







 超级会员免费看
超级会员免费看
该文章提出了多语言拼写错误生成算法MULTYPO,通过模拟不同语言键盘布局下的人类输入错误,系统评估了18个开源大语言模型在多语言拼写错误下的鲁棒性,揭示了模型在噪声输入下的性能变化规律及关键影响因素。
一、文章主要内容
1. 研究背景与问题
- 现有大语言模型(LLMs)评估多基于无错误输入,而现实场景中用户多语言键盘输入常存在拼写错误(typos),导致模型真实性能被高估。
- 此前鲁棒性研究多聚焦英语的对抗性扰动,缺乏对多语言真实拼写错误的关注,且未结合语言专属键盘布局和输入习惯。
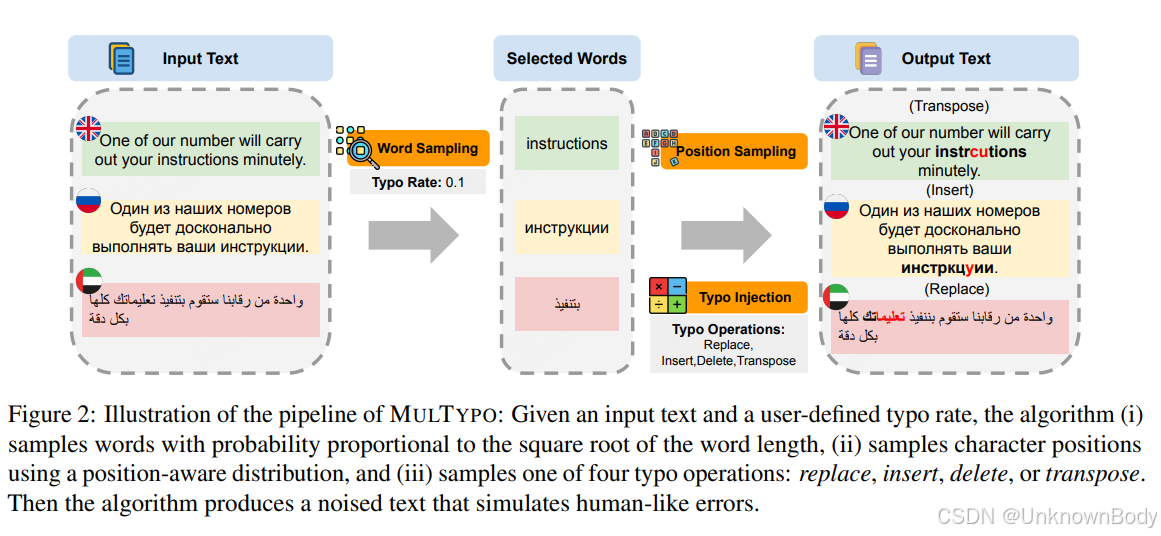
2. 核心方法:MULTYPO算法
- 设计逻辑:基于7个语系、12种语言的键盘布局,模拟人类四种典型拼写错误(替换、插入、删除、交换相邻字符)。
- 关键特性:
- 忽略数字相关文本,避免因数值篡改影响任务评估(如数学推理题)。
- 按单词长度平方根比例抽样添加错误,符合长单词更易出错的实证规律。
- 通过人类评估验证:在7种语言中,6种语言下MULTYPO生成的错误比随机错误更贴近人类真实输入(如德语中自然度评分8.93 vs 5.27)。
</

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1390
1390

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











