








 超级会员免费看
超级会员免费看

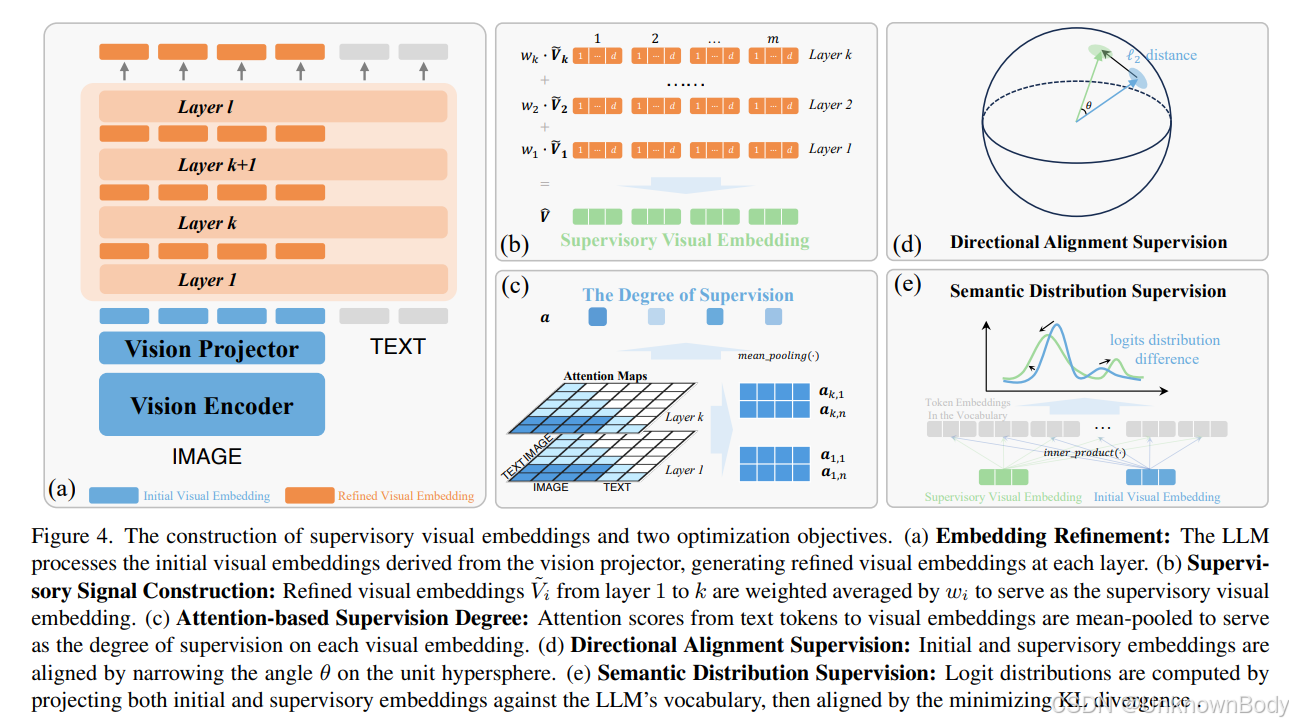
一、主要内容
本文聚焦多模态大型语言模型(MLLMs)中的视觉-文本模态对齐问题。主流MLLMs通过视觉投影仪连接预训练视觉编码器与大型语言模型(LLMs)实现视觉理解,但现有方法仅对文本输出施加自回归监督,忽视了对视觉嵌入的直接监督,导致模态对齐效果受限。
研究首先分析了MLLMs的视觉感知过程:通过余弦相似度计算发现,视觉投影仪生成的初始视觉嵌入中,部分可匹配到反映图像 patch 属性(颜色、形状等)的文本 token,但仍有大量嵌入对应不规则 token;而LLM浅层会逐步优化这些嵌入,使其与更有意义的文本 token 对齐,深层则倾向于匹配结束符 </s>。基于此发现,本文提出BASIC方法,利用LLM浅层的精炼视觉嵌入作为监督信号,从方向对齐和语义分布两个维度引导初始视觉嵌入优化。
实验中,以CLIP-ViT-L/14-336px为视觉编码器、两层MLP为视觉投影仪、Vicuna-v1.5为LLM,在LLaVA系列数据集上完成预训练与指令微调,并在VQA-v2、GQA等8个基准测试中验证效果。结果显示,BASIC在多数任务上性能优于LLaVA-1.5等主流模型,且在不同LLM与视觉编码器组合下均表现稳定。
二、创新点
- 机制分析创新:系统分析了LLM不同层中视觉嵌入与文本 token 嵌入的关联,揭示了MLLMs的内部视

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











