





突破简单管线在小样本学习中的极限:外部数据和微调带来的影响
引用:Hu, Shell Xu, et al. “Pushing the limits of simple pipelines for few-shot learning: External data and fine-tuning make a difference.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
论文地址:下载地址
论文地代码:https://github.com/hushell/pmf_cvpr22
Abstract
少样本学习(Few-Shot Learning,FSL)是计算机视觉领域一个重要且热门的问题,已经激发了大量研究,这些研究方法从复杂的元学习方法到简单的迁移学习基线不一而足。我们致力于在实际中突破一种简单但有效的少样本图像分类管道的极限。为此,我们从神经网络架构的角度探索少样本学习,并提出了一个三阶段的管道:在外部数据上进行预训练,在标注的少样本任务上进行元训练,以及针对未见任务进行特定任务的微调。
我们研究的问题包括:
- 预训练外部数据如何提升 FSL 性能?
- 如何利用最先进的 Transformer 架构?
- 如何最佳地利用微调?
最终,我们证明了一个基于 Transformer 的简单管道在标准基准数据集上表现出令人惊讶的优秀性能,包括 Mini-ImageNet、CIFAR-FS、CDFSL 和 Meta-Dataset。我们的代码可在以下网址获取:https://github.com/hushell/pmf_cvpr22。
1. Introduction
主流的监督深度学习在拥有大量标注数据集的应用中取得了优异的结果。然而,在许多应用中,这一假设并不成立,因为数据(例如罕见类别)或人工标注的成本是难以克服的瓶颈。这种情况促使了少样本学习(Few-Shot Learning,FSL)领域的大量研究不断增长,旨在模拟人类从少量训练样本中学习新概念的能力。少样本学习的挑战已成为开发和测试各种复杂研究方法的沃土,包括度量学习 1 2、基于梯度的元学习 3、程序归纳 4、可微优化层 5、超网络 6、神经优化器 7、传导标签传播 8、神经损失学习 9、贝叶斯神经先验 10 等,以及其他方法 11。然而,基于所有这些技术进步,我们究竟取得了多少实际进展呢?
一些研究 12 13 14 15 16 17 探讨了简单的基线方法是否能够提供与复杂的最先进少样本学习方法相当的性能。虽然由于复杂学习方法 10 和简单基线方法的持续发展,目前尚无明确的结论,但趋势表明,与复杂方法相比,简单方法往往表现出令人惊讶的优秀性能。由于其简单性和高效性,这些简单方法在少样本学习的许多实际应用中得到了采用,例如从医学数据分析 18 到电子工程 19。
我们沿着这一研究方向展开,但进一步探讨了此前较少研究的影响简单少样本学习管道性能的因素。具体来说,我们以一个类似于 ProtoNet 1 的简单管道为起点,并研究三个在实践中重要的设计选择:预训练数据、神经网络架构以及元测试阶段的微调。
Source data 尽管少样本学习(FSL)解决的是小样本数据的问题,但实际上,FSL 研究几乎总是围绕如何将大规模源任务(即元训练,meta-train)的知识迁移到小规模目标任务(即元测试,meta-test)的算法展开。现有文献几乎总是控制源数据,以便仔细比较不同知识迁移机制的影响,例如从超网络 6 到基于梯度的元学习方法 3。虽然这对于推动复杂算法的研究非常有帮助,但它并没有回答这样的问题:源数据的选择如何影响性能?这一问题在视觉和模式识别的其他领域中已经被研究过 20 21 22,但在 FSL 中尚未得到研究。这对于 FSL 研究的实际应用者来说并不友好,因为他们可能希望了解,简单地更换源数据能否显著改善其应用性能,尤其是现有的大规模数据集已免费开放 23 24,而利用更多的外部源数据在实践中比实现复杂的最先进元学习方法更为容易。为此,我们研究了在外部数据上进行无监督预训练的影响——这一工作流程最近被称为利用“基础模型” 20——在 FSL 任务中的表现。这一小小的改变相比过去五年的 FSL 研究产生了显著的影响(见图 1)。尽管这可能违反了严格限定源数据集的 FSL 问题定义,但这一方法的高效性可能促使我们反思:这是否是值得关注的最佳问题定义?

图1. 预训练和架构如何影响少样本学习?
通过以下两种方法可以实现少样本学习:
a) 元学习(meta-learning)[62, 66];
b) 从在大规模外部数据上进行预训练的自监督基础模型中迁移学习(transfer learning)[18, 49]。
虽然大多数少样本学习(FSL)研究社区集中于前者,我们的研究表明后者可能更为有效,因为它能够使用更强大的架构,例如视觉Transformer(ViT)[25],并且可以与简单的元学习方法(如ProtoNet)相结合。
该图展示了从过去5年的少样本学习研究中汇总的结果,以及ProtoNet + ViT骨干网络 + 对比语言-图像预训练(CLIP)[49]的结果(黄色星标)。
为了突出预训练的重要性,该图还比较了ProtoNet + 随机初始化ViT(蓝色方块)的结果。
Neural Architecture 与源数据的情况类似,少样本学习(FSL)研究通常将神经网络架构限制在少数几个小型网络上,例如 CNN-4-64 和 ResNet-12。这部分是为了使 FSL 算法的比较更加公平,但这一特定网络集的选择也受到了用于训练的常见基准数据集(如 miniImageNet)的源数据集规模较小的限制。因此,FSL 中常用的网络架构在一定程度上已经与最先进的计算机视觉研究脱节。因此,我们提出问题:最先进的架构(例如视觉 Transformer 25)在多大程度上能够提升少样本学习的性能,特别是在结合更大的预训练数据集时?
Fine-tuning 在少样本学习(FSL)文献中,关于在模型部署阶段(即元测试,meta-test)是否需要对单个任务进行某种形式的微调,研究存在一定的分歧。一些研究支持微调 3 7 26,而另一些研究则认为固定的特征表示已经足够 5 1 17。我们也对这一问题进行了研究,并提出微调对于将基础模型(foundation models)部署到分布外任务(out-of-distribution tasks)是必要的。我们还通过引入一种算法改进来优化微调,即通过验证集自动选择学习率,从而为跨领域少样本学习提供了一个性能更优的管道。
总而言之,我们通过研究一个简单管道的设计选择 1(如图 2 所示)推动了少样本学习的发展,而非开发新的算法。我们回答了以下问题:预训练如何影响 FSL?近期的 Transformer 架构能否适应 FSL?以及如何最佳地利用微调?基于这一分析,我们展示了一个新的 FSL 基线,该基线在性能上超越了当前的最先进方法,同时保持了简单性和易于实现的特点。
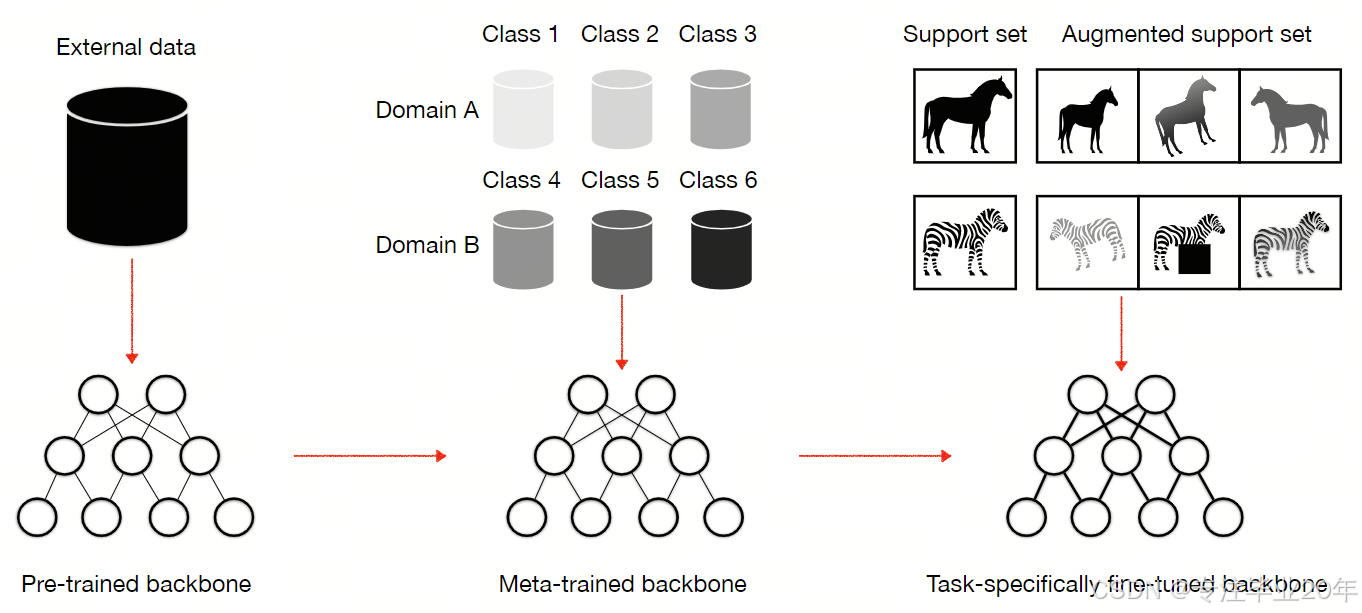
图2. 概述 – 我们研究的简单预训练、元训练和微调流程的示意图。
沿着红色箭头,该流程将一个预训练的特征骨干网络转化为特定任务的网络。
2. Related Work
2.1 Few-shot Learning
少样本学习(Few-shot Learning,FSL)现已成为一个深入且广泛研究的领域,规模庞大,难以在此进行详细回顾。我们建议参考相关综述以获得全面概览 27 11。一个关键点是,尽管名称为“少样本学习”,几乎所有 FSL 方法都提供了从大量源数据迁移知识到稀疏标注目标类别集合的算法。该领域的大量研究归入元学习(meta-learning)范畴 27,其目标是通过模拟少样本学习问题,从源数据集(即元训练,meta-train)中构建一个数据高效的学习器,然后将定制的学习器部署到目标数据集(即元测试,meta-test)上。生成的学习器可能表现为一种初始化 3、学习到的度量 1、贝叶斯先验 10 或优化器 7。
2.2 Simple-but-effective baselines
与大量复杂的少样本学习(FSL)算法 27 11 竞争的同时,近期的一些研究提倡使用强大的基线方法,这些方法尽管更简单,但在性能上可以相媲美。这些方法通常基于迁移学习 28 的管道。在源数据上应用传统的深度学习模型后,通过在固定表示上训练简单的线性分类器 12 15 16 或中心分类器 17,或者同时微调特征主干网络 14,来适应少样本目标数据。这些方法大多使用标准化的 FSL 源数据集(如 miniImageNet)和架构(如 ResNet-12 和 WRN-10-28),以便直接比较所提出的简单基线方法与复杂算法。与此相反,我们的目标是探索通过利用其他可用的预训练数据集和架构,可以将实际的 FSL 性能提升到何种程度。
一些研究使用更大规模的数据集(如 ImageNet1K 13 或 ImageNet21K 14)评估了 FSL。然而,由于同时更改了源数据集和目标数据集,这并未明确说明源数据的选择或规模如何影响给定的目标问题——而这是我们在此回答的问题。其他研究探讨了在元学习之前使用常规预训练 13 或将其作为元学习期间的正则化方法 29 的影响,但未利用额外的数据。
2.3 Bigger data and architectures
在标准监督学习 22 和自监督学习 20 21 的视觉领域,以及视觉以外的模式识别应用 30 20 31 32 中,源数据集的影响已经被广泛研究。然而,在少样本学习(FSL)中,这一方面却未得到广泛评估,这一遗漏令人意外。正如我们将看到的,调整源数据集可能是提高实际 FSL 性能的最简单方法。同样,现有的 FSL 方法几乎完全基于少数不太常见的架构(例如 Conv-4-64 和 ResNet-12),这可能是由于早期的小型数据集(如 Omniglot 3 33)上的实验设置所导致的。Transformers 在 FSL 中的应用较少,主要用于度量学习 34,而非特征提取。我们研究了如何训练和应用最近的 Transformer 特征提取器到 FSL 尤其是结合在更大源数据集上预训练的基础模型(foundation model)20 时的表现。
2.4 Self-supervised & few-shot
我们的管道扩展了自监督研究社区中典型的“无监督预训练 → 监督微调”工作流程 35 36。这一流程最近在低样本监督学习中表现出了强大的性能 37 38 39。然而,由于典型评估实践和基准的不同,针对数据高效学习的自监督学习(SSL)方法和少样本学习(FSL)方法之间的直接比较仍然有限。例如,许多 SSL 评估在 ImageNet 上执行无监督表示学习,然后在 ImageNet 内进行少样本监督学习 37 38,这违反了 FSL 社区通常要求的源数据和目标数据集不相交的原则。本文的一个贡献是为 SSL 和 FSL 方法提供一定程度的比较以及两者的结合。例如,我们在 MetaDataset、CDFSL 和 Teaser 图 1 的结果中使用了不相交的源数据和目标数据,但受益于外部自监督预训练。
2.5 Cross-domain few-shot
少样本学习(FSL)的一种变体具有特别的实际意义,即跨领域少样本学习(cross-domain few-shot learning,CDFSL)40,其中源数据集/元训练数据集与目标数据集/元测试数据集存在显著差异。这比标准的同领域设置更具挑战性,但也更具实际相关性。这是因为在许多对 FSL 感兴趣的场景中,例如医学或地球观测成像 40,FSL 的目标数据与可用的源数据(如 (mini)ImageNet 23)之间存在显著差异。这类问题的主要基准包括 CDFSL 40 和 meta-dataset 26。
3. A Simple Pipeline for FSL
Problem formulation
少样本学习(Few-Shot Learning,FSL)的目标是在只有少量标注样本的情况下学习一个模型。Vinyals 等人 33 从元学习的角度提出了一种广泛采用的 FSL 形式化方法,其中假设模型应基于以前见过的许多相似少样本任务的经验来解决新的少样本任务。因此,FSL 问题通常分为两个阶段:在一组训练任务的分布上对少样本学习器进行元训练(meta-training),以及通过在新颖的少样本任务上评估生成的学习器来进行元测试(meta-testing)。在每个阶段中,数据以“情景式”(episodic)的方式到达,其中每个任务的“训练集”和“测试集”分别称为支持集(support set)和查询集(query set),以避免术语混淆。在分类任务中,一个情景的难度级别通常描述为 K K K-way- N N N-shot,这意味着在支持集中,每个类别有 N N N 个样本,目标是为 K K K 个类别学习一个分类器。通常为每个难度级别单独学习一个模型,但更现实的设置 26 是为不同的 K K K 和 N N N 学习一个全局模型。这种情况有时被称为 various-way-various-shot。在本文中,我们关注这种更实际的设置。这也是我们倾向于使用简单管道而非复杂的元学习器的原因,后者可能难以扩展到 various-way-various-shot 的设置中。
另一种针对小样本学习的方法出现在迁移学习 41 28 和自监督学习 20 42 文献中。在这种方法中,首先使用大规模源数据对模型进行预训练,然后将其重新用于目标任务中的稀疏数据场景。预训练步骤旨在减少适应阶段中学习目标问题的样本复杂度。
尽管通常分别研究,这两类方法都为从源数据向目标少样本问题传递知识提供了机制。为了实现高性能的少样本学习,我们将预训练(通常在辅助的未标注数据上进行,这些数据是免费且随处可得的)和元学习(使用带标签的情景式训练)结合在一个简单的顺序管道中,并使用单一的特征提取器主干网络。
我们的管道包含三个阶段:
- 使用自监督损失在未标注的外部数据上预训练特征主干网络;
- 使用 ProtoNet 1 损失在带标签的模拟少样本任务上对特征主干网络进行元训练;
- 在新颖的少样本任务上部署特征主干网络,并在每个任务的增强支持集上选择性地进行微调。
我们的管道的示意图如图 2 所示,我们称之为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1317
1317



 到【灌水乐园】发言
到【灌水乐园】发言








