





 超级会员免费看
超级会员免费看


一、文章主要内容总结
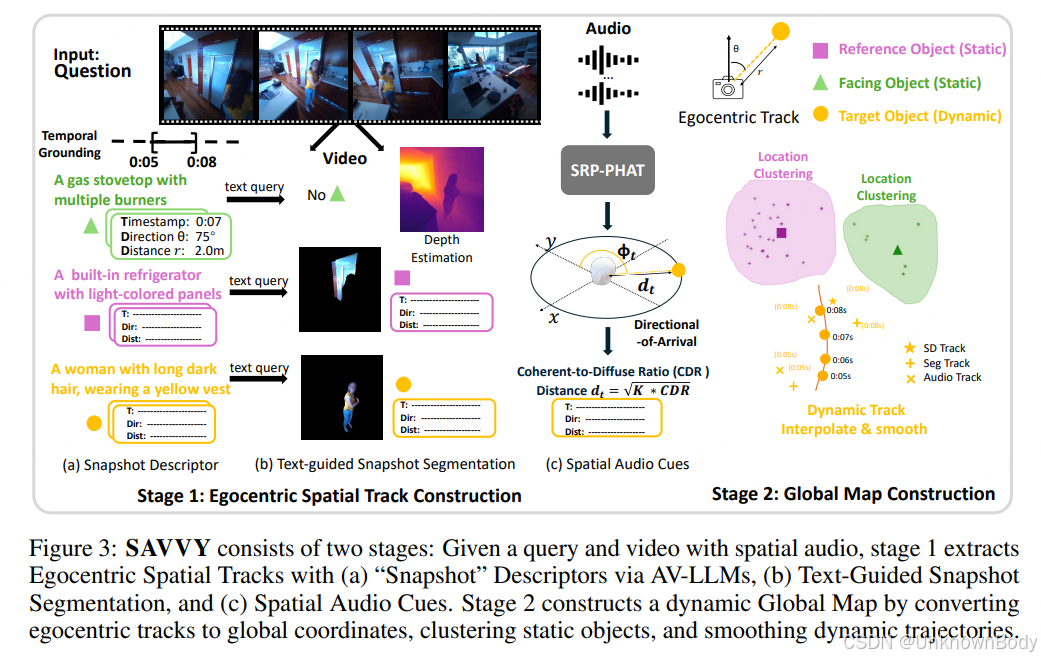
本文聚焦动态视听环境下的3D空间推理问题,现有视听大模型(AV-LLMs)多局限于静态或2D场景,且忽视空间音频的作用。为此,作者提出两大核心贡献:一是构建首个动态3D空间推理基准数据集SAVVY-Bench,涵盖数千条问答对,支持自我中心(以相机为视角)和他者中心(以固定物体为视角)两类查询,同时融合多通道空间音频与视频模态;二是设计无训练依赖的推理流水线SAVVY,通过自我中心空间轨迹估计和动态全局地图构建两个阶段,整合视听线索与坐标转换,显著提升AV-LLMs的空间推理性能。实验表明,SAVVY在SAVVY-Bench上超越现有主流AV-LLMs,较Gemini-2.5 Pro的整体问答准确率提升7.1%。
二、核心创新点
- 首个动态3D视听空间推理基准:SAVVY-Bench首次覆盖动态多房间场景,同时支持自我中心和他者中心视角,兼顾方向与距离推理,整合空间音频模态以弥补视觉视野局限。
- 无训练依赖的模块化推理流水线:SAVVY无需额外训练,通过快照描述符、文本引导分割、空间音频线索提取目标轨迹,再聚合为全局动态地图,实现跨视角空间推理。
- 多模态融合的空间线索利用:首次系统整合视觉分割、AV-LLM语义理解、多通道音频的方向/距离估计,解决动态目标跟踪和视角转换难题。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 447
447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











