




一、题目
Mobile ALOHA:通过低成本全身远程操作学习双手移动操作
传统模仿学习(Imitation Learning)缺点:聚焦与桌面操作,缺乏通用任务所需的移动性和灵活性
本论文优点:(1)在ALOHA系统上开发一个移动全身系统,用于模仿需要双手协作和全身控制的移动操作任务。(2)低成本收集数据,每个任务只需演示50次,然后将数据进行克隆,联合训练成功率可以达90%。
论文中可以实现的任务有哪些?
- 炒虾并上菜
- 打开双门壁壁柜放厨具
- 呼叫并进入电梯
- 打开厨房水龙头冲洗平底锅......

二、什么是模仿学习?
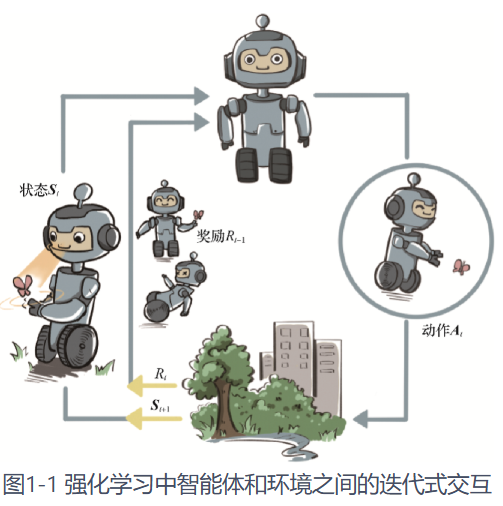
可能很多小伙伴都还没接触过模仿学习,下面先介绍一下什么是模仿学习。相信你之前一定听说过强化学习,强化学习是通过智能体与环境交互,以最大化累计奖励作为目标,不断试错并优化策略的学习过程。想要全面系统的了解强化学习强推小白入门资料强化学习入门(不是广,真的写的挺好的)。那么模仿学习则强调通过学习人类专家的示范行为,让智能体模仿专家策略的学习方式(强化学习是让智能体自己交互学习,无专家数据)。
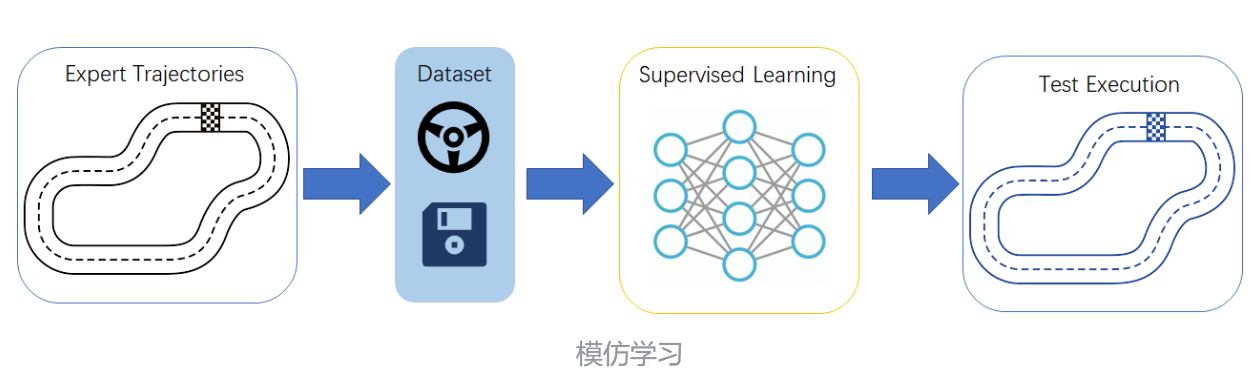
下面简单介绍一下模仿学习,可参考资料几种模仿学习介绍
2.1 行为克隆(Behavior Cloning, BC)
核心思想:直接拟合专家示范的 “状态 - 动作” 映射,将问题转化为监督学习任务。
模型结构:
- 设专家示范数据集为
,其中
为状态,
为专家动作。
- 目标是学习策略
,最小化预测动作与专家动作的分别差异,通常使用交叉熵损失(分类问题)或均方误差(回归问题)
,其中
是损失函数,如分类场景下:
技术细节:专家示范通常是 “最优路径”,而智能体执行时可能进入专家未覆盖的状态(分布偏移),导致性能下降(如自动驾驶中罕见路况)。
解决方法可以采用DAGGER 算法,通过迭代收集智能体在真实环境中的状态,让专家标注对应动作,扩充数据集以覆盖更多状态空间。数学迭代过程如下:
- 初始策略
由BC训练
- 用
与环境进行交互,手机状态集合
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1868
1868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











