








 超级会员免费看
超级会员免费看

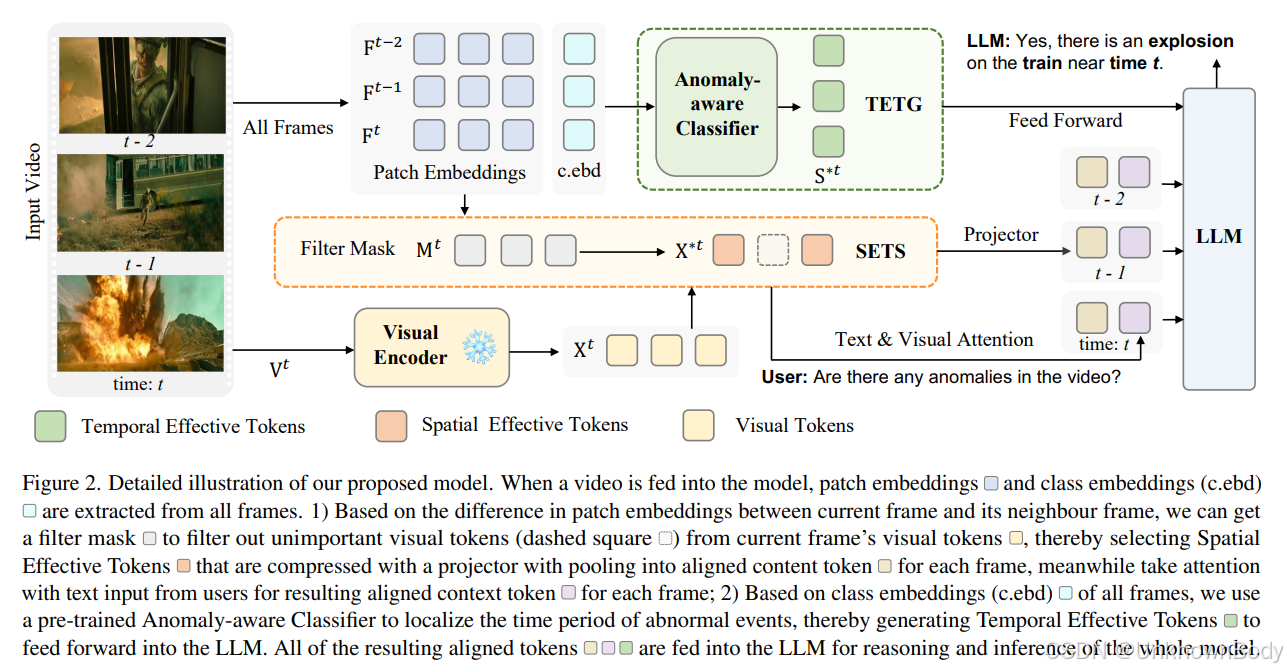
一、文章主要内容
本文聚焦视频异常事件理解这一关键且具挑战性的任务,针对现有多模态大语言模型(MLLMs)在处理视频异常时因异常事件时空稀疏性、冗余信息干扰导致性能欠佳的问题,提出了名为VA - GPT的新型多模态大语言模型,具体内容如下:
- 核心问题:传统视频异常检测方法存在封闭集检测分类局限、词汇量有限难以应对未知场景的问题;现有MLLMs虽在通用视频分析表现良好,但无法有效对齐异常区域与相关描述、精准识别异常时间区间,因它们平等对待所有潜在 tokens,冗余 tokens 影响性能。
- 模型架构:VA - GPT 包含空间有效 token 选择(SETS)和时间有效 token 生成(TETG)两大核心模块。SETS 通过计算相邻帧补丁嵌入差异,筛选出变化大的区域作为空间有效 token,去除冗余;TETG 利用轻量级预训练分类器为每帧分配异常置信度,生成包含异常时间区间的时间有效 token,输入LLM 以增强时间推理能力。
- 数据集与训练:构建用于微调视频异常感知 MLLMs 的指令遵循数据集,基于 UCF - Crime 数据集,包含 4077 个视频和 7730 张图像;设计两阶段训练策略,先用异常视频数据微调增强 LLM 异常感知,再用空间有效 token 微调优化空间上下文理解。
- 实验评估</

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 417
417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











