








 超级会员免费看
超级会员免费看

😎 网络新闻速览
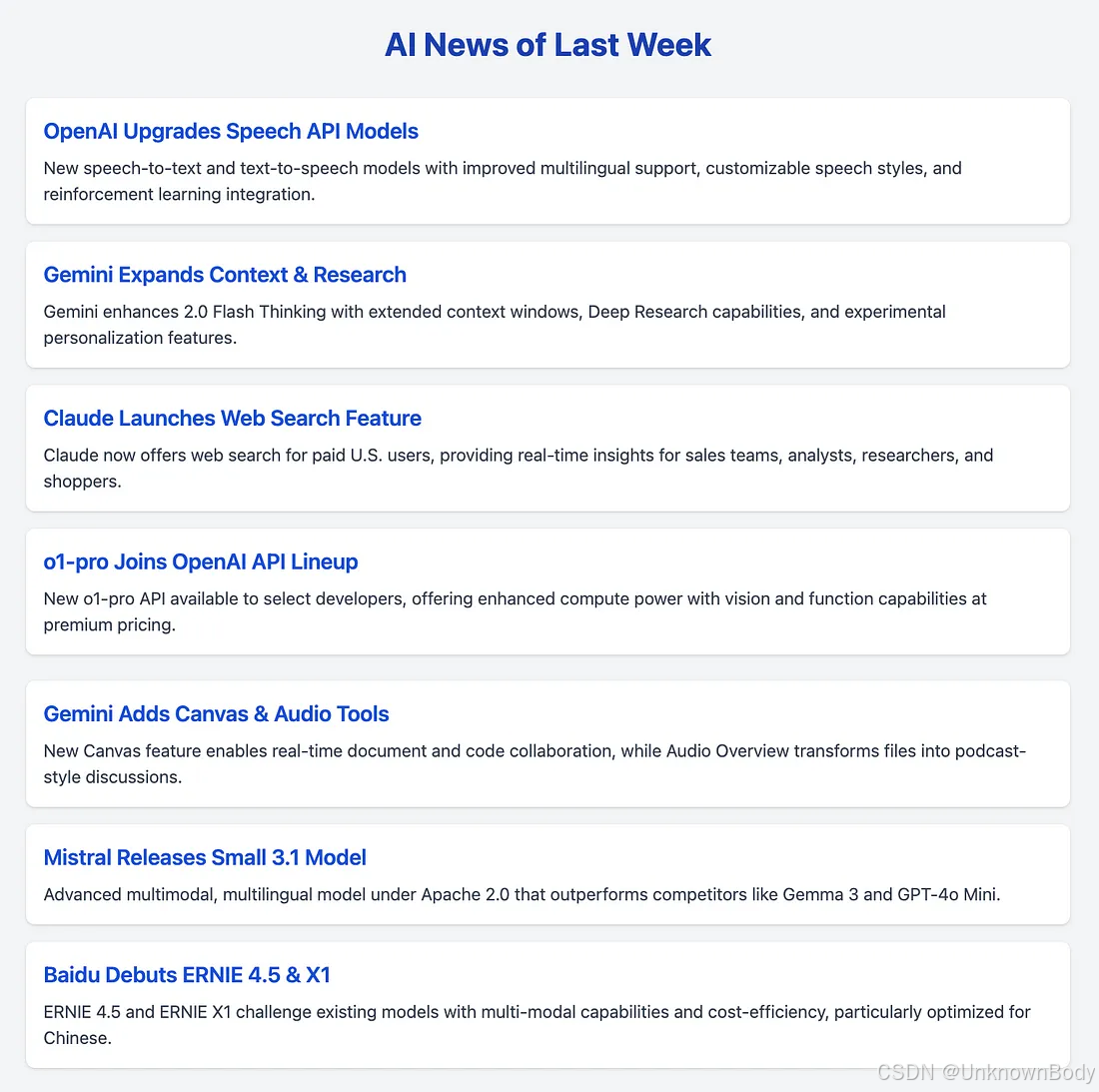
- OpenAI API推出下一代音频模型。OpenAI在其API中发布了全新的语音转文本和文本转语音模型,提升了语音代理的准确性和可靠性。新功能包括多语言覆盖能力提升、语音风格自定义,以及强化学习方法的整合。
- Gemini引入更智能的深度研究和扩展上下文的2.0闪电思考。Gemini应用推出重大升级,包括支持扩展上下文窗口的2.0闪电思考、更智能的深度研究功能,以及实验性个性化设置。
- Claude now可进行网络搜索。Claude开始支持网络搜索功能,提供更及时、相关的回答。该功能面向美国付费用户开放,赋能销售团队、金融分析师、研究人员和消费者获取实时洞察。
- o1-pro模型加入OpenAI API。OpenAI在API中引入o1-pro模型,通过提升算力提供更优质的响应。该模型面向1-5级开发者开放,支持视觉处理、函数调用和结构化输出,并与响应式API和批量API兼容。算力升级伴随成本增加:每百万输入token150美元,每百万输出token600美元。
- Gemini新增Canvas和音频概览功能。Gemini的新功能Canvas和音频概览(Audio Overview)提升了创意协作和理解能力。Canvas支持实时文档和代码优化,音频概览可将文件转换为沉浸式播客式讨论。
- Mistral发布Mistral Small 3.1。Mistral AI发布了遵循Apache 2.0

 订阅专栏 解锁全文
订阅专栏 解锁全文



















&spm=1001.2101.3001.5002&articleId=146589168&d=1&t=3&u=f90b6f8c71344b009fc7dd0aca50c10b)
 969
969

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











