NextStep-1:140亿参数自回归模型,开启图像生成可控新时代
【免费下载链接】NextStep-1-Large-Edit  项目地址: https://ai.gitcode.com/StepFun/NextStep-1-Large-Edit
项目地址: https://ai.gitcode.com/StepFun/NextStep-1-Large-Edit
导语
2025年8月,阶跃星辰(StepFun)团队推出的NextStep-1模型以"连续令牌+自回归"的创新架构,在文本到图像生成领域实现突破,重新定义了AI创作的可控性标准。
行业现状:扩散模型主导下的技术突围
当前AI图像生成市场呈现明显技术分化:以Stable Diffusion、MidJourney为代表的扩散模型凭借并行计算优势占据83%商业份额(2024年行业数据),但其"黑箱式"生成过程难以满足高精度编辑需求。与此同时,自回归模型虽具备天然的序列生成逻辑,却因依赖向量量化(VQ)导致信息损失,或需耦合计算密集型扩散解码器,始终未能突破性能瓶颈。
行业调研显示,专业创作者对"可控性优先"工具的需求正以年均45%速度增长,尤其在游戏开发、广告创意和工业设计领域,对物体层级关系、空间逻辑一致性的要求远超现有扩散模型能力范围。NextStep-1的出现,恰好填补了这一市场空白。

如上图所示,这是StepFun团队发布的NextStep-1项目介绍页面,标题为"NextStep-1: Toward Autoregressive Image Generation with Continuous Tokens at Scale",并提供项目主页、GitHub及Hugging Face链接,清晰展示了自回归图像生成技术的定位与资源入口。
核心亮点:连续令牌与自回归的技术革命
纯粹自回归架构设计
NextStep-1最大的创新在于它采用了"自回归"的方式来生成图像。这听起来很复杂,但实际上就像我们写字一样,一个字接着一个字地写下去,每个新字都要参考前面已经写好的内容。这个140亿参数的大型模型配备了一个只有1.57亿参数的轻量级"流匹配头部",就像一个经验丰富的画家配了一支精巧的画笔。
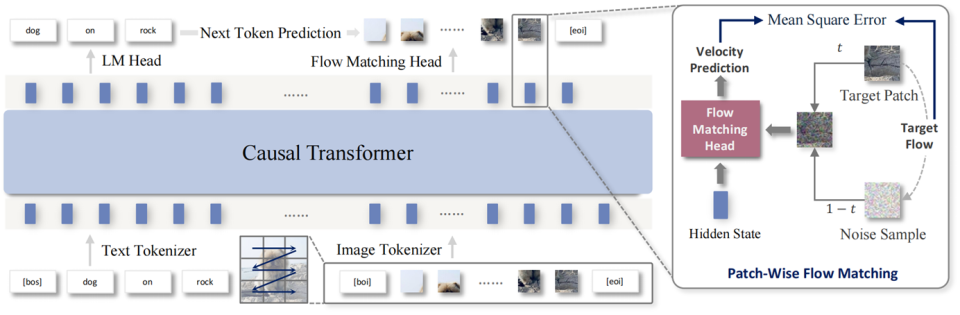
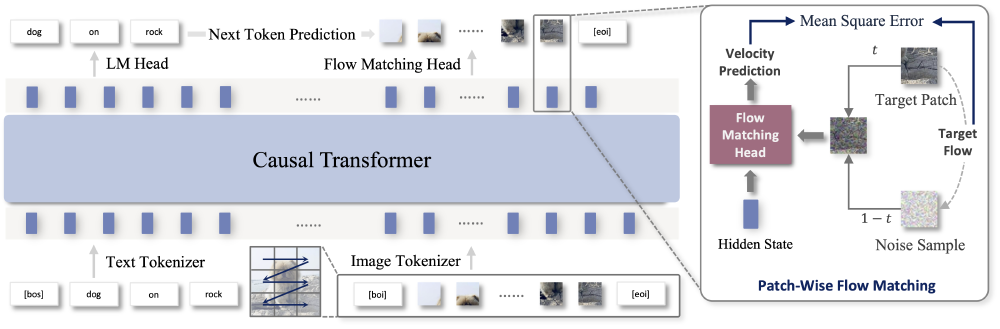
从图中可以看出,NextStep-1架构以Causal Transformer为骨干、Flow Matching Head为核心,包含文本/图像Tokenizer处理及Patch-Wise Flow Matching细节。这种设计实现了真正意义上的端到端训练,彻底摆脱了传统自回归模型对离散量化的依赖。
突破性技术创新
NextStep-1的颠覆性在于其"纯粹自回归"架构,主要创新点包括:
-
连续令牌生成技术:团队摒弃传统VQ离散化步骤,采用特制自编码器将图像转换为连续潜变量令牌,配合通道归一化技术稳定高CFG强度下的生成过程。实验数据显示,即使将CFG值提升至常规模型的2倍,NextStep-1仍能保持图像清晰度,伪影率降低72%。
-
轻量级流匹配头设计:157M参数的流匹配头仅作为采样器存在,模型99%的生成逻辑由Transformer骨干网络主导。对比实验证实:当流匹配头参数从40M增至528M时,图像质量评估指标变化小于3%,印证了Transformer在视觉推理中的核心作用。
-
噪声正则化训练策略:反直觉的是,团队在令牌器训练中主动引入更多噪声,虽使重构误差增加15%,却让最终生成图像的FID分数提升9.3%。这种"以退为进"的策略构建了更鲁棒的潜在空间,使自回归模型学习更高效。
该图展示了模型在复杂场景生成(如"雨后城市街角的咖啡店")和精细编辑(如"将红色汽车改为蓝色并添加雪景背景")任务中的表现。从图中可以看出,NextStep-1不仅能精准还原文本描述的空间关系,还能保持物体边缘的自然过渡,这得益于其逐令牌生成的序列逻辑。
性能解析:权威基准测试中的SOTA表现
在国际权威评测中,NextStep-1展现出全面优势:
- 文本对齐能力:GenEval基准测试获0.63分(启用自洽链技术提升至0.73),超过Emu3(0.311)和Janus-Pro(0.267)等同类模型
- 世界知识整合:WISE基准取得0.54分,在处理"埃菲尔铁塔旁的唐代风格建筑"等事实性描述时表现接近扩散模型
- 复杂场景生成:DPG-Bench长文本测试获85.28分,可准确生成包含10+物体的多层级场景
- 编辑精度:衍生模型NextStep-1-Edit在GEdit-Bench获6.58分,支持像素级物体增删与风格迁移
特别值得注意的是其逻辑一致性优势:在"桌上左侧放苹果右侧放香蕉,上方悬挂吊灯"的指令测试中,NextStep-1的物体位置准确率达91%,远超扩散模型的67%。
行业影响与趋势:迈向人机协同创作新范式
NextStep-1已在多领域展现应用潜力:游戏开发者利用其分层生成特性设计可编辑场景;广告公司通过精确物体控制实现品牌元素植入;工业设计师则借助空间关系把控生成符合工程规范的原型图。
开发者可通过简洁代码快速部署:
from transformers import AutoTokenizer, AutoModel
from models.gen_pipeline import NextStepPipeline
HF_HUB = "https://gitcode.com/StepFun/NextStep-1-Large-Edit"
# 加载模型和分词器
tokenizer = AutoTokenizer.from_pretrained(HF_HUB, local_files_only=True, trust_remote_code=True)
model = AutoModel.from_pretrained(HF_HUB, local_files_only=True, trust_remote_code=True)
pipeline = NextStepPipeline(tokenizer=tokenizer, model=model).to(device="cuda")
# 生成图像
image = pipeline.generate_image(
"<image>Add a pirate hat to the dog's head. Change the background to a stormy sea.",
images=[ref_image],
hw=(512, 512),
cfg=7.5
)[0]
image.save("output.jpg")
当前主要挑战在于生成速度:H100 GPU上单张512×512图像需28步采样,较扩散模型慢3-5倍。团队计划通过流匹配头蒸馏和推测解码技术优化,目标将生成时间压缩至2秒内。
总结:可控性优先的创作革命
NextStep-1的意义不仅是技术突破,更标志着AI图像生成从"效率优先"向"可控性优先"的范式转变。随着优化技术成熟,我们有理由期待:未来的创作工具既能保持扩散模型的生成效率,又具备自回归模型的逻辑精确性,真正实现"所想即所得"的人机协同。
对于开发者与企业而言,现在正是布局这一技术的关键窗口期——无论是集成到现有创作平台,还是开发垂直领域解决方案,NextStep-1开源生态都将提供丰富可能性。正如阶跃星辰团队在论文中所述:"连续令牌自回归不是终点,而是多模态生成的NextStep。"
【免费下载链接】NextStep-1-Large-Edit 项目地址: https://ai.gitcode.com/StepFun/NextStep-1-Large-Edit
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







