








 超级会员免费看
超级会员免费看

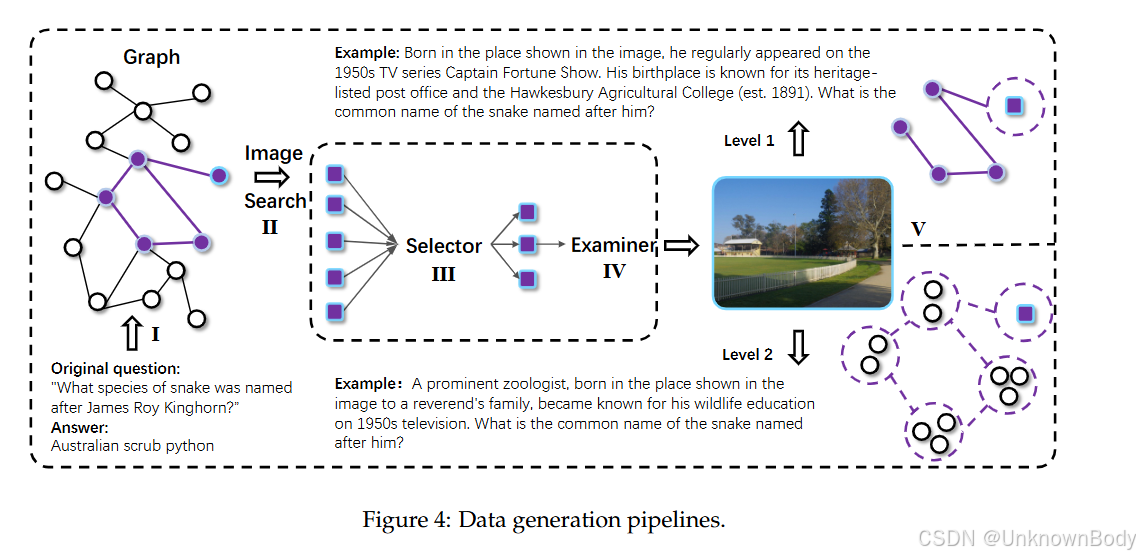
一、主要内容总结
本文介绍了WebWatcher,这是一种具备增强视觉-语言推理能力的多模态深度研究代理(multimodal Deep Research Agent),旨在解决现有Web代理多以文本为中心、忽视视觉信息的局限性。
-
研究背景:现有深度研究代理(如Deep Research)虽在文本信息检索上表现出色,但多为文本中心,难以处理需整合视觉信息的任务(如解析科学图表、分析图形等)。多模态深度研究需更强的感知、逻辑、知识推理能力及更复杂的工具使用能力,目前相关研究较少。
-
核心方法:
- WebWatcher设计:整合视觉-语言推理能力,支持多种工具(Web图像搜索、文本搜索、网页访问、代码解释器、OCR等),通过多步推理解决复杂任务。
- 数据集构建:提出BrowseComp-VL基准,包含视觉和文本的复杂信息检索任务,分Level 1(多跳推理,实体明确)和Level 2(实体模糊,需合成推理),覆盖5大领域17个子领域。
- 训练策略:使用高质量合成多模态轨迹进行冷启动训练(Supervised Fine-Tuning

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 134
134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











