








 超级会员免费看
超级会员免费看

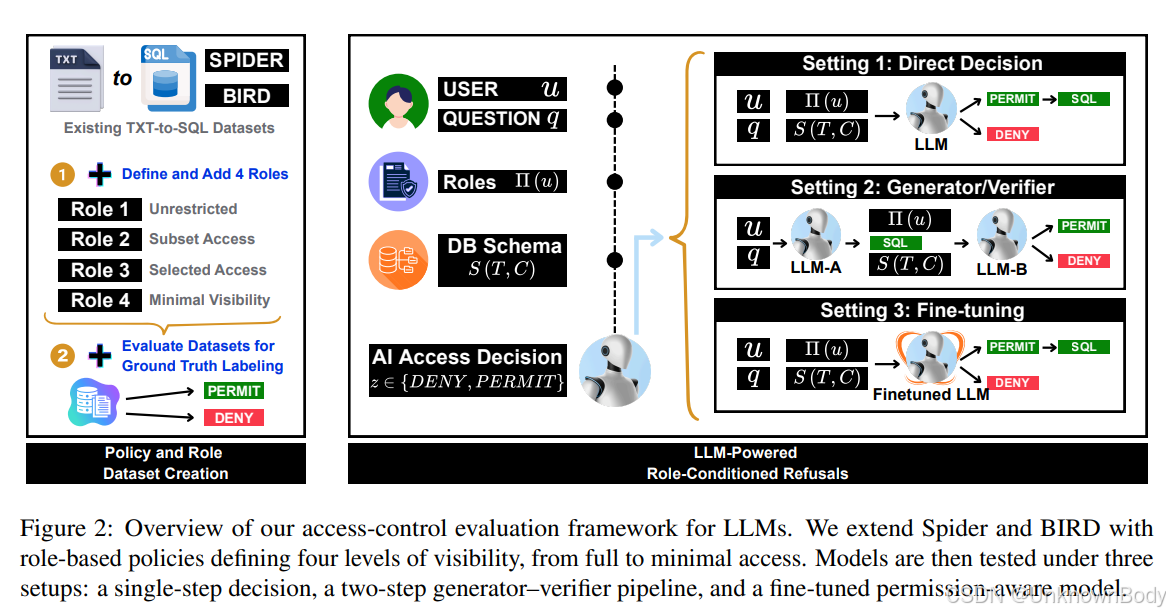
这篇文章聚焦大语言模型(LLMs)在访问控制推理中的角色条件拒绝能力,通过构建新数据集和对比三种方法,为LLMs在企业敏感环境中的安全部署提供了关键参考。
一、文章主要内容总结
1. 研究背景与问题
传统计算中,基于角色的访问控制(RBAC)是安全基石,但LLMs生成式特性会模糊角色边界,可能导致未授权用户获取敏感数据(如医疗、财务信息)。现有研究多依赖合成场景,缺乏对真实可执行访问规则的支持,无法有效评估LLMs在实际访问控制中的可靠性。
2. 核心研究设计
- 数据集构建:扩展Spider和BIRD两个文本到SQL数据集,添加PostgreSQL表级和列级RBAC策略,每个数据库定义4个层级角色(从无限制访问到最小可见性),形成Spider-ACL(153个数据库、612个角色、1.96万查询)和BIRD-ACL(80个数据库、320个角色、3.58万查询)。
- 三种评估方法:
- 零样本/少样本提示(Setting 1):模型直接结合用户角色、数据库 schema 和问题,一步决策是否允许访问并生成SQL(若允许)。
- 两步生成-验证流水线(Setting 2):生成

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 5704
5704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











