




文章汉化系列目录
文章目录
摘要
从非结构化数据中提取商品属性是电子商务领域一个重要的信息抽取任务。它在商品推荐和商品知识库扩展等任务中起着重要作用。传统模型通常只利用文本模态信息,这不足以全面描述商品。在近年来,我们越来越多地看到使用多模态数据(如文本、图像和视频)来描述商品,这为更好地进行商品属性抽取提供了可能性。为此,我们提出了一种新颖的模型,称为基于多模态机器阅读理解的电子商务知识抽取方法(EKE-MMRC)。具体来说,该方法从现有知识库中发现缺失的属性并生成问题,然后将其与多模态描述打包,并编码为融合向量。随后,根据描述与属性的相关性进行解码,从融合向量中生成答案。最后,将相关性作为投票权重以确定答案。同时,我们基于公开的电子商务数据构建了一个用于该任务的数据集:电子商务多模态商品属性抽取数据集(E-MCAE)。此外,我们还在公开数据集上进行了实验。实验结果表明,所提出的方法是有效的,相较于当前单模态抽取方法(SOTA),性能提升超过了15%。
关键词: 多模态 · 机器阅读理解 · 信息抽取
1 引言
商品属性是由属性名称和属性值组成的一对。例如,(颜色,蓝色) 是一个属性,表示商品的颜色是蓝色。从非结构化数据中提取商品属性是电子商务领域一个重要的信息抽取任务。这些提取出的商品属性可以构成一个结构化的商品知识库。这些结构化数据被广泛应用于商品推荐中,从而大大提高了消费者与商家之间的交易效率。
近年来,从半结构化和非结构化文本中提取信息取得了突破性进展 [3,11]。在电子商务领域,这些方法也被成功用于从商品文本描述和用户评价中提取有价值的信息。在现实世界中,文本、视觉和听觉信息同样在电子商务平台中发挥着重要作用。多模态信息,即不同形式或来源的信息,帮助我们更好地理解世界。对于机器而言也是如此。例如,在机器翻译 [16]、机器对话 [12]、共指解析 [14] 等任务中,结合多模态数据后,模型能够处理更复杂和更贴近实际的任务。这与单模态模型相比,表现出明显的优势。多模态数据爆炸的现象在电子商务领域尤为显著。
因此,我们定义了一个新任务,即从多模态商品描述中提取商品属性。为了解决这一任务,我们基于公开的电子商务数据构建了一个数据集:电子商务多模态商品属性抽取数据集(E-MCAE)。该数据集包含5000件商品的结构化信息及其多模态描述。
针对上述挑战,我们提出了一种新颖的模型,称为基于多模态机器阅读理解的电子商务知识抽取方法(EKE-MMRC)。具体而言,该方法从现有知识库中发现缺失的属性并生成问题,然后将其与多模态描述打包并编码为融合向量。随后,根据描述与属性的相关性进行解码,从融合向量中生成答案。最后,将相关性作为投票权重以确定答案。
本文的贡献总结如下:
- 我们首次考虑从结合现有知识库的多模态描述中提取属性,并为这一具有挑战性的任务构建了一个新的数据集;
- 我们进行了广泛的实验,评估了我们模型相对于主流方法的表现。在构建的数据集上的实验结果表明,我们提出的方法是有效的,与基线相比,F1分数从51.52%显著提高到63.67%。
2 相关工作
2.1 机器阅读理解
教机器读取和理解大规模文本描述是自然语言理解的一个长期且有前景的目标。机器阅读理解(MRC)模型旨在完成这一任务。在这方面,近年来提出了多个基准数据集,推动了MRC的发展,包括SQuAD和Natural Questions。在过去一两年里,将信息抽取任务转化为MRC问答的趋势逐渐显现。
Levy 等人 [6] 将关系抽取任务形式化为QA(问答)任务。例如,关系 MARRY-WITH 可以映射为“谁是X的丈夫/妻子?”。受 [6] 的启发,我们的工作将属性值抽取形式化为多段式机器阅读理解任务。与上述工作不同的是,我们使用生成式模型来生成更为多样化的属性值,而不是在预定义的关系集上进行分类。
2.2 多模态信息抽取
现实世界中的信息通常以多模态形式出现,但由于技术问题,多模态研究进展较为缓慢。近年来,随着单模态研究的进展,多模态研究有了更加坚实的基础。多模态信息抽取是一种结合多模态学习与信息抽取技术的研究方向 [4]。
在实体链接任务中,Moon 等人 [10] 将图片与文本结合,用于实体消歧,并使用注意力机制融合图片、文本和知识库信息。最终,通过计算实体提及与知识库中实体的相似性获得实体链接结果。在链接预测任务中,IKRL [15] 通过扩展 TransE [1] 的能量函数,并添加实体的原始表示与实体图片表示之间的能量函数,来融合多模态信息。
我们的工作同样利用多模态信息来更好地进行知识抽取。Zhu 等人 [17] 尝试通过图片和文本信息抽取商品属性。与此工作相比,我们的模型在多模态特征融合方面表现更好,并且能够抽取出不在预定义字典中的属性。
3 框架
3.1 描述-问题对的准备
这一步将缺失的属性转换为问题。对于前一步找到的缺失属性,模型会将其打包成一个三元组。然后,根据简单的模板,从三元组中生成问题,将信息抽取 (IE) 任务转化为问答 (QA) 任务。基于这些查询三元组,我们可以使用简单的模板生成问题。与传统的问答任务不同,这一步并非旨在生成真实世界的问题,而是为了引导模型在描述中找到正确答案。
3.2 多模态编码器
多模态编码器用于提取和融合描述和问题的多模态特征。此组件的概览显示在图2的底部部分。
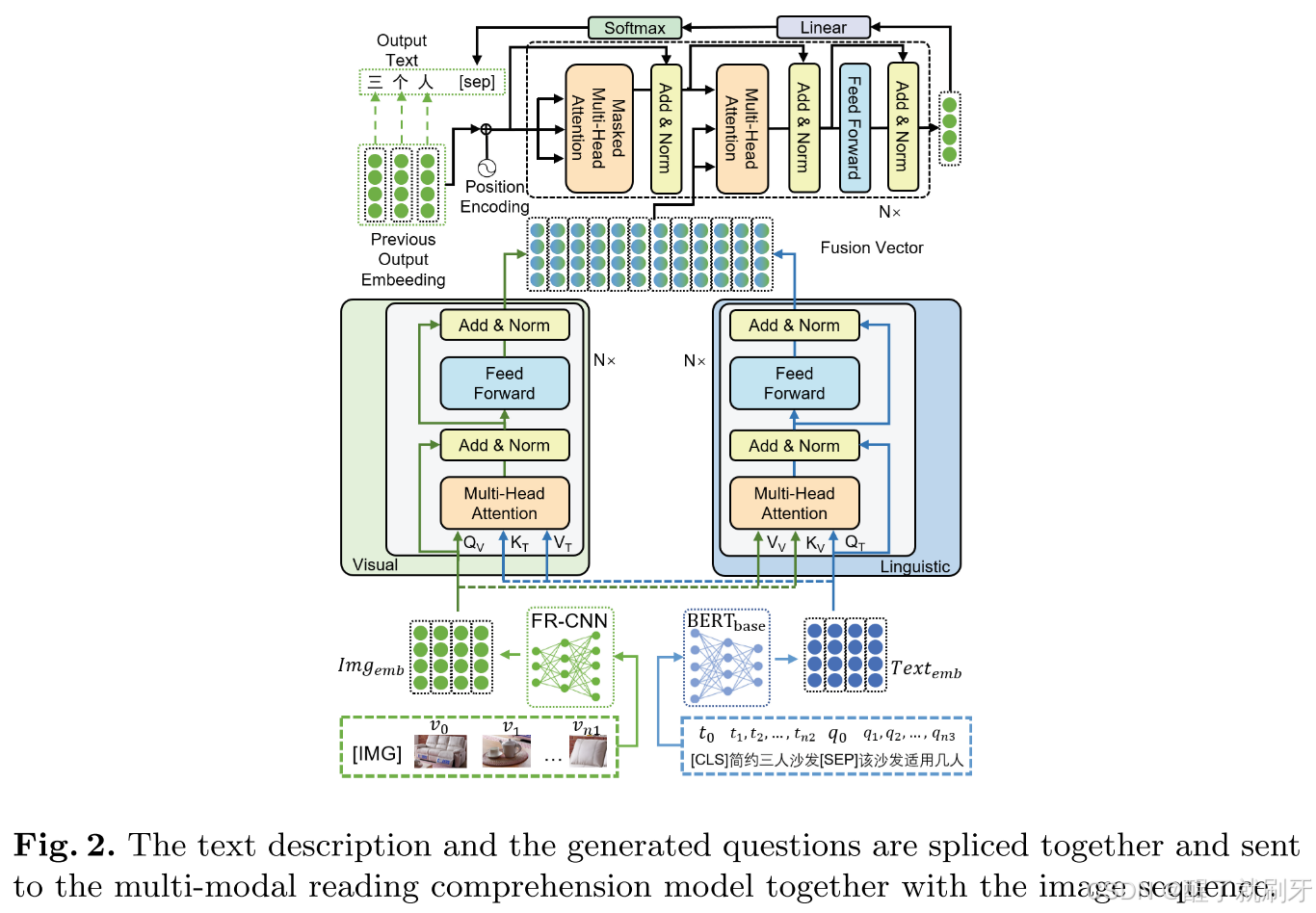
图2说明 文本描述与生成的问题被拼接在一起,并与图像序列一起送入多模态阅读理解模型。
基于Transformer的模态融合模块 近年来,基于Transformer的模型在各种任务中表现出色。具体来说,Transformer由多个相同的层连接而成,每一层包括两个子层。第一个子层是自注意力层,第二个子层是全连接层。在层与层之间加入了残差连接和层归一化。 我们在框架中引入了一种特殊的基于Transformer的多模态融合模型,如图2所示。我们将视觉和语言的第 l l l层隐藏层特征分别表示为 H l V H_l^V HlV和 H l T H_l^T HlT。模块按照标准Transformer编码器的方式计算查询(query)、键(key)和值(value)。然而,每种模态的Transformer会将键和值发送到另一模态的Transformer中。第 l l l层视觉Transformer的注意力层可以形式化为如下公式:
Co-Att l V = softmax ( Q l − 1 V ( K l − 1 T ) T d k ) V l − 1 T , \text{Co-Att}_l^V = \text{softmax}\left(\frac{Q_{l-1}^V (K_{l-1}^T)^T}{\sqrt{d_k}}\right) V_{l-1}^T, Co-AttlV
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1750
1750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









