




文章汉化系列目录
摘要
图像-文本检索旨在根据文本(图像)查询检索语义相关的图像(文本),这是搜索系统、在线购物和社交网络中的基本且关键任务。现有的工作已经展示了视觉-语义嵌入和单模态知识(如文本知识)的有效性,在连接图像和文本方面起到了作用。然而,当图像包含未在文本中直接描述的信息时,这些工作忽视了两种模态之间隐含的多模态知识关系,阻碍了通过隐含语义关系连接图像和文本的能力。例如,一张图像显示了一个人在“水龙头”旁边,但配对的文本描述可能只包含“洗”这个词,忽略了洗涤工具“水龙头”。图像对象“水龙头”和文本单词“洗”之间的隐含语义关系可以帮助连接上述图像和文本。
为了充分利用隐含的多模态知识关系,我们提出了一种多模态知识增强视觉-语义嵌入(MKVSE) 的方法,构建了一个多模态知识图来显式表示隐含的多模态知识关系,并将其注入视觉-语义嵌入中,用于图像-文本检索任务。
本文的贡献可以总结如下:
- 多模态知识图(MKG) 被提出用于显式表示图像和文本之间的隐含多模态知识关系,这些关系表现为模态内语义关系和跨模态共现关系。模态内语义关系提供了在单模态数据(如文本语料库)中隐含的同义信息。跨模态共现关系则表征了在图像-文本对中隐含的共现关联(如时间、因果和逻辑关联)。这两种关系有助于在更高层次的语义空间中建立可靠的图像-文本连接。
- 多模态图卷积网络(MGCN) 被提出用于对MKG进行两步推理,以充分利用隐含的多模态知识关系。在第一步中,MGCN专注于模态内关系,以区分语义空间中的其他实体。在第二步中,MGCN专注于跨模态关系,以基于共现关联连接多模态实体。这种两步推理方式可以充分利用两种模态实体之间的隐含语义关系,增强图像和文本的嵌入。
我们在两个广泛使用的数据集上进行了大量实验,即Flickr30k和MSCOCO,以证明所提出的MKVSE方法在实现最先进性能方面的优越性。代码可在https://github.com/PKU-ICST-MIPL/MKVSE-TOMM2023获得。
1 引言
图像和文本是理解现实世界的两种最常见的模态。相应地,对于有效和高效的图像-文本检索技术的需求正在显著增加,这在多模态检索中是一个基础且关键的问题,并且近年来吸引了广泛关注【7, 14, 36, 37, 46, 52】。具体而言,图像-文本检索旨在根据给定的图像(文本)查询,检索与之语义最相关的文本(图像)。然而,文本描述是抽象的,而视觉场景是具体的,包含冗余信息。这两者展示了异质特性,具有不一致的分布和表示,使得衡量图像和文本之间的语义相似性极具挑战性。
为了解决这一挑战,提出了视觉-语义嵌入(VSE)【7, 13, 14】,旨在学习一个统一的联合嵌入空间,在该空间中,成对的图像和文本实体的嵌入之间的相似性被优化为最大值。许多方法利用深度神经网络提取图像和文本的全局表示,并通过某种标准来学习相似性度量。Wang等人【47】提出了一个双分支神经网络,分别提取图像和文本的全局嵌入,然后通过逐元素乘法融合这两个分支,以学习这两种数据模态之间的相似性。Faghri等人【14】提出了一种使用困难负样本挖掘的损失函数,通过学习最大化基于铰链的三元组排名损失来提高VSE模型的质量。Wang等人【48】提出使用场景图来表示图像和文本:视觉场景图和文本场景图,每个图都用于共同表征对应模态中的对象及其关系。然后,图像-文本检索任务自然被定义为跨模态场景图匹配。然而,这种范式忽视了任何先验的单模态知识,这可能会限制其推理图像和文本之间知识关系的能力。为了解决这个问题,一些工作通过利用单词共现关系来推理图像和文本之间的高级关系,从而引入了常识知识。Wang等人【46】提出了一种共识感知的视觉-语义嵌入方法,利用图像描述语料库中的共识信息。它通过计算词概念之间的共现关系,并学习共识感知概念表示用于图像-文本检索。Shi等人【41】提出了场景概念图,通过利用同一场景中经常出现的对象来引入场景知识。从图像中检测到语义概念,然后通过场景概念图扩展以选择相关的上下文概念,并将其表示与图像嵌入特征融合。然而,这些方法仅利用了单模态知识(例如,文本知识),忽视了图像和文本之间隐含的多模态知识关系。当图像包含未在文本中直接描述的信息时,隐含的多模态知识关系可以帮助在更高层次的语义空间中连接图像和文本。
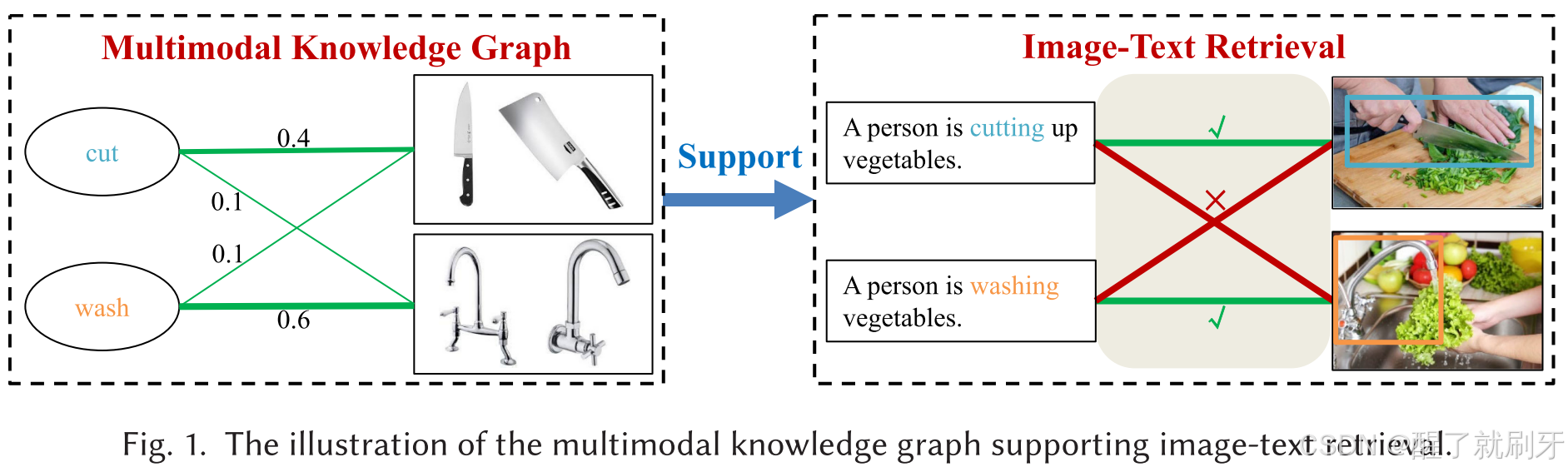
图 1. 支持图文检索的多模态知识图示意图。
为了解决上述问题,我们提出了多模态知识增强视觉-语义嵌入(MKVSE) 方法。如图1所示,构建了多模态知识图,以显式表示隐含的多模态关系。然后,它可以用于支持下游的图像-文本检索,连接图像和文本。例如,当我们看到“洗菜”这个词时,会联想到水、水龙头等图像;当我们看到“切菜”时,会在脑海中浮现刀具和蔬菜的画面。本文的主要贡献可以总结如下:
-
多模态知识图(MKG) 被提出以显式表示图像和文本之间的隐含多模态知识关系,包括通过模态内语义关系和跨模态共现关系连接的图像和文本实体。模态内语义关系提供单模态数据(如文本语料库)中隐含的同义信息,而跨模态共现关系则描述了图像-文本对中隐含的共现关联。这两种关系有助于在更高层次的语义空间中连接图像和文本。
-
多模态图卷积网络(MGCN) 被提出用于通过在MKG上进行两步推理,充分利用隐含的多模态知识。MGCN在每一步中可以专注于不同的方面。具体来说,在第一步中,MGCN分别对图像实体和文本实体进行推理,关注模态内的语义关系,旨在区分语义空间中的其他实体。在第二步中,MGCN对整个多模态图进行推理,关注跨模态的共现关系,旨在基于统计关联连接多模态实体。最终,能够挖掘出两种模态实体之间的隐含语义关系,以增强图像和文本的嵌入,提升检索性能。
我们在两个广泛使用的数据集,即Flickr30k【56】和MSCOCO【28】上进行了大量实验。实验结果证明了我们提出的MKVSE方法的有效性和优越性。
本文的其余部分组织如下:第2节简要回顾了相关工作的综述。第3节介绍了提出的MKVSE方法,并详细解释其架构。第4节展示了实验和分析,包括与最先进的图像-文本检索方法的比较、消融研究和可视化结果。第5节总结了本文并展望了未来的工作。
2 相关工作
2.1 图像-文本检索
衡量图像-文本语义相似性是图像-文本检索的关键。根据相似性度量方法的不同,现有的图像-文本检索方法大致可以分为两类:跨交互匹配方法【8, 20, 23, 27, 33, 50】和独立表示匹配方法【7, 14, 15, 24, 43, 46】。
对于跨交互匹配方法,Karpathy等人【20】首次采用R-CNN【17】检测显著对象,并推断句子中的词级文本特征与图像中的区域级视觉特征之间的潜在对齐关系。此外,跨注意力机制【8, 23, 27, 33, 50】被应用于捕捉图像和文本之间的细粒度交互,以进行图像-文本检索。尽管该方法性能较高,但跨注意力机制在推理过程中存在计算爆炸问题,因为需要对所有的图像和文本对进行计算,这在检索任务中不可忽视【7】。
相比之下,独立表示匹配方法在推理过程中效率更高。Frome等人【15】提出了一个基于嵌入的先驱方法,将图像特征和skip-gram词特征通过线性映射投影,并计算相似性。Faghri等人【14】提出了VSE++,通过使用在线困难负样本挖掘进一步提高了视觉-语义嵌入(VSE)的质量。除此之外,更多的研究专注于改进视觉或文本表示,或设计辅助训练目标【7, 24, 43】。Li等人【24】提出了视觉语义推理网络(VSRN),解决当前图像表示中缺乏全局语义概念的问题,VSRN通过捕捉场景中的关键对象和语义概念生成增强的视觉表示。
为了处理具有多重含义的多义实体,Song等人【43】提出了多义视觉-语义嵌入(PVSE),通过结合全局上下文和局部引导特征来计算实体的多个多样化表示。这两个多义实例嵌入网络在多实例学习框架中绑定并联合优化。Chen等人【7】提出了通用池化算子(GPO),能够自动为不同数据模态和特征提取器寻找最佳池化函数,无需手动调整,同时保持高效性和有效性。
然而,上述所有方法都仅依赖图像-文本对,忽略了图像和文本之间的先验知识。Shi等人【41】通过考虑图像场景图中的语义概念共现对,构建了场景概念图(SCG)。在同一场景中共现的概念可以提供常识知识,用于发现其他语义相关概念。然后,SCG可以用于扩展更多的语义概念,从语义上增强图像表示。Wang等人【46】提出了共识感知的视觉-语义嵌入(CVSE) 模型,将共识信息纳入图像-文本匹配。通过计算来自图像描述语料库中的语义概念的统计共现关系,利用共识信息进行图像-文本匹配。
然而,这些方法仅利用了单模态知识(例如来自图像场景图和文本语料库的知识),忽略了当图像包含未在文本中直接描述的信息时图像和文本之间隐含的多模态知识关系,这限制了图像和文本之间的连接能力。因此,探索隐含多模态知识关系在图像-文本检索中的有效性是必要的。我们提出的方法引入了多模态知识图,以显式表示图像和文本之间隐含的多模态知识关系,从而帮助在更高层次的语义空间中连接这两种模态。
2.2 基于多模态图的深度学习
基于多模态图的深度学习可以利用多模态内容,应用于各种多模态理解任务,例如假新闻检测【42】、视频情感识别【12】、多模态神经机器翻译【19】、推荐系统【59】和图像-文本检索【16】。Wang等人【49】提出了一个端到端的知识驱动多模态图卷积网络,通过将文本信息、知识概念和视觉信息整合到统一的深度模型中,以对假新闻检测进行语义层次的表示建模。Mai等人【31】提出了一种分层图融合网络,能够显式建模单模态、双模态和三模态动态,用于视频情感识别。Yin等人【55】提出了一种基于图的多模态融合编码器,利用不同模态语义单元之间的细粒度语义对应关系来实现多模态神经机器翻译。Sun等人【44】将多模态知识图结合起来,并在其上进行信息传播,以获得更优的实体嵌入,用于推荐系统。
此外,一些工作【9, 16, 48】也将多模态图引入到图像-文本检索中。Garcia等人【16】提出通过艺术上下文信息增强神经网络的视觉表示。为此,构建了一个特定于艺术的知识图,以捕捉艺术属性之间的上下文关系,从而为视觉模型提供信息。然而,检索前需要为所有候选图像构建多模态知识图,这在候选图像缺乏上下文关系(如作者和日期)时可能会限制其应用。Wang等人【48】提出使用两种场景图表示图像和文本:视觉场景图和文本场景图,每个场景图用于共同表征两种模态中的对象和关系。图像-文本检索任务随后自然地被定义为跨模态场景图匹配。Cheng等人【9】提出了基于图的跨模态图匹配网络(CGMN),能够在不引入网络交互的情况下探索模态内关系和模态间关系。CGMN可以在跨模态关系推理中发挥作用,同时保持与独立方法同等的效率。
然而,上述方法中的多模态图都是在图像-文本对的训练时构建的,隐含的多模态知识关系未被显式表示。因此,这些方法无法充分利用多模态知识图中的隐含多模态关系,而这种关系对图像-文本检索至关重要。我们提出的方法引入了多模态知识图,以显式表示图像和文本之间隐含的多模态知识关系,然后提出的多模态图卷积网络可以通过两步方法充分利用隐含的多模态知识关系。在每一步中,它可以聚焦于不同方面,以进一步提升视觉-语义嵌入的质量。
2.3 多模态知识增强深度学习
尽管深度学习在许多领域取得了巨大成功,但它通常对数据需求量大,缺乏可解释性,并且在未见情境下表现不佳。目标领域中通常存在各种先验知识,可以缓解深度学习的这些不足。现有的多模态知识增强深度学习方法【11, 53, 58】旨在将多模态知识融入网络,已被应用于各种多模态理解任务,例如假新闻检测【42】、视频情感识别【12】、多模态神经机器翻译【19】、推荐系统【59】和图像-文本检索【16】。
Ding等人【11】提出用三元组形式表示多模态知识以关联视觉对象和事实答案,从而为VQA情境构建与视觉相关的多模态知识。Zhang等人【58】提出了一种基于产品导向的时空图的知识增强时空推理,以捕获细粒度产品部件特征的动态变化。Chen等人【5】提出引入外部多模态知识以帮助改进命名实体提取,将匹配的实体信息整合到模型中进行特征融合。Yang等人【54】提出将外部多模态知识库推理与任务导向对话系统中的预训练语言模型结合,通过多粒度融合机制增强模型,以捕获对话历史中的多粒度语义。Yang等人【53】提出在预训练中执行三重对比学习,利用图像和文本输入中的局部化和结构化信息来促进表示学习。Nian等人【34】提出了一个多模态知识表示学习框架,尝试处理来自文本和视觉模态的网络数据中的知识。
然而,这些方法在图像包含未直接描述在文本中的对象时忽视了多模态隐含关系,这限制了图像和文本的连接能力。我们提出的方法能够显式表示图像和文本之间隐含的多模态知识关系,然后可以将其整合到网络中以实现更稳健的图像-文本连接。
3 多模态知识增强视觉-语义嵌入
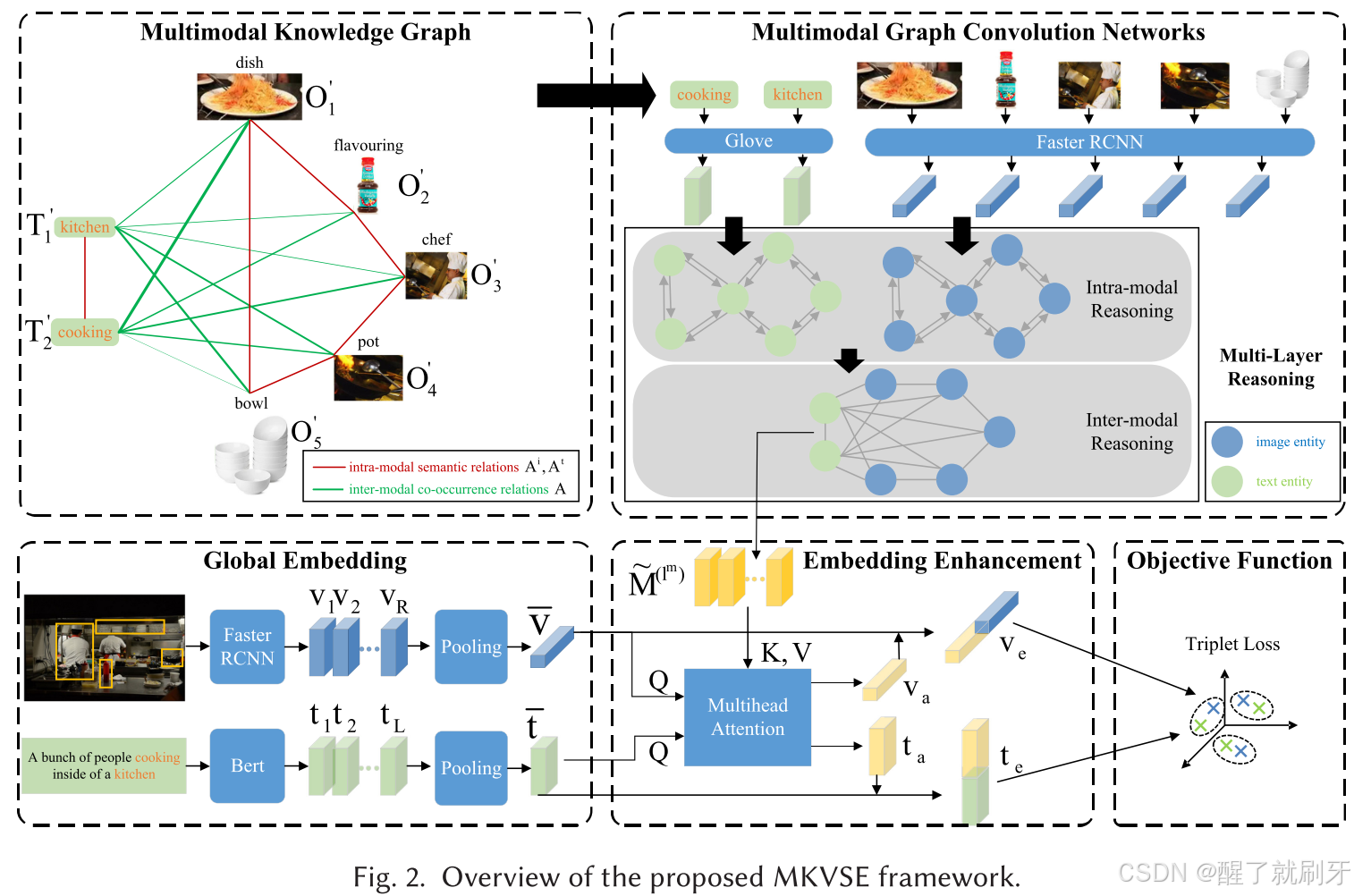
图 2. 所提出的 MKVSE 框架概览。
如图2所示,我们提出的多模态知识增强视觉-语义嵌入方法(MKVSE)包括五个组件:全局嵌入(第3.1节)、多模态知识图(第3.2节)、多模态图卷积网络(第3.3节)、嵌入增强(第3.4节)和目标函数(第3.5节)。
在全局嵌入中,每个输入图像表示为区域级特征 V = [ v 1 ; … ; v R ] V = [v_1; \dots; v_R] V=[v1;…;vR],其中 v i v_i vi 是第 i i i 个区域的特征向量【1】。每个输入文本表示为词特征 T = [ t 1 ; … ; t L ] T = [t_1; \dots; t_L] T=[t1;…;tL],其中 t j t_j tj 是第 j j j 个词的特征向量【45】。采用池化函数 GPO【7】从图像特征 V V V 计算图像全局嵌入 v ˉ \bar{v} vˉ,从文本特征 T T T 计算文本全局嵌入 t ˉ \bar{t} tˉ。
在多模态知识图(MKG) 中,MKG的实体集合 { T 1 , T 2 , … , T n t , O 1 , O 2 , … , O n i } \{T_1, T_2, \dots, T_{nt}, O_1, O_2, \dots, O_{ni}\} {
T1,T2,…,Tnt,O1,O2,…,Oni} 选自在 Visual Genome 数据集中出现频率最高的图像对象和文本词【22】。MKG的关系通过两个模态之间的共现关系 A A A 和模态内部的语义关系 A i , A t A_i, A_t Ai,At 计算得出。文本实体用 GloVe 嵌入表示【35】,图像实体用同类特征的均值池化表示【1】。
在多模态图卷积网络(MGCN) 中,MKG通过MGCN以两步推理方式处理,每一步聚焦不同方面,以获取MKG中实体 { T 1 , T 2 , … , T n t , O 1 , O 2 , … , O n i } \{T_1, T_2, \dots, T_{nt}, O_1, O_2, \dots, O_{ni}\} {
T1,T2,…,Tnt,O1,O2,…,Oni} 的嵌入 M ~ ( l m ) \tilde{M}(l_m) M~(lm),其中 l m l_m lm 是MGCN的层数。
在嵌入增强中,实体嵌入 M ~ ( l m ) \tilde{M}(l_m) M~(lm) 用于通过多头注意力机制【45】增强输入图像的全局嵌入 v ˉ \bar{v} vˉ 和输入文本的全局嵌入 t ˉ \bar{t} tˉ,生成增强的嵌入 v e v_e ve 和 t e t_e te。
在目标函数中,通过优化基于铰链的双向三元组损失,使增强的嵌入 v e v_e ve 和 t e t_e te 对齐。最后,与文本(图像)查询相似度最高的候选图像(文本)被选为最终的检索结果。
3.1 全局嵌入
3.1.1 图像的全局嵌入
对于输入图像 I I I,我们遵循参考文献【7, 36, 37】,使用自下而上和自上而下注意力模型(BUTD)【1】来检测显著区域,选择具有最高类别置信度分数的前 R R R 个感兴趣区域(ROIs),其中 R = 36 R = 36 R=36。然后,获得的 R R R 个区域级图像特征 V = [ v 1 ; … ; v R ] ∈ R R × D i V = [v_1; \dots; v_R] \in \mathbb{R}^{R \times D_i} V=[v1;…;vR]∈RR×Di,其中 D i = 2 , 048 D_i = 2,048 Di=2,048 是提取的区域特征的维度。之后,通过全连接(FC)线性投影将 V V V 投射到 D D D 维空间。得到的视觉区域表示记为 V ~ = [ v ~ 1 ; … ; v ~ R ] ∈ R R × D \tilde{V} = [\tilde{v}_1; \dots; \tilde{v}_R] \in \mathbb{R}^{R \times D} V~=[v~1;…;v~R]∈RR×D。此外,通过对 V ~ \tilde{V} V~ 采用池化函数获得输入图像 I I I 的全局嵌入 v ˉ ∈ R D \bar{v} \in \mathbb{R}^D vˉ∈RD。广义池化算子(GPO)【7】在图像-文本检索中相比于传统池化策略(如均值池化和最大池化)表现出显著提升,因此被作为我们的池化策略。
3.1.2 文本的全局嵌入
对于每个输入文本 T T T,我们遵循参考文献【7, 36, 37】,使用预训练的 Bert【45】作为文本编码器来提取词表示 T = [ t 1 ; … ; t L ] ∈ R L × D t T = [t_1; \dots; t_L] \in \mathbb{R}^{L \times D_t} T=[t1;…;tL]∈RL×Dt,其中 t j ∈ R D t t_j \in \mathbb{R}^{D_t} tj∈RDt 表示 T T T 的第 j j j 个词的表示, L L L 表示词的数量, D t D_t Dt 表示词嵌入的维度。然后,通过 FC 线性投影将 T T T 投射到 D D D 维空间。得到的文本词表示记为 T ~ = [ t ~ 1 ; … ; t ~ L ] ∈ R L × D \tilde{T} = [\tilde{t}_1; \dots; \tilde{t}_L] \in \mathbb{R}^{L \times D} T~=[t~1;…;t~L]∈RL×D。输入文本 T T T 的全局嵌入 t ˉ ∈ R D \bar{t} \in \mathbb{R}^D tˉ∈RD 通过在3.1.1节中采用相同的池化函数 GPO【7】获得。
3.2 多模态知识图
为了显式表示图像和文本之间的隐含关系,我们构建了多模态知识图(MKG)。
3.2.1 实体
选择出现在 Visual Genome【22】和 MSCOCO 或 Flickr 训练数据集中的图像 { I 1 , … , I N } \{I_1, \dots, I_N\} { I1,…,IN},以避免验证集数据泄露。然后,得到 N N N 个三元组 ( I i , O i , T i ) (I_i, O_i, T_i) (Ii,Oi,Ti),其中 I i I_i Ii 是原始图像, O i O_i Oi 是 I i I_i Ii 中出现的图像对象列表, T i T_i Ti 是人工标注的文本描述。我们遵循参考文献【18, 46】,忽略如“is”和“a”等无意义的文本词,从总共 14,777 个文本词中选择出现频率最高的 n t n_t nt 个文本词 { T 1 , T 2 , … , T n t } \{T_1, T_2, \dots, T_{n_t}\} { T1,T
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1221
1221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









