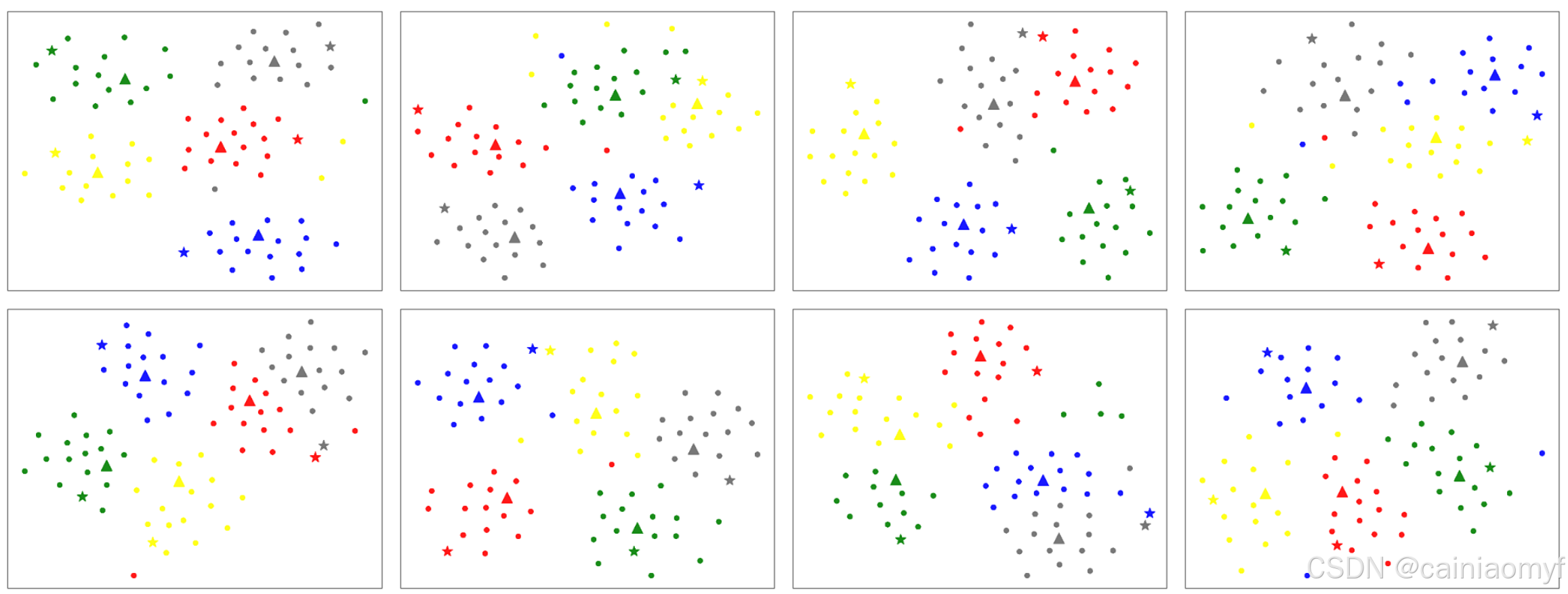
图 4:我们从测试数据集中随机选择八个任务集,并使用 t-SNE 46 对其特征嵌入进行可视化。在可视化中,圆点表示查询样本,三角形表示通过对支持集取平均得到的原型点,五角星表示通过本文提出的方法获得的类别特征嵌入。
通过观察图 4,我们可以注意到,使用原型网络12中的原型点计算方法获得的类别嵌入相对更接近各自类别的中心。另一方面,使用本文提出的方法获得的类别嵌入则更倾向于分布在各自类别的边缘。我们认为,通过原型点计算方法获得的类别嵌入是由表示该类别特征的需求驱动的,而通过本文提出的方法获得的类别嵌入则是由分类目的驱动的。因此,原型点总是位于类别的中心,以描述该类别在特征空间中的分布。相反,通过我们的方法获得的类别嵌入则倾向于位于类别的边缘,旨在远离其他类别样本,并更接近同类别的样本,以实现更有效的分类。
最后,我们进行了矩阵相似性可视化,比较了我们的方法与原型点方法。如图 5 所示,其中 “CLIP” 表示使用 CLIP 预训练模型作为骨干网络的传统原型点表示。我们分别在 miniImageNet、tieredImageNet 和 CUB-200 数据集上进行了实验。图 5 所示的结果清楚地表明,我们的方法在小样本分类中取得了显著的提升。
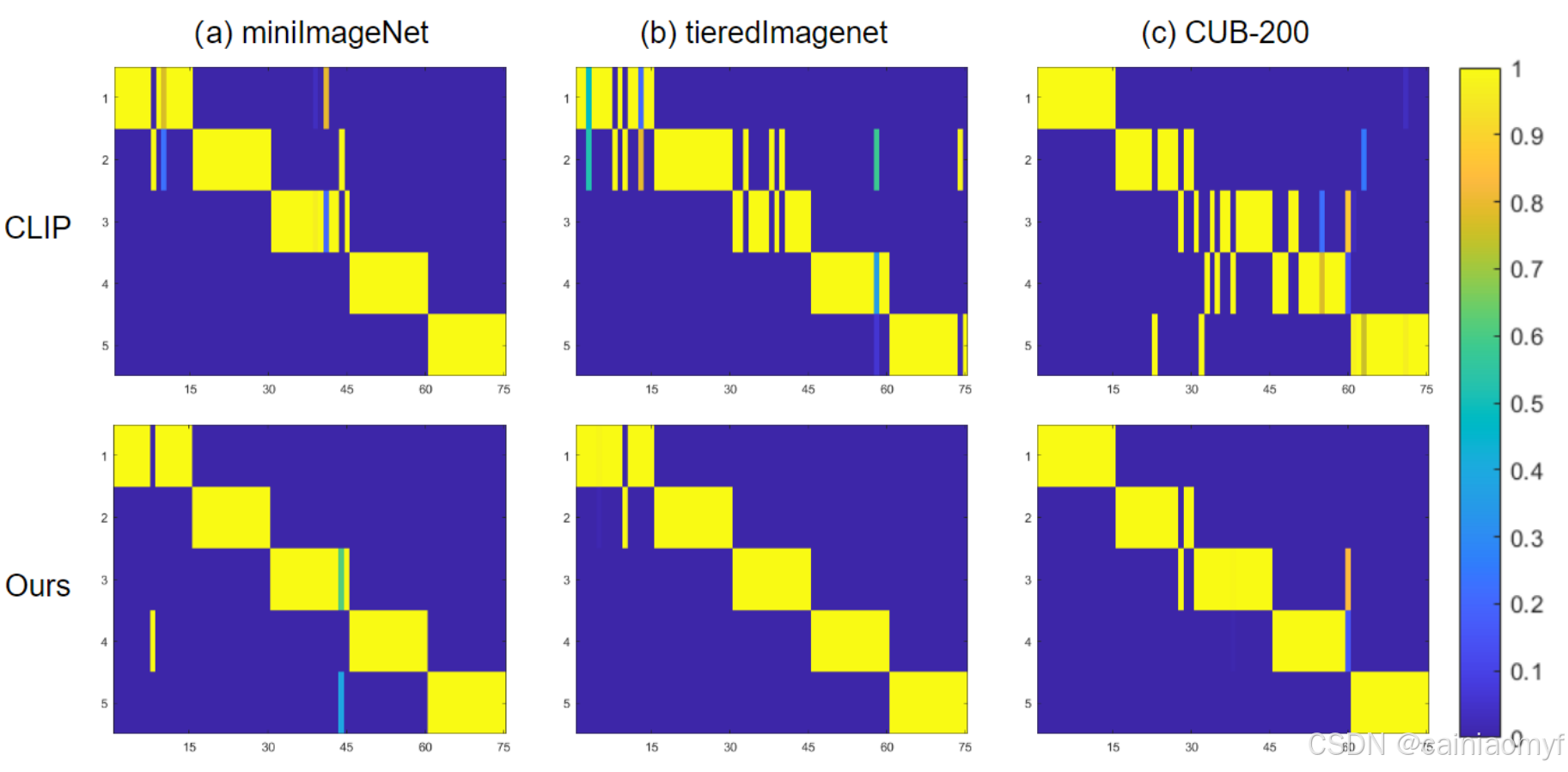
图 5:我们从测试数据集中随机选择八个任务集,并使用 t-SNE 46 对其特征嵌入进行可视化。在可视化中,圆点表示查询样本,三角形表示通过对支持集取平均得到的原型,五角星表示通过本文提出的方法获得的原型。
6 Conclusions
我们提出了一种基于Transformer的模块,用于提取类别特征嵌入,并将其应用于传统的小样本学习任务,以实现更优的分类性能。此外,受对比学习的启发,我们引入了一种基于该模块的优化策略,旨在获得更适应分类任务的原型表示。通过利用数据实例之间的内在结构和相互关系,我们的方法增强了所获取嵌入的判别能力,从而在小样本分类任务中表现出更高的有效性和精确度。我们在多个常用的小样本图像分类基准数据集上评估了所提出的方法,并通过消融实验和可视化技术进行了全面分析。实验结果表明,我们的方法显著优于当前最先进的方法。
Wang, Y.; Yao, Q.; Kwok, J. T.; and Ni, L. M. 2020. Generalizing from a few examples: A survey on few-shot learning. ACM computing surveys (csur), 53(3): 1–34. ↩︎
Zhang, R.; Che, T.; Ghahramani, Z.; Bengio, Y.; and Song, Y. 2018. Metagan: An adversarial approach to few-shot learning. Advances in neural information processing systems, 31. ↩︎
Zhang, H.; Cisse, M.; Dauphin, Y. N.; and Lopez-Paz, D. 2017. Mixup: Beyond empirical risk minimization. arXiv preprint arXiv:1710.09412. ↩︎ ↩︎
Chen, Z.; Fu, Y.; Zhang, Y.; Jiang, Y.-G.; Xue, X.; and Sigal, L. 2019. Multi-level semantic feature augmentation for one-shot learning. IEEE Transactions on Image Processing, 28(9): 4594–4605. ↩︎
Schwartz, E.; Karlinsky, L.; Shtok, J.; Harary, S.; Marder, M.; Kumar, A.; Feris, R.; Giryes, R.; and Bronstein, A. 2018. Delta-encoder: an effective sample synthesis method for few-shot object recognition. Advances in neural information processing systems, 31. ↩︎
Yang, S.; Liu, L.; and Xu, M. 2021. Free lunch for few-shot learning: Distribution calibration. arXiv preprint arXiv:2101.06395. ↩︎
Li, G.; Zheng, C.; and Su, B. 2022. Transductive distribution calibration for few-shot learning. Neurocomputing, 500: 604–615. ↩︎
Hou, R.; Chang, H.; Ma, B.; Shan, S.; and Chen, X. 2019. Cross attention network for few-shot classification. Advances in neural information processing systems, 32. ↩︎ ↩︎ ↩︎
Li, W.; Wang, L.; Xu, J.; Huo, J.; Gao, Y.; and Luo, J. 2019. Revisiting local descriptor based image-to-class measure for few-shot learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 7260–7268. ↩︎ ↩︎ ↩︎
Liu, Y.; Zheng, T.; Song, J.; Cai, D.; and He, X. 2022b. DMN4: Few-shot learning via discriminative mutual nearest neighbor neural network. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, 1828–1836. ↩︎ ↩︎ ↩︎
Liu, Y.; Zhang, W.; Xiang, C.; Zheng, T.; Cai, D.; and He, X. 2022a. Learning to affiliate: Mutual centralized learning for few-shot classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 14411–14420. ↩︎ ↩︎
Snell, J.; Swersky, K.; and Zemel, R. 2017. Prototypical networks for few-shot learning. Advances in neural information processing systems, 30. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
Zhang, B.; Li, X.; Ye, Y.; Huang, Z.; and Zhang, L. 2021. Prototype completion with primitive knowledge for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 3754–3762. ↩︎ ↩︎
Zhou, K.; Yang, J.; Loy, C. C.; and Liu, Z. 2022. Learning to prompt for vision-language models. International Journal of Computer Vision, 130(9): 2337–2342. ↩︎ ↩︎ ↩︎
Gao, P.; Geng, S.; Zhang, R.; Ma, T.; Fang, R.; Zhang, Y.; Li, H.; and Qiao, Y. 2021. Clip-adapter: Better vision-language models with feature adapters. arXiv preprint arXiv:2110.04544. ↩︎ ↩︎
Koch, G.; Zemel, R.; Salakhutdinov, R.; et al. 2015. Siamese neural networks for one-shot image recognition. In ICML deep learning workshop, volume 2. Lille. ↩︎
Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P. H.; and Hospedales, T. M. 2018. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE conference on computer vision and pattern recognition, 1199–1208. ↩︎
Luo, X.; Wei, L.; Wen, L.; Yang, J.; Xie, L.; Xu, Z.; and Tian, Q. 2021. Rectifying the shortcut learning of background for few-shot learning. Advances in Neural Information Processing Systems, 34: 13073–13085. ↩︎
He, Y.; Liang, W.; Zhao, D.; Zhou, H.-Y.; Ge, W.; Yu, Y.; and Zhang, W. 2022. Attribute surrogates learning and spectral tokens pooling in transformers for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 9119–9129. ↩︎ ↩︎
Hiller, M.; Ma, R.; Harandi, M.; and Drummond, T. 2022. Rethinking generalization in few-shot classification. Advances in Neural Information Processing Systems, 35: 3582–3595. ↩︎ ↩︎
Zhang, R.; Zhang, W.; Fang, R.; Gao, P.; Li, K.; Dai, J.; Qiao, Y.; and Li, H. 2022b. Tip-adapter: Training-free adaption of clip for few-shot classification. In European Conference on Computer Vision, 493–510. Springer. ↩︎
Radford, A.; Kim, J. W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. 2021. Learning transferable visual models from natural language supervision. In International conference on machine learning, 8748–8763. PMLR. ↩︎ ↩︎
Liu, Z.; Miao, Z.; Zhan, X.; Wang, J.; Gong, B.; and Yu, S. X. 2019. Large-scale long-tailed recognition in an open world. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2537–2546. ↩︎
Zhu, L.; and Yang, Y. 2020. Inflated episodic memory with region self-attention for long-tailed visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 4344–4353. ↩︎
Arjovsky, M.; Bottou, L.; Gulrajani, I.; and Lopez-Paz, D. 2019. Invariant risk minimization. arXiv preprint arXiv:1907.02893. ↩︎
Huang, Z.; Wang, H.; Xing, E. P.; and Huang, D. 2020. Self-challenging improves cross-domain generalization. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part II 16, 124–140. Springer. ↩︎
Peng, X.; Huang, Z.; Sun, X.; and Saenko, K. 2019. Domain agnostic learning with disentangled representations. In International Conference on Machine Learning, 5102–5112. PMLR. ↩︎
Hou, Z.; Yu, B.; and Tao, D. 2022. Batchformer: Learning to explore sample relationships for robust representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 7256–7266. ↩︎
Wu, Z.; Xiong, Y.; Yu, S. X.; and Lin, D. 2018. Unsupervised feature learning via non-parametric instance discrimination. In Proceedings of the IEEE conference on computer vision and pattern recognition, 3733–3742. ↩︎
He, K.; Fan, H.; Wu, Y.; Xie, S.; and Girshick, R. 2020. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 9729–9738. ↩︎ ↩︎ ↩︎
Chen, T.; Kornblith, S.; Norouzi, M.; and Hinton, G. 2020. A simple framework for contrastive learning of visual representations. In International conference on machine learning, 1597–1607. PMLR. ↩︎ ↩︎
Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D.; et al. 2016. Matching networks for one shot learning. Advances in neural information processing systems, 29. ↩︎ ↩︎
Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. 2020. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929. ↩︎
Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, Ł.; and Polosukhin, I. 2017. Attention is all you need. Advances in neural information processing systems, 30. ↩︎ ↩︎
Hadsell, R.; Chopra, S.; and LeCun, Y. 2006. Dimensionality reduction by learning an invariant mapping. In 2006 IEEE computer society conference on computer vision and pattern recognition (CVPR’06), volume 2, 1735–1742. IEEE. ↩︎
Wah, C.; Branson, S.; Welinder, P.; Perona, P.; and Belongie, S. 2011. The caltech-ucsd birds-200-2011 dataset. ↩︎
Kingma, D. P.; and Ba, J. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980. ↩︎
Finn, C.; Abbeel, P.; and Levine, S. 2017. Model-agnostic meta-learning for fast adaptation of deep networks. In International conference on machine learning, 1126–1135. PMLR. ↩︎
Zhang, C.; Cai, Y.; Lin, G.; and Shen, C. 2022a. Deepemd: Differentiable earth mover’s distance for few-shot learning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(5): 5632–5648. ↩︎
Le, D.; Nguyen, K. D.; Nguyen, K.; Tran, Q.-H.; Nguyen, R.; and Hua, B.-S. 2021. Poodle: Improving few-shot learning via penalizing out-of-distribution samples. Advances in Neural Information Processing Systems, 34: 23942–23955. ↩︎
Wertheimer, D.; Tang, L.; and Hariharan, B. 2021. Few-shot classification with feature map reconstruction networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 8012–8021. ↩︎
Huang, H.; Zhang, J.; Zhang, J.; Wu, Q.; and Xu, C. 2021. PTN: A poisson transfer network for semi-supervised few-shot learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, 1602–1609. ↩︎
Bendou, Y.; Hu, Y.; Lafargue, R.; Lioi, G.; Pasdeloup, B.; Pateux, S.; and Gripon, V. 2022. Easy—ensemble augmented-shot-y-shaped learning: State-of-the-art few-shot classification with simple components. Journal of Imaging, 8(7): 179. ↩︎
Lazarou, M.; Stathaki, T.; and Avrithis, Y. 2021. Iterative label cleaning for transductive and semi-supervised few-shot learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 8751–8760. ↩︎
Bateni, P.; Goyal, R.; Masrani, V.; Wood, F.; and Sigal, L. 2020. Improved few-shot visual classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 14493–14502. ↩︎
Van der Maaten, L.; and Hinton, G. 2008. Visualizing data using t-SNE. Journal of machine learning research, 9(11). ↩︎ ↩︎

















 629
629



 到【灌水乐园】发言
到【灌水乐园】发言








