




系列文章目录
文章目录
摘要
文本到图像的检索是跨模态信息检索中的一项重要任务,在给定文本查询的情况下,从大的且未标记的数据集中检索相关图像。在本文中,我们提出了一种新的VisualSparta(Visualtext Sparse Transformer Matching)模型,该模型在准确性和效率方面都有显著的改进。VisualSparta的性能优于MSCOCO和Flickr 30K中以前最先进的可伸缩方法。我们还表明,它获得了实质性的检索速度优势,即,对于100万个图像索引,与CPU矢量搜索相比,使用CPU的VisualSparta获得了约391倍的加速,与使用GPU加速的矢量搜索相比,获得了约5.4倍的加速。实验表明,对于较大的数据集,这种速度优势甚至会变得更大,因为VisualSparta可以高效地实现为倒排索引。据我们所知,VisualSparta是第一个基于转换器的文本到图像检索模型,它可以实现对大规模数据集的实时搜索,与以前的最先进的方法相比,具有显著的准确性提高。
1 引言
文本到图像检索是从给定文本查询的语料库中检索相关图像列表的任务。这项任务具有挑战性,因为为了在给定文本查询的情况下找到最相关的图像,该模型不仅需要对文本和视觉通道都有良好的表示,而且还需要捕捉它们之间的细粒度交互。
现有的文本到图像检索模型大致可以分为两类:查询不可知模型和查询相关模型。双编码器体系结构是一种常见的查询不可知模型,它使用两个编码器分别对查询和图像进行编码,然后通过内积计算相关性(Faghri等人,2017;Lee等人,2018;Wang等人,2019a)。变压器体系结构是众所周知的查询依赖模型(Devlin等人,2018年;Yang等人,2019年)。在这种情况下,每对文本和图像通过连接并传递到单个网络来编码,而不是由两个单独的编码器编码(Lu等人,2020;Li等人,2020b)。这种方法借用了大型预先训练的变压器模型的知识,与双编码器方法相比显示出更好的精度(Li等人,2020b)。

图1:推断时间与模型准确度。每个点表示MSCOCO 1 K分割上不同型号的召回@1。通过将top n-terms设置为500,我们的模型显著优于以前最好的查询不可知检索模型,具有2.8X的加速比。详见第5.1节。
除了提高准确性之外,检索速度也是信息检索(IR)团体中长期存在的研究主题(Manning等人,2008年)的报告。查询相关模型在应用于整个图像语料库时速度非常慢,因为它需要为每个不同的查询重新计算。另一方面,查询不可知模型能够通过预先计算图像数据索引来缩放。对于双编码器系统,可以通过近似最近邻(ANN)搜索和GPU加速来获得进一步的速度提高(约翰逊等人,(2019年版)。
本文提出了一个简单有效的文本到图像检索模型VisualSparta,它在准确性和速度上都优于现有的查询无关检索模型。通过对具有查询文本标记的视觉区域之间的细粒度交互进行建模,我们的模型能够利用大型预训练视觉文本模型的能力,并能够以实时响应的方式扩展到非常大的数据集。据我们所知,这是第一个将Transformer模型的强大功能与实时搜索相结合的模型,表明可以以显著减少内存和计算时间的方式来使用大型预训练模型。最后,我们的方法是令人尴尬的简单,因为它的图像表示本质上是一个加权的词袋,并可以在一个标准的倒排索引索引,以快速检索。与其他复杂的分布式矢量表示模型相比,该方法不依赖于ANN或GPU加速来扩展到非常大的数据集。
本文的贡献可以归纳为以下几点:(1)提出了一种新的检索模型,在两个基准数据集上取得了新的结果,MSCOCO和Flickr 30K。(2)加权袋的话被证明是一个有效的表示跨模态检索,可以有效地索引在一个倒排索引快速检索。(3)详细的分析和烧蚀研究表明,所提出的方法的优点和有趣的属性,为未来的研究方向发光。
2 相关工作
在学习文本和图像之间的联合表示方面已经做了大量的工作(Karpathy和Fei-Fei,2015; Huang等人,2018年; Lee等人,2018年; Wehrmann等人,2019年; Li等人,2020 b; Lu等人,2020年)的报告。在本节中,我们将回顾基于双编码器的检索模型和基于变换器的检索模型。
2.1双编码器匹配网络
文本到图像检索任务中的大多数工作都选择使用双编码器网络对来自文本和图像模态的信息进行编码。在Karpathy and Fei-Fei(2015)中,作者使用双向递归神经网络(BRNN)对文本信息进行编码,并使用区域卷积神经网络(RCNN)对图像信息进行编码,通过两个编码器的特征交互来计算最终的相似度得分。Lee等人(2018)提出了堆叠的交叉注意网络,其中文本特征通过两个注意层来学习与图像区域的交互。Wang等人(2019 a)将位置信息编码为另一个特征,并使用了两个深度RCNN特征(Ren等人,2016)和感兴趣区域(ROI)的细粒度位置特征作为图像表示。在Wang et al.(2020)中,作者利用维基百科中的信息作为外部语料库构建了一个图神经网络(GNN),以帮助对对象之间的关系进行建模。
2.2预训练语言模型(PLM)
近年来,大型预训练语言模型(PLM)在NLP领域的多任务上表现出了巨大的成功(Devlin等人,2018年; Yang等人,2019年; Dai等人,(2019年版)。在此之后,还对基于跨模态转换器的模型进行了研究,并证明了自我注意机制也有助于联合捕获视觉-文本关系(Li等人,2019年; Lu等人,2020年; Qi等人,2020年; Li等人,2020年b)。这些基于变换的模型首先在大规模的视觉文本数据集上进行预训练,然后从文本和图像中提取出丰富的语义信息。然后,针对文本到图像的检索任务对模型进行微调,并显示出大幅度的改进。然而,使用基于转换器的模型的问题在于,它在检索上下文中的速度非常慢:该模型需要计算所有查询和答案之间的成对相似性分数,使得几乎不可能在任何真实场景中使用该模型。我们提出的方法借用了大型预训练模型的能力,同时将推理时间减少了几个数量级。
PLM在信息检索中表现出了良好的效果,但由于模型结构复杂,检索速度较慢。IR社区最近开始致力于通过PLM中的情境化信息增强经典全文检索方法(Dai和Callan,2019; MacAvaney等人,2020年; Zhao等人,2020年)的报告。Dai和Callan(2019)提出了DeepCT,这是一种学习从大型基于变换器的模型的上下文化表示中生成查询重要性分数的模型。Zhao等人(2020)提出了稀疏Transformer匹配模型(sparse transformer matching model,斯巴达),该模型学习查询和文本答案之间的术语级交互,并在索引时间内为答案生成加权术语表示。我们的工作就是在这个方向上的工作,并将范围扩展到跨模态的理解和检索。
3. VisualSparta 检索器
在本节中,我们介绍了VisualSparta检索器,这是一种基于片段级的transformer模型,用于高效的文本-图像匹配。我们提出的模型重点在于两个方面:
- 召回性能:学习查询和图像区域之间的细粒度关系,以丰富跨模态理解。
- 速度性能:查询嵌入是非上下文化的,这使得模型可以将大部分计算移到离线阶段。
3.1 模型架构
3.1.1 查询表示
由于查询处理是在检索过程中在线进行的操作,编码查询的效率需要被充分考虑。之前的方法通过双向循环神经网络(bi-RNN)将查询句子输入模型,以生成基于上下文的token表示 (Lee et al., 2018; Wang et al., 2019a, 2020)。
我们选择放弃查询的顺序信息,只使用预训练的token嵌入来表示每个token。换句话说,我们不会为查询编码局部上下文信息,而是纯粹依赖每个token的独立词嵌入 E tok E_{\text{tok}} Etok。假设一个查询经过分词后为 q = [ w 1 , . . . , w m ] q = [w_1, ..., w_m] q=[w1,...,wm],则有:
w ^ i = E tok ( w i ) ( 1 ) \hat{w}_i = E_{\text{tok}}(w_i)\qquad(1) w^i=Etok(wi)(1)
其中, w i w_i wi 是查询的第 i i i 个token。因此,查询可以表示为 w ^ = { w ^ 1 , . . . , w ^ m } \hat{w} = \{\hat{w}_1, ..., \hat{w}_m\} w^={ w^1,...,w^m},并且 w ^ i ∈ R d H \hat{w}_i \in \mathbb{R}^{d_H} w^i∈RdH。通过这种方式,每个token都是独立表示的,与其局部上下文无关。这对于高效的索引和推理至关重要,如3.3节所述。
3.1.2 视觉表示
相比需要实时处理的查询信息,答案处理可以更加丰富和复杂,因为答案语料库可以在查询到达之前离线索引。因此,我们遵循最新的视觉-语言transformer方法 (Li et al., 2019, 2020b),并使用上下文化表示来处理答案语料库。
具体来说,对于一张图像,我们使用来自三个来源的信息来表示它:区域视觉特征、区域位置特征以及带有属性的标签特征,如图2所示。
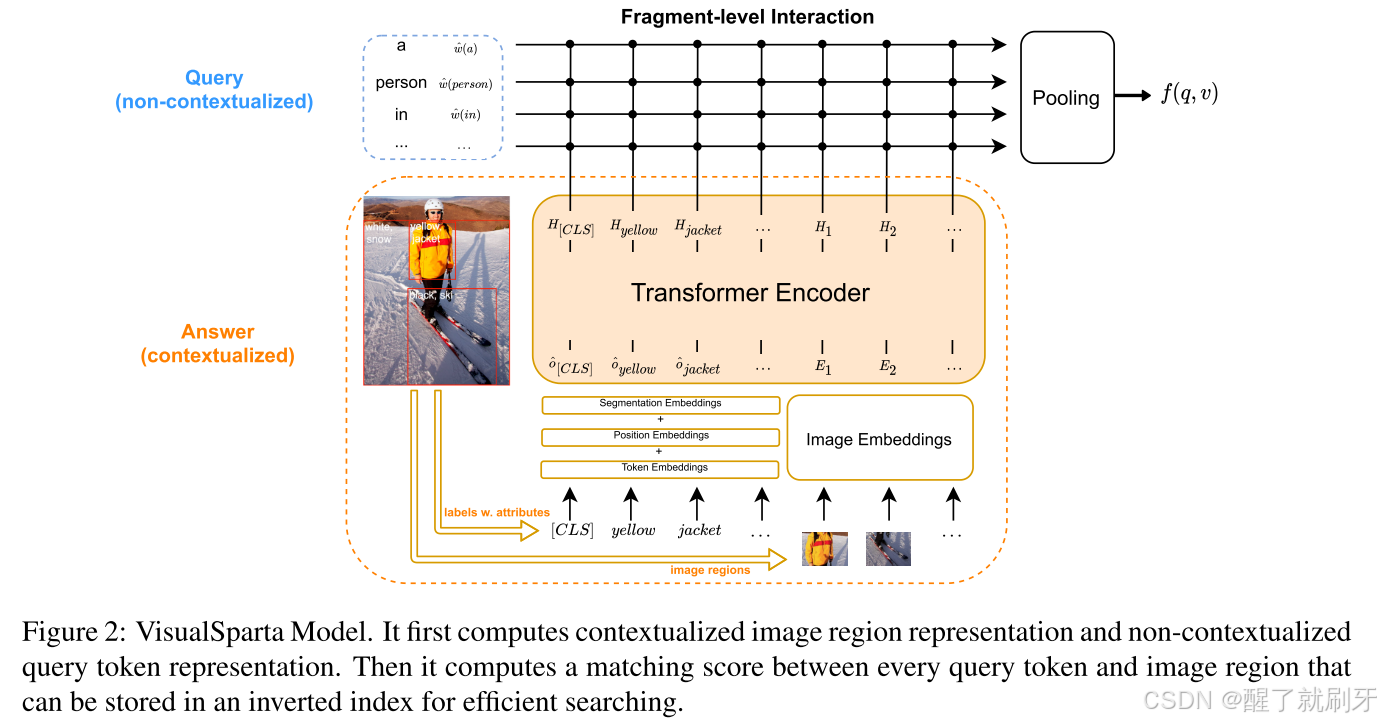
图2:VisualSparta模型。它首先计算上下文图像区域表示和非上下文查询令牌表示。然后计算每个查询标记与图像区域之间的匹配分数,该匹配分数可以存储在倒排索引中以进行高效搜索。
区域视觉特征和位置特征:给定一张图像 v v v,我们通过Faster-RCNN (Ren et al., 2016) 得到 n n n 个区域的视觉特征 v i v_i vi 及其对应的位置特征 l i l_i li
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









