




系列文章目录
文章目录
引言
正如我们在上一节中所讨论的, 机器翻译是序列转换模型的一个核心问题, 其输入和输出都是长度可变的序列。 为了处理这种类型的输入和输出, 我们可以设计一个包含两个主要组件的架构: 第一个组件是一个编码器(encoder): 它接受一个长度可变的序列作为输入, 并将其转换为具有固定形状的编码状态,比如隐状态(RNN中)或者特征(CNN中)。 第二个组件是解码器(decoder): 它将固定形状的编码状态映射到长度可变的序列。 这被称为编码器-解码器(encoder-decoder)架构, 如下图所示。

我们以英语到法语的机器翻译为例: 给定一个英文的输入序列:“They”“are”“watching”“.”。 首先,这种“编码器-解码器”架构将长度可变的输入序列编码成一个“状态”, 然后对该状态进行解码, 一个词元接着一个词元地生成翻译后的序列作为输出: “Ils”“regordent”“.”。 由于“编码器-解码器”架构是形成后续章节中不同序列转换模型的基础, 因此本节将把这个架构转换为接口方便后面的代码实现。
重新考察CNN
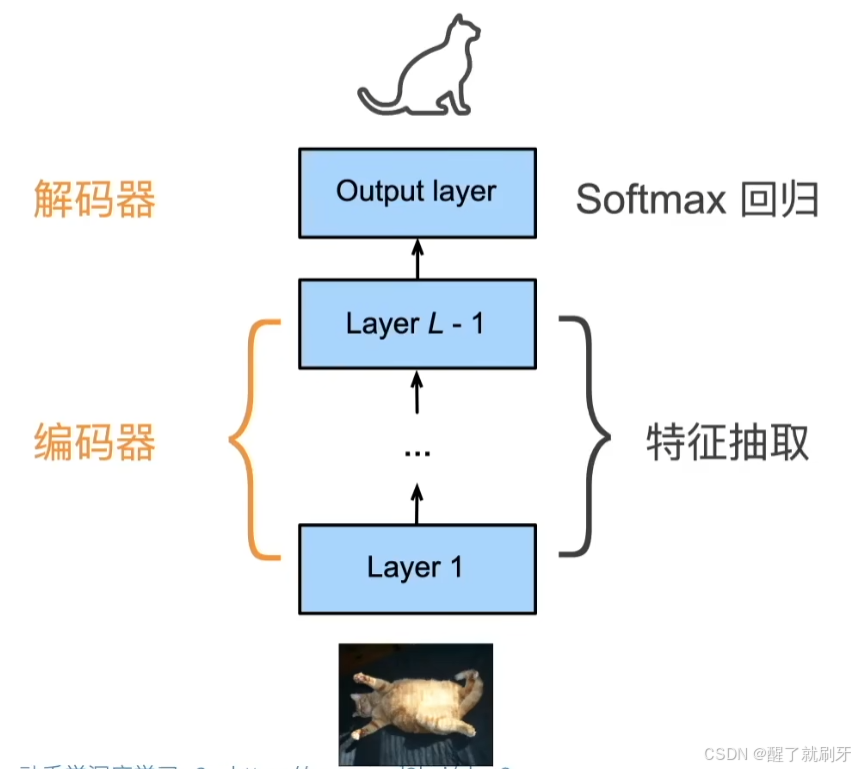
我们可以认为下面CNN的流程就是下面做特征提取(编码器),上面做预测(解码器)。
编码器:将输入编程成中间表达形式(特征)。
解码器:将中间表示解码成输出。
重新考察RNN
总结
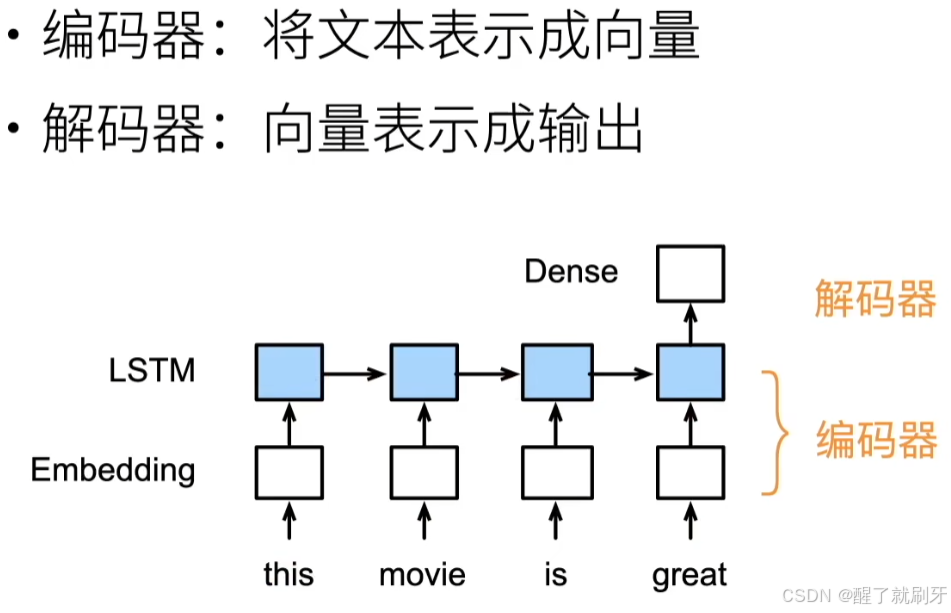
使用编码器-解码器架构的模型,编码器负责表示输入,解码器负责输出。
编码器
在编码器接口中,我们只指定长度可变的序列作为编码器的输入X。任何继承这个Encoder基类的模型将完成代码实现。
from torch import nn
class Encoder(nn.Module):
"""编码器-解码器架构的基本编码器接口"""
def __init__(self, **kwargs):
super 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









