




文章汉化系列目录
摘要
这篇论文提出了一种面向多模态理解和生成的视觉-音频-语言全感知预训练模型(VALOR)。与广泛研究的视觉-语言预训练模型不同,VALOR在端到端的方式下共同建模视觉、音频和语言之间的关系。它包含三个独立的编码器,用于单一模态表示,并且有一个解码器用于多模态条件文本生成。我们设计了两个预训练任务来预训练VALOR模型,包括多模态分组对齐(MGA)和多模态分组字幕(MGC)。MGA将视觉、语言和音频投影到相同的共同空间,同时构建视觉-语言、音频-语言和视听-语言对齐。MGC学习在视觉、音频或两者条件下生成文本标记。为了推动视觉-音频-语言预训练研究,我们构建了一个名为VALOR-1M的大规模高质量三模态数据集,包含100万带有人工标注视听字幕的可听视频。大量实验表明,VALOR能够学习强大的多模态关联,并能够推广到各种下游任务(例如检索、字幕生成和问答),并能处理不同的输入模态(如视觉-语言、音频-语言和视听-语言)。VALOR在一系列公共跨模态基准上达到了新的最先进性能。代码和数据可在项目页面(https://casia-iva-group.github.io/projects/VALOR)获得。
引言
作为人类,我们通过多种媒介(例如视觉、阅读、听觉、触觉或嗅觉)感知来自环境的信息,并在此基础上理解或与世界互动。理想的智能系统也应该模仿这一过程,发展跨模态的理解和生成能力。各种跨模态应用已经得到了广泛研究,其中视觉-语言任务占据了主要部分,包括文本到视觉的检索[1],[2],视觉字幕生成[3],[4],[5]和视觉问答[6],[7]。幸运的是,受到自然语言处理领域自监督预训练方法成功的启发[8],[9],[10],视觉-语言预训练迅速发展,并在各种视觉-语言基准测试中相对于传统方法取得了主导性能。
然而,我们认为,单纯建模视觉和语言之间的关系远不足以构建一个强大的多模态系统,额外引入音频模态以建立三模态的交互关系是必要的。一方面,音频信号通常包含与视觉互补的语义信息,因此利用三种模态可以帮助机器更全面和准确地理解周围环境。如图1所示,我们可以仅通过观察视频帧来了解房间内发生的事情,但如果没有听到警车的警笛声,我们则无法感知到外面发生的事情。另一方面,在统一的端到端框架中建模三种模态,可以增强模型的泛化能力,且有助于多种视觉-语言、音频-语言、视听-语言以及视觉-音频下游任务。
因此,如图1所示,我们提出了一种视觉-音频-语言全感知预训练模型(VALOR),旨在建立三种模态之间的普适联系,并实现三模态的理解和生成。如图5所示,VALOR使用三个单模态编码器分别对视觉、音频和语言进行编码,并使用一个多模态解码器进行条件文本生成。设计了两个预训练任务,即多模态分组对齐(MGA)和多模态分组字幕生成(MGC),使VALOR能够同时处理判别性和生成性任务。具体来说,MGA将三种模态投影到相同的共同空间,并通过对比学习在视觉-语言、音频-语言和视听-语言三种模态组之间建立细粒度的对齐。MGC要求模型根据视觉、音频或两者条件,通过跨注意力层重建随机遮蔽的文本标记。得益于模态分组策略,VALOR可以学习如何根据不同的模态组合对齐或生成文本,这些能力可以转移到各种跨模态下游任务,包括视频/音频/视听检索、字幕生成或问答。

图1:VALOR采用相关的视觉-音频-语言数据进行预训练,并能够推广到多个任务。AVR/VR/AR代表文本到视听/视觉/音频的检索,AVC/VC/AC代表视听/视觉/音频的字幕生成,AVQA/VQA/AQA代表视听/视觉/音频的问答,分别如此。点击按钮播放音频。
此外,我们认为,强相关的视觉-音频-语言三元组对于训练强大的三模态模型是必不可少的。目前的公共视觉-语言数据集无法进行三模态预训练,因为:i) 所有图像-语言数据集以及一些视频-语言数据集(如WebVid-2.5M [13])都不包含音频信号;ii) 即使一些视频-语言数据集(如HowTo100M [11] 和 HD VILA 100M [12])包含音频模态,它们的音频仅限于人类语音且缺乏多样性,且其文本为自动语音识别(ASR)转录内容,而非客观描述,这些文本与语音内容重复。为了解决上述限制,我们构建了一个大规模高质量的视觉-音频-语言数据集(VALOR-1M),以促进三模态预训练研究。该数据集包含一百万个开放域可听视频,每个视频都被人工标注了一个视听字幕,同时描述了音频和视觉内容。VALOR-1M的强视觉-语言和音频-语言关联性,以及其大规模特点,使其成为三模态预训练的最佳选择。除了VALOR-1M,我们还建立了一个新的基准数据集VALOR-32K,用于评估视听-语言能力。它包含两个新任务,包括视听检索(AVR)和视听字幕生成(AVC)。
我们进行了广泛的消融研究,以证明所提VALOR模型和模态分组策略的有效性。定量和定性结果都证明VALOR能够有效地利用视听线索进行AVR和AVC任务。我们在一系列公共的视频-语言、图像-语言和音频-语言基准测试中对VALOR进行了广泛验证,并在多个测试中取得了新的最先进结果。具体而言,如图2所示,VALOR在文本到视频检索基准(包括MSRVTT、DiDeMo、ActivityNet、LSMDC和VATEX)上,超越了之前的最先进方法,分别提高了3.8%、6.2%、12.7%、0.6%、10.4%(R@1);在开放式视频问答基准(包括MSRVTT-QA、MSVD-QA、TGIF-FrameQA和ActivityNet-QA)上,分别提高了3.8%、3.4%、5.1%、12.5%(Acc);在文本到音频检索基准(包括ClothoV1和AudioCaps)上,分别提高了38.9%、13.0%(R@1)。此外,VALOR在VATEX字幕生成基准上超越了GIT2大模型[14],仅使用了0.26%的训练数据和11.6%的参数。
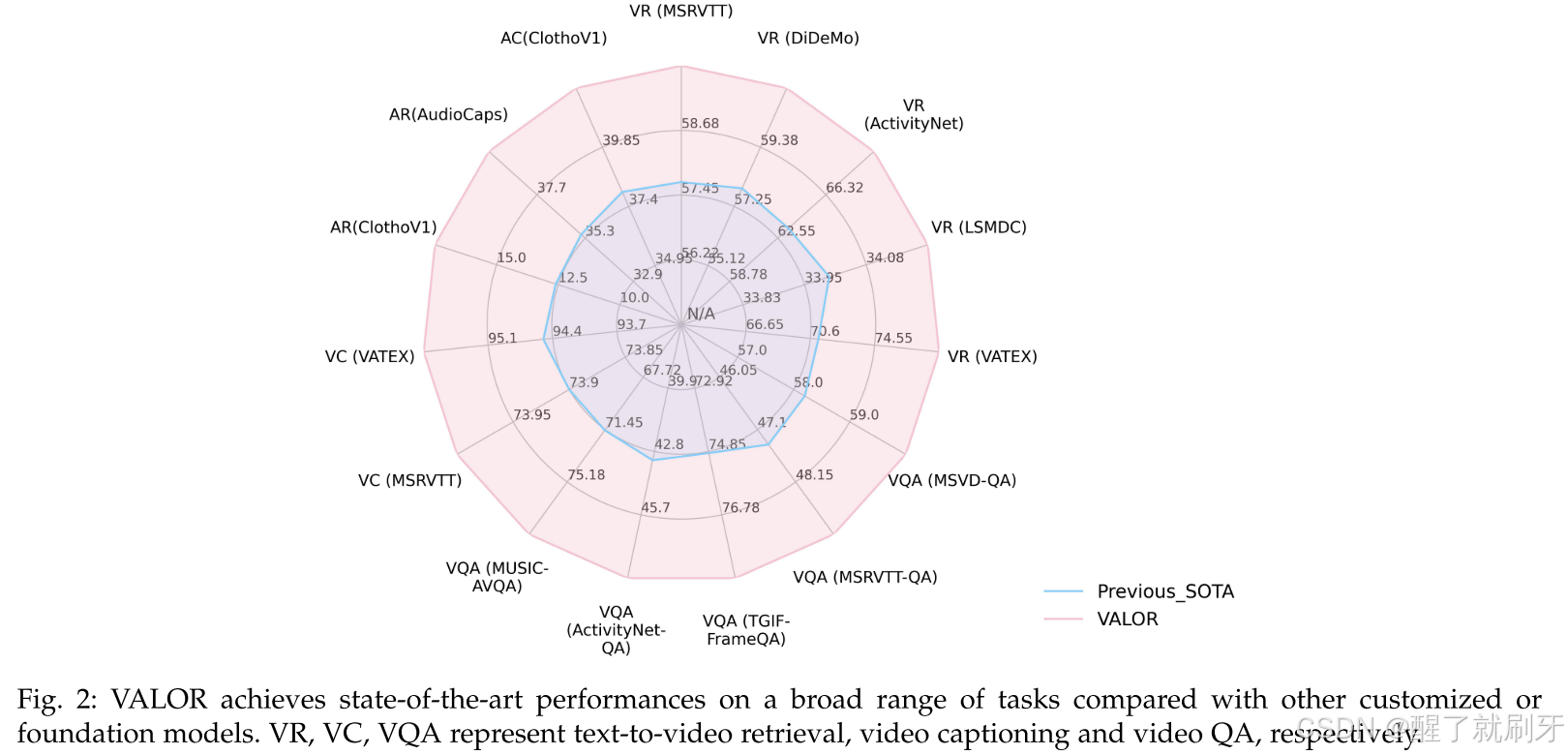
图2:与其他定制或基础模型相比,VALOR在广泛的任务上取得了最先进的性能。VR、VC、VQA分别代表文本到视频检索、视频字幕生成和视频问答。
总体而言,本工作的贡献可以总结如下:I) 我们提出了一种全感知预训练模型(VALOR),它建立了视觉、音频和语言之间的关联,实现了三模态的理解和生成。II) 我们引入了MGA和MGC预训练任务,并采用模态分组策略,以增强模型在不同模态输入下的泛化能力。III) 我们提出了VALOR-1M数据集,这是第一个大规模人工标注的三模态数据集,旨在推动视觉-音频-语言研究,并建立了VALOR-32K基准,用于评估视听-语言能力。IV) 在VALOR-1M和当前公共视觉-语言数据集上预训练后,VALOR在一系列跨模态基准测试中取得了新的最先进性能,并显著提高了各项指标。
2 相关工作
在本节中,我们首先介绍用于多模态预训练的常见跨模态数据集。随后,我们回顾视觉-语言预训练方法。最后,我们介绍了一些典型的方法,它们利用视觉和文本之外的更多模态进行视频-语言学习。
2.1 多模态预训练的跨模态数据集
通常,一个理想的视觉-语言预训练数据集应该满足两个基本需求:足够大的规模和强的视觉-文本关联性。考虑到句子级的字幕注释比单词级的标签标注更为资源消耗,一些方法尝试收集包含人类语音的视频,并提取自动语音识别(ASR)转录文本作为字幕。例如,Miech等人收集了HowTo100M [11],该数据集包含来自122万个讲解型YouTube视频的1.36亿个视频片段,已成为早期视频-语言预训练方法使用的主流数据集。Zellers等人遵循了这一方法,提出了YT-Temporal180M [15],该数据集包含来自600万个YouTube视频的1.8亿个片段。Xue等人收集了HD VILA 100M [12],该数据集包含来自330万个YouTube视频的1亿个片段,具有更多的多样性和更大的图像分辨率。然而,尽管这种方法可以友好地扩展以获得大量的视频-文本对,但字幕的质量并不理想。除了可能的语音识别错误,ASR转录通常传达的是说话者的主观看法和意见,而非静态物体和发生事件的客观描述。即便一些转录文本确实反映了视觉内容,它们也可能存在时间上的错位问题,即它们可能对应于视频片段的前后部分[16]。
为了克服这个问题并兼顾数量和质量,Bain等人遵循了图像-语言Conceptual Captions数据集(CC3M [17],CC12M [18])的收集程序,收集了WebVid [13],该数据集包含250万个视频,并配有alt-texts(替代文本)。尽管有时这些alt-texts不流畅且不完整,但总体来说,它们与视频内容的关联性比ASR转录更强,并且已被最新的视频-语言预训练方法广泛使用。然而,以上提到的任何数据集都不支持视觉-音频-语言预训练,因为缺少音频-语言的关联性,这也促使我们收集了VALOR-1M数据集,以推动三模态预训练的发展。
2.2 视觉-语言预训练
受到BERT [8] 成功的启发,视觉-语言预训练得到了快速发展,我们总结了几个主要的研究方向如下:
I) 跨模态预训练框架设计。根据不同的网络架构,视觉-语言模型主要可以分为双编码器范式 [19]、[20] 和融合编码器范式 [21]、[22]。前者通过简单的点积在编码器的输出处轻度融合视觉和语言,能够高效用于跨模态检索和零-shot分类。后者使用共同注意力 [22] 或合并注意力 [21] 深度融合两种模态,适合更细粒度的任务,如图像描述或视觉问答(VQA)。此外,已经提出了各种自监督预训练任务,以更好地进行跨模态特征表示学习,包括掩码语言建模(MLM) [21],掩码视觉建模(MVM) [21]、[23],视觉-文本匹配(VTM) [21]、[24],视觉-文本对比学习(VTC) [13]、[25] 等。关于视觉表示,早期的方法分别使用离线物体检测器(例如 Faster-RCNN [26])提取物体级图像特征,或者使用3D卷积神经网络(例如 S3D [19])提取片段级视频特征。随着视觉转换器 [27]、[28] 的出现,图像-语言和视频-语言可以通过给模型输入图像或稀疏采样的帧来统一。
II) 统一多任务建模。这一系列工作尝试通过一个统一框架通用建模不同任务,去除任务特定的微调头,从而更高效地利用预训练数据。VL-T5 [29] 首次使用序列到序列框架来建模视觉-语言任务,如视觉问答(VQA)和视觉定位。随后,更细粒度的定位任务,如物体检测和文本到图像生成,也通过框坐标标记 [33] 或图像标记 [34] 被集成进来 [30]、[31]、[32]。除了序列到序列框架,一些工作还通过对比学习 [35] 或掩码语言建模 [36] 来统一多个视觉-语言任务。然而,尽管上述方法统一了多个任务,但它们仅限于视觉-语言领域。相比之下,VALOR可以扩展到视觉-音频-语言领域,并适用于部分感知和全感知任务。
III) 视觉-语言基础模型。用极大量数据和参数训练的视觉-语言模型通常被称为大模型或基础模型,且通常通过对比学习 [37]、[38]、[39]、[40]、语言建模 [14]、[41]、[42]、[43] 或两者结合 [44] 进行监督。基础模型在视觉-语言基准测试上取得了卓越的表现。例如,Flamingo [42] 将模型规模增加到80.2B参数,在VQAv2数据集上得到了84.0的准确率,而GIT2 [14] 将数据规模增大到12.9B的图像-文本对,并在COCO描述基准上取得了149.8的CIDEr得分。然而,由于对计算资源、数据存储和复杂分布式训练的高要求,从参数和数据维度扩展视觉-语言预训练模型的效率有限。相比之下,我们认为VALOR可以看作是从模态维度进行扩展,通过引入音频并构建三模态连接,这种方法更有效且更高效。
2.3 辅助模态增强的视频-语言理解
考虑到视频本身是多模态的媒介,每种模态都包含丰富的语义信息,一些方法利用更多的模态来增强视频-语言学习。MMT [45] 提出了一个多模态变换器,通过融合七个模态专家来进行文本到视频的检索。SMPFF [46] 进一步引入了目标和音频特征,以改进视频描述。在大规模预训练场景中,音频和字幕是最常用的辅助模态,用于强化视频表示。UniVL [47]、VLM [48] 和 MV-GPT [19] 融合了视频和字幕模态,并在HowTo100M数据集上进行视频描述的预训练。VALUE [49] 进一步在更多任务上利用字幕增强,包括视频检索和问答(QA)。关于音频增强,AVLNet [50] 和 MCN [51] 使用音频来增强文本到视频的检索。VATT [52] 提出了一个层次化的对比损失,用于文本-视频和视频-音频的对齐,但其目标是学习单一模态的表示,而不是提高跨模态能力。MERLOT Reserve [15] 和 i-Code [53] 也将视觉、音频和语言作为输入进行预训练,但与VALOR有本质区别:i) 这些方法在预训练和微调过程中存在严重的不一致性。具体来说,在预训练阶段,音频-语言关系是人类语音和ASR转录,而在微调阶段则是普通音频和客观描述。相比之下,VALOR在强相关的三模态数据集上进行训练,并保持预训练-微调一致性,这使得它能够推广到视频-语言、音频-语言和视听-语言任务。ii) 这些方法仅针对判别任务,如视频问答(QA),而VALOR则更为通用。
3. VALOR 数据集用于视听语言预训练
正如第2.1节所解释的那样,视频-语言数据集的字幕是ASR转录或alt-text时,并不是进行视听语言预训练的最佳选择,因为缺乏文本句子和音频概念之间的明确对应关系。为了解决这个问题,我们提出了一个视听语言相关数据集VALOR,用于三模态模型的预训练和基准测试,通过注释公共视听数据来实现。在以下小节中,我们将详细阐述数据收集、注释和基准测试过程,并分析VALOR数据集的特点。
3.1 视听数据收集
理想情况下,视听语言数据集中的视频应包含视觉和音频轨道,并且具有高质量和多样性。为此,我们选择了来自 AudioSet [66] 的视频,这是一种为音频事件识别收集的大规模数据集。具体来说,AudioSet 包含超过 200 万个 10 秒的视频片段,这些片段来自 YouTube 视频,每个视频都根据层次本体标注了 527 个音频类别。它被分为 200 万不平衡训练集、2.2 万平衡训练集和 2 万评估集。在平衡的训练和评估集中的每个音频类别有相似数量的视频,而不平衡训练集中的类别分布没有限制。我们下载了仍然可以访问的 AudioSet 视频,过滤掉低质量或损坏的视频,最终获得了约 100 万个视频。根据音频类别分布,我们将数据集分为 VALOR-1M 作为三模态预训练数据集,和 VALOR-32K 作为视听语言下游基准数据集。具体而言,VALOR-1M 中的视频来源于 AudioSet 的不平衡训练集,而 VALOR-32K 中的视频来源于 AudioSet 的平衡训练集和评估集。如图 4 所示,与 VALOR-1M 相比,VALOR-32K 具有更平衡的音频类别分布。

3.2 视听字幕标注
我们采用付费标注方式为 VALOR 数据集获取视听描述。考虑到这一标注任务相较于传统的视频描述标注更加新颖和复杂,我们设计了一个三步互动标注流程。第一步,标注员培训。我们为 500 名标注员进行在线培训,强调描述中应全面反映重要成分,如主要对象、活动、场景、物体和声音。我们提供了一些视频-视听字幕对,帮助标注员提前熟悉标注格式。我们还提供了一个字典,将视频ID与其对应的 AudioSet 标签进行映射,并鼓励标注员在进行视听描述标注前,首先查询这些标签作为参考。第二步,第一阶段标注。在此阶段,我们提供 VALOR-32K 中的视频给标注员。我们手动检查标注的描述,并反馈常见问题和对应的视频ID。然后,要求标注员重新标注这些不满意的示例,以加深对标注要求的理解。第三步,第二阶段标注。在此阶段,标注员为 VALOR-1M 中的视频撰写视听描述。每个描述需要经过三名标注员的进一步检查,以确保标注质量。如果有超过一名标注员认为标注不满意,则需要重新标注。整个标注和检查过程大约花费了 2 个月的时间。
3.3 VALOR-32K 基准
考虑到目前已建立的视听语言基准仅针对问答任务 (AVQA) [63],[64],[65],我们建立了 VALOR-32K 基准,以扩展评估任务领域,该基准包括视听检索 (AVR) 和视听字幕生成 (AVC) 两个任务。如图 8 所示,AVC 任务要求模型为可听的视频生成视听字幕,而在 AVR 任务中,模型需要根据给定的视听字幕查询检索出最匹配的视频候选项。由于引入了音频模态,AVR 和 AVC 任务比现有的文本到视频检索和视频字幕生成任务更具挑战性。VALOR-32K 数据集被划分为 25K、3.5K 和 3.5K 个视频用于训练、验证和测试。AVR 和 AVC 任务评估均使用视频检索和视频字幕生成的相同评估指标。
3.4 VALOR 数据集的特点
VALOR 数据集是首个大规模视听语言强相关数据集,其最大的亮点在于丰富的音频概念和视听字幕。在本小节中,我们将对 VALOR 数据集与公共视频语言数据集进行定量和定性比较。
定量比较。 为了评估不同数据集中音频概念在字幕中的丰富度,我们定义了一个名为音频概念密度(ACD)的度量标准。我们根据 [66] 提出的 632 个音频类别本体建立了音频概念集。具体来说,如果一个类别包含多个相似的概念并且用逗号分隔,我们将其拆分,并将所有词转换为小写,去除标点符号。最终,我们得到了 759 个音频概念。对于每个字幕,我们通过去除标点符号并转换为小写来预处理,然后检测每个音频概念的存在。遍历整个数据集后,可以计算出 ACD 度量公式如下:
A C D = N A C N W ACD = \frac{N_{AC}}{N_W} ACD=NWNAC
其中, N A C N_{AC} NAC 是检测到的音频概念总数, N W N_{W} NW 是总词数。如表 1 所示,VALOR 数据集的 ACD 度量值远大于其他视频语言数据集。此外,VALOR-1M 和 VALOR-32K 的平均字幕长度分别为 16.4 和 19.8,远长于其他数据集(如 WebVid-2.5M 为 14.2,CC3M 为 10.3),这得益于额外的与音频相关的描述和高质量的标注。
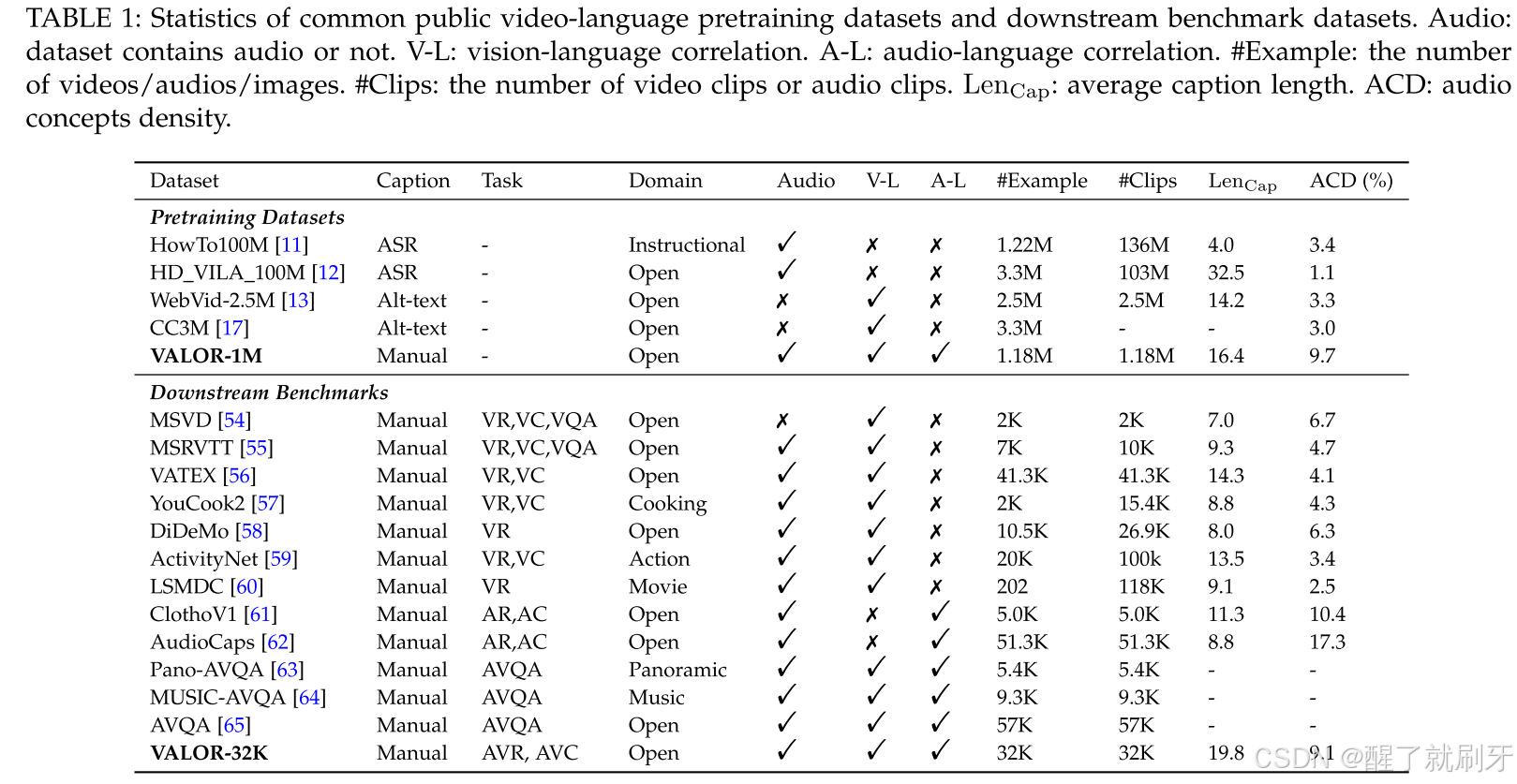
表1:常见公共视频-语言预训练数据集和下游基准数据集的统计信息
- Audio:数据集中是否包含音频。
- V-L:视觉-语言相关性。
- A-L:音频-语言相关性。
- #Example:视频/音频/图像的数量。
- #Clips:视频片段或音频片段的数量。
- LenCap:平均字幕长度。
- ACD:音频概念密度。
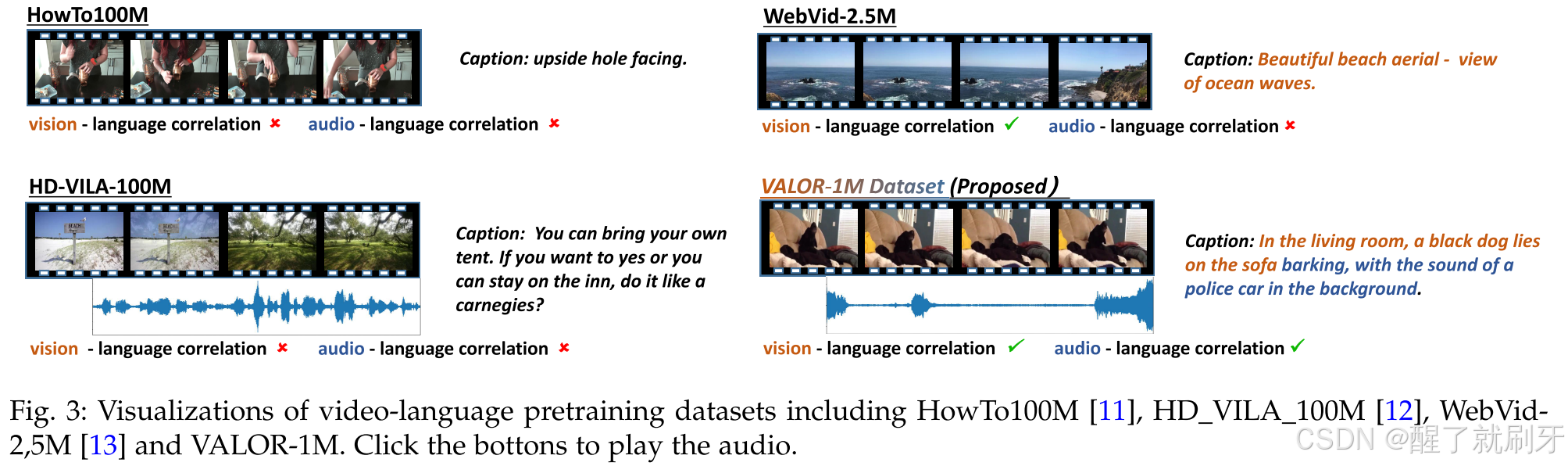
定性比较。 我们将 VALOR-1M 与基于 ASR 转录字幕的数据集(如 HowTo100M 和 HD VILA 100M)以及基于 alt-text 字幕的数据集(如 WebVid-2.5M)进行比较。如图 3 所示,HowTo100M 数据集的字幕是不完整的句子,甚至人类也无法理解,更不用说进行视听语言关联了。HD VILA 100M 中的字幕更加完整,但视听语言的关联仍然较弱。具体来说,字幕是从两个人讨论度假推荐的对话中转录出来的,但重要的视觉概念,如蓝天、木牌和树木,完全没有在字幕中体现。WebVid-2.5M 中的字幕与视觉的关联较强,涵盖了更多的视觉概念,但它们包含的音频概念较少,或者缺乏对音频信号的直接描述。相比之下,VALOR 的注释同时关注视觉和音频线索,正如在示例中提到的视觉概念(如黑狗和沙发)以及音频概念(如警车警报)所体现的那样。
4 VALOR 模型
我们期望 VALOR 模型能够满足以下需求:
-
端到端训练:它可以进行完全的端到端训练,避免预先提取视觉或音频特征,使得单一模态编码器能够一起调整,学习适应于视觉-音频-语言交互的表示。
-
跨模态对齐、判别性和生成能力:应当学习跨模态对齐、判别性和生成能力,以提高 VALOR 在更广泛的跨模态任务中的适应能力。
-
通用化的跨模态能力:考虑到不同模态在不同下游领域的使用,VALOR 应该学习更为通用的跨模态能力,而不是局限于特定的模态组。
为此,我们在模型架构和预训练任务方面做出了专门的设计,这些内容将在以下小节中详细阐述。
4.1 模型架构
如图 5 所示,VALOR 由文本编码器、视觉编码器、音频编码器和多模态解码器组成。该架构将单模态表示学习分配给单独的编码器,这些编码器的参数可以继承自预训练模型,从而加速收敛并提高性能。
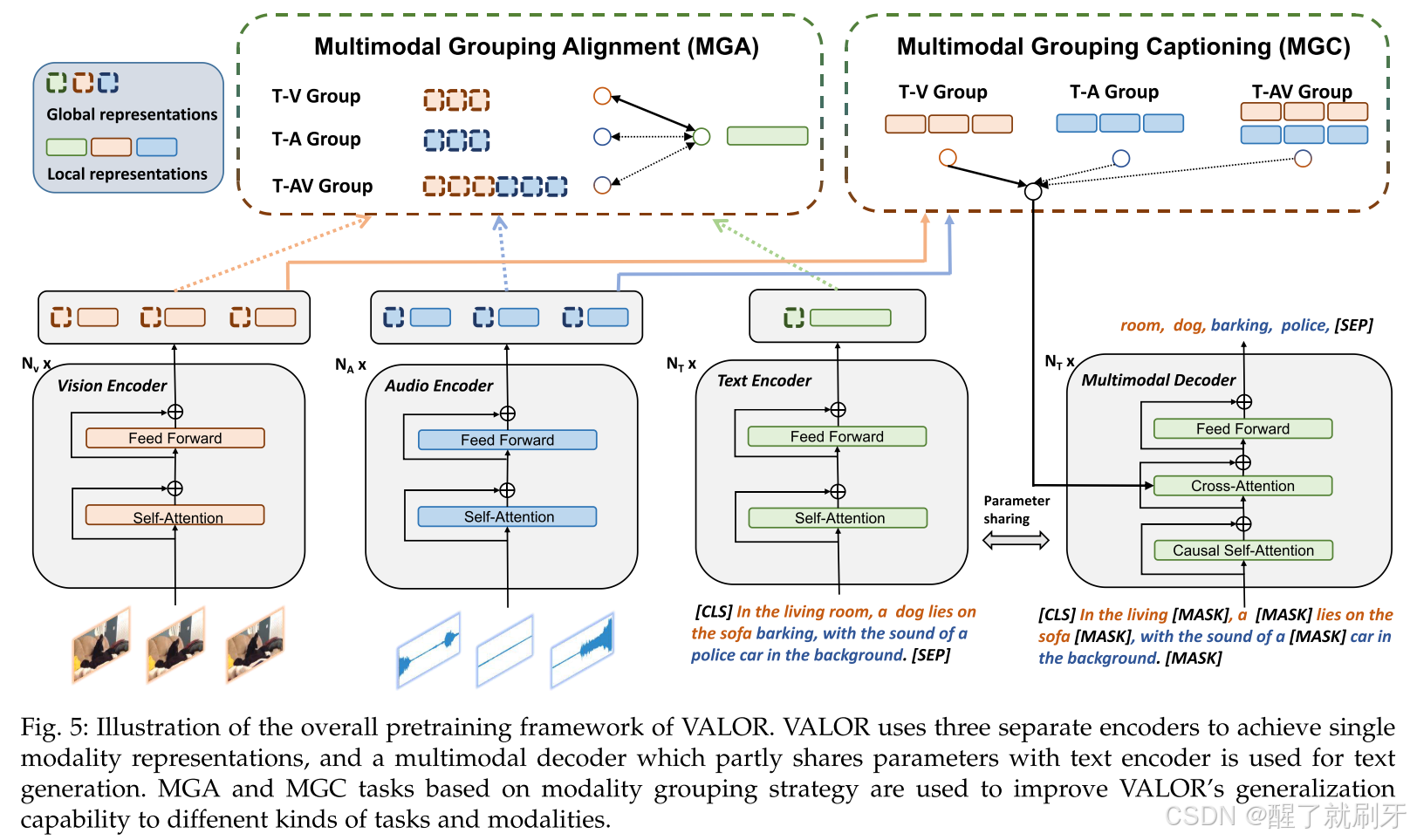
图 5:VALOR整体预训练框架的示意图。VALOR使用三个独立的编码器来实现单模态表示,并使用一个与文本编码器部分共享参数的多模态解码器进行文本生成。基于模态分组策略的MGA和MGC任务用于提高VALOR对不同任务和模态的泛化能力。
文本编码器。使用 BERT [8] 模型作为文本编码器。原始句子首先通过 BERT 的分词器进行分词,词汇表大小为 30522。输入是词嵌入和位置嵌入的和。输出的文本特征为 F t ∈ R N t × C t F_t \in \mathbb{R}^{N_t \times C_t} Ft∈RNt×Ct,其中 N t N_t Nt 和 C t C_t Ct 分别是预定义的最大标记长度和隐藏层大小。
视觉编码器。我们尝试了两种视觉编码器,包括 CLIP [37] 和 VideoSwin Transformer [67]。这两种模型都可以将图像或视频信号作为输入。对于视频输入,我们从视频剪辑中稀疏地采样 N v N_v Nv 帧,并使用补丁嵌入层对补丁进行编码。输出特征为 F v ∈ R N v × S v × C v F_v \in \mathbb{R}^{N_v \times S_v \times C_v} Fv∈RNv×Sv×Cv,其中 S v S_v Sv 是序列长度, C v C_v Cv 是隐藏层大小。帧独立地通过 CLIP 编码器传递,而在 VideoSwin Transformer 中,通过时间窗口注意力机制进行交互。对于图像输入, N v N_v Nv 等于 1。
音频编码器。使用在 AudioSet 上预训练的音频频谱变换器(AST)[68][69] 作为音频编码器。给定一个音频波形,我们将其分割成多个 5 秒长的音频片段,并随机选择 N a N_a Na 个片段作为输入。音频片段被转换为 64 维的对数 Mel 滤波器组特征,这些特征通过 25 毫秒的 Hamming 窗口每 10 毫秒计算一次。这样每个片段会得到一个 64 × 512 的频谱图。之后,频谱图被分割成补丁,经过补丁嵌入层并输入到音频编码器中。输出特征为 F a ∈ R N a × S a × C a F_a \in \mathbb{R}^{N_a \times S_a \times C_a} Fa∈RNa×
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









