








 超级会员免费看
超级会员免费看


文章核心内容、创新点总结及关键部分翻译
一、主要内容总结
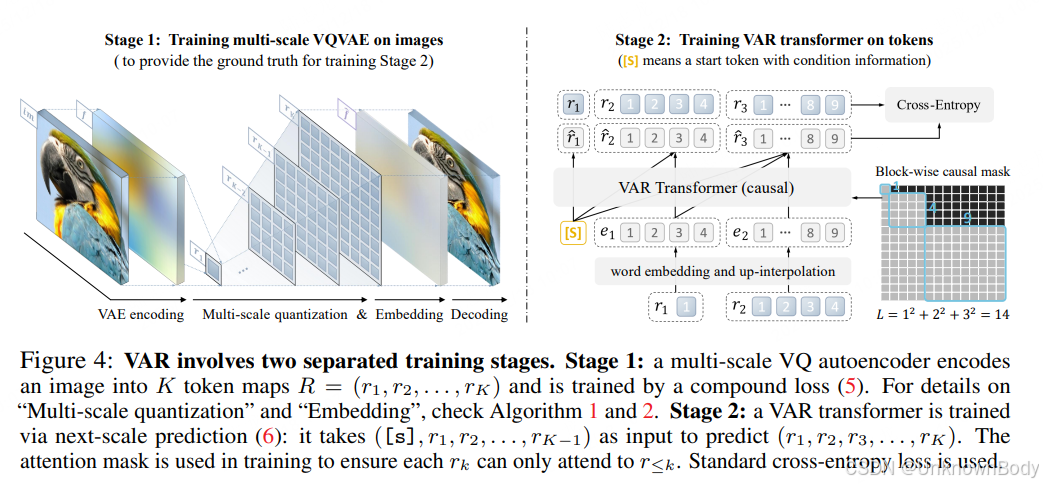
本文提出了一种名为视觉自回归建模(Visual AutoRegressive, VAR)的新型图像生成框架,重新定义了图像上的自回归学习范式。传统自回归模型采用“逐token预测”(如光栅扫描顺序),而VAR创新性地采用“逐尺度预测”(next-scale/next-resolution prediction),遵循从粗到细的生成逻辑,先构建图像全局结构,再逐步补充局部细节。
研究通过两阶段训练实现:第一阶段训练多尺度VQVAE,将图像编码为多尺度token图;第二阶段基于GPT-2类Transformer架构,训练模型根据前序尺度token图预测下一更高分辨率的token图。在ImageNet数据集上的实验表明,VAR在256×256和512×512图像生成任务中表现优异,不仅大幅超越传统自回归模型,还在图像质量(FID/IS指标)、推理速度、数据效率和可扩展性上优于扩散Transformer(DiT)等主流模型。此外,VAR展现出类LLM的幂律缩放特性和零样本泛化能力,可直接应用于图像修复、扩展和编辑等下游任务。
二、核心创新点
- 范式革新:将图像自回归学习从“逐token预测”转变为“逐尺度预测”,以完整token图为自回归单元,契合人类视觉感知的层级特性,解决了传统方法破

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 636
636

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











