








 超级会员免费看
超级会员免费看

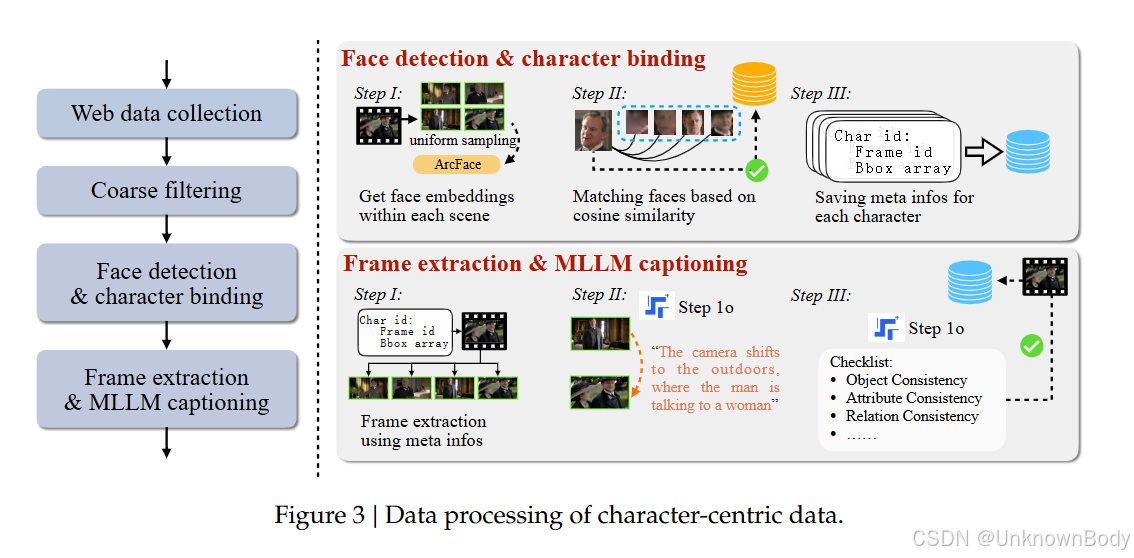
文章主要内容总结
本文介绍了NextStep-1,这是一款用于文本到图像生成的自回归模型,旨在推动自回归范式在图像生成领域的发展。该模型由140亿参数的Transformer骨干网络、1.57亿参数的流匹配头(flow matching head)和图像令牌器(image tokenizer)组成,通过统一离散文本令牌和连续图像令牌为单一序列,以“下一个令牌预测”为目标进行训练。
NextStep-1在文本到图像生成任务中表现出当前自回归模型的最优性能,在多个基准测试(如WISE、GenAI-Bench、DPG-Bench等)中取得优异成绩,尤其在高保真图像合成、复杂场景理解和世界知识整合方面能力突出。此外,基于该模型微调的NextStep-1-Edit在图像编辑任务中也展现出强竞争力,支持添加对象、背景修改、风格迁移等多种编辑需求。
为促进开放研究,作者团队计划开源模型代码和权重。
创新点
- 突破现有自回归模型局限:避免依赖繁重的扩散模型或向量量化(VQ)技术,直接处理连续图像令牌,消除量化损失和暴露偏差(exposure bias)问题。
- 统一多模态架构:将文本和图像令牌整合为单一序列,通过自回归目标((p(x)=\prod_{i=1}^{n} p(x_{i} | x_{<

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1002
1002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











