






前言
在本文中,我会分享一些改进 RAG(检索增强生成)应用程序中检索的出色技术。最近在一个客户项目中使用了这些技术,将系统的召回率从大约 50-60% 一直提高到 95% 及以上。
召回率对于任何 RAG 应用程序来说都是一个非常重要的指标。它虽然只是衡量检索系统为给定用户问题进行搜索或找到正确文档的能力。但是,这会强烈影响生成的结果的好坏——无论我们是在构建聊天机器人还是其他类似的应用。
大多数人现在都知道这一点:如果你不为 LLM 提供必要的上下文,无论你在RAG链的末端做多少提示工程,它都无法产生好的结果。因此,在 RAG 中,获得良好结果的最大因素(通常)是良好的检索。我们衡量这一点的方法就是用召回率。
现在,来详细介绍这个客户项目,以便您可以准确的了解我们做了什么以及我们如何实现超过 95% 的召回率——从而成为一个非常可靠的系统。
设置:经典的 RAG 管线
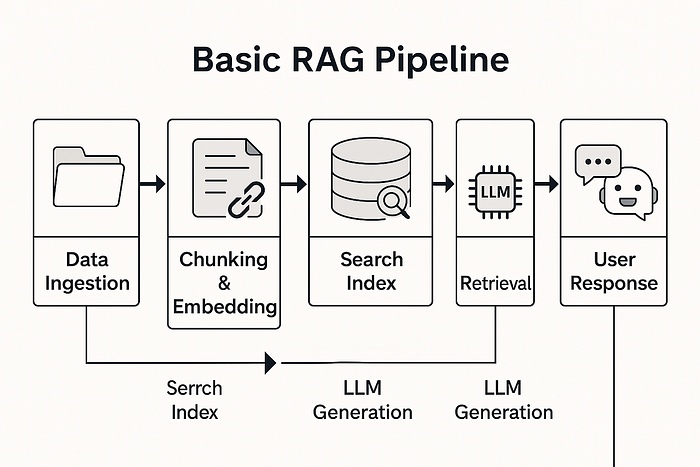
从高层次视角来看,这是一个非常经典的 RAG 项目。我们构建了一个供内部使用的聊天机器人,专门供客户服务人员更快地查找信息。
基本流程:
- 从不同的客户系统和数据库获取数据。
- 预处理数据:分块、嵌入和所有常见的 RAG 内容。
- 从这些文档块构建搜索索引。
- 将聊天机器人连接到该搜索索引,以便用户可以用自然语言提问。
机器人从索引中检索相关文档,然后使用该文档生成响应。简单、标准的 RAG。
初始版本:朴素的方法
我们的第一个朴素版本看起来像这样:
在索引方面:
- 我们清理了来自不同系统的数据。
- 把它切成小块。
- 创建了用于向量搜索的嵌入。
- 将这些块和嵌入向量加载到矢量数据库(在本例中为 Azure AI 搜索)中。
我们有各种各样的数据,但对于这个例子,我们将重点介绍两种文档类型:位置和****专家。
这位客户在水疗和健康空间。他们有:
- 水疗中心和健身房等位置,每个位置都有包括服务(例如护理、按摩)、机器、城市和地区在内的描述。
- 按摩治疗师和私人教练等**专家,**具有类似的服务描述。
我们将所有相关字段(描述、城市、地区)合并到一个内容字段中以进行文本搜索。我们还创建了该字段的嵌入以进行向量搜索。
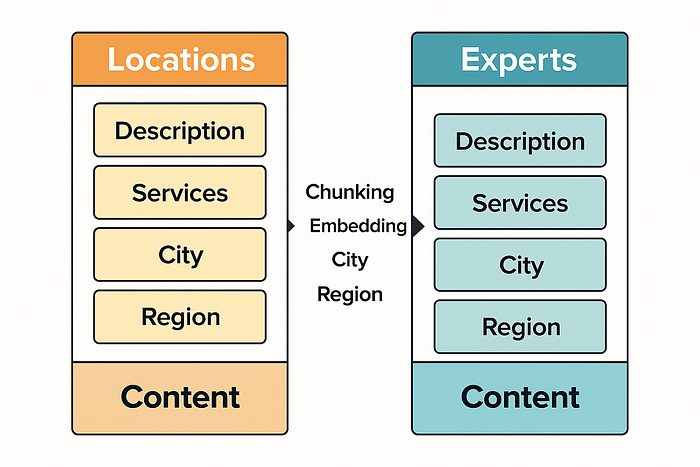
将“位置”和“专家”作为统一的内容文档进行可视化比较 — 旨在清晰、干净地编制索引
在前端:
用户会键入类似的内容:“赫尔辛基的瑞典式按摩”。
然后,我们将按以下任一方式运行该查询:
- 针对内容向量字段的向量搜索,或
- 针对内容字段的全文 BM25 搜索。
我们尝试了两者——但都遇到了问题。
为什么它不起作用
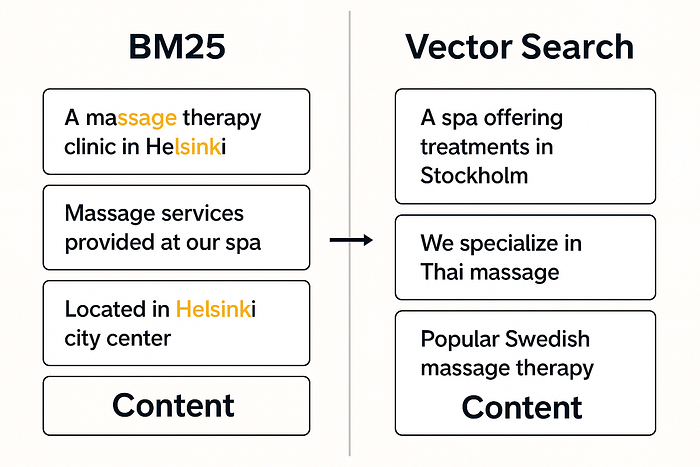
比较 BM25 与使用 ai 制作的矢量搜索结果
矢量搜索
这完全不行。
虽然向量搜索非常适合模糊匹配和语义相似性,但在我们的例子中,我们需要完全匹配——服务和位置。
相反,矢量搜索会返回类似的服务或城市(如芬兰的其他按摩店或其他首都),但并不完全是用户要求的内容。没有帮助。
BM25型
稍微好一点,但仍然不好。
BM25 根据搜索词的频率对文档进行排名。这听起来没问题,直到你意识到:
- 一份多次提及“按摩”和随机提及“瑞典肉丸”的文件可能比真正的赫尔辛基水疗中心提供瑞典式按摩的排名更高——只是因为术语频率。
它不优先考虑完全匹配,而这正是我们的主要需求。
其他问题
我们还遇到了:
- 共****轭问题——特别是因为该项目是芬兰语的。例如,“in Helsinki”以不同的方式变位,如果变位与用户查询不完全匹配,BM25 将找不到它。
解决方法:在 LLM 辅助下进行结构化搜索
以下是我们如何解决这个问题并将回忆率提高到 95% 以上的方法。
第 1 步:修改索引
我们在搜索索引中添加了一个新字段:services,作为结构化列表,而不是将它们嵌入到自由格式描述中。
但这些数据无法直接获得,因此我们在索引期间使用LLM提取服务。
例如,从位置或专家描述中,我们会提示 LLM 生成:
services: ["Swedish massage", "facial", "deep tissue massage"]
然后,我们完全删除了向量嵌入——它们对我们的需求没有用处。
第 2 步:转换查询
这才是真正的游戏规则改变者。
我们现在没有将用户的原始查询直接传递到搜索中,而是使用 LLM 将查询构建为如下格式:
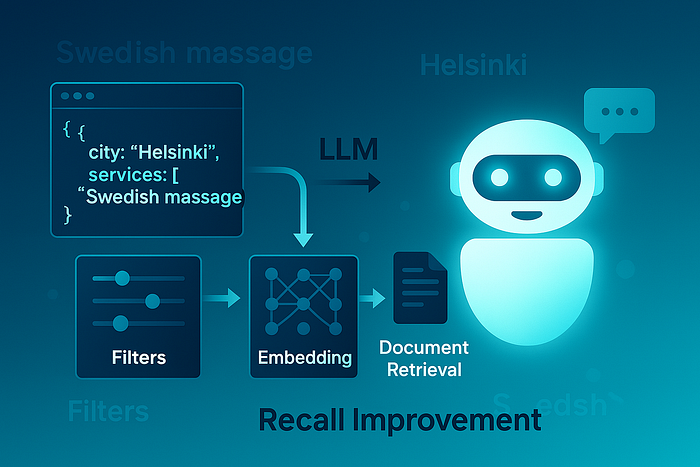
{"city.fi":"Helsinki","services":["Swedish massage"]}
这样,我们就可以对城市和服务字段运行精确的筛选查询,只获取完全匹配的文档。
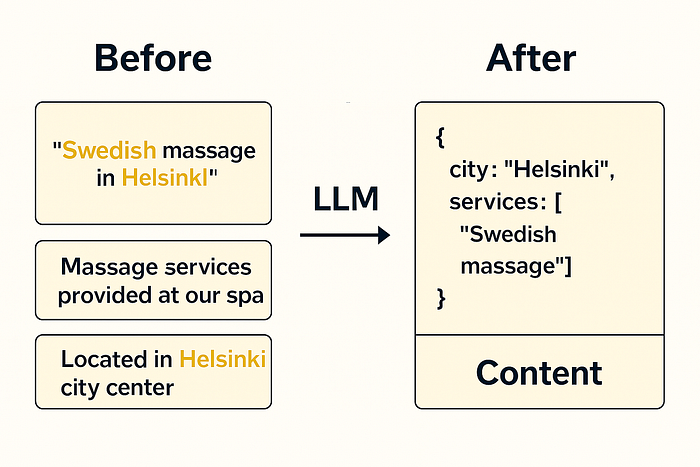
展示如何使用 AI 制作的结构对查询进行转换和索引
结果
在实施这些更改后,我们又进行了一轮用户测试,结果很明显:
- 召回率从 50-60% 跃升至近 100%。
- 以前的大多数问题都已得到解决。
- 只剩下少数边缘情况,主要是由于数据质量差。
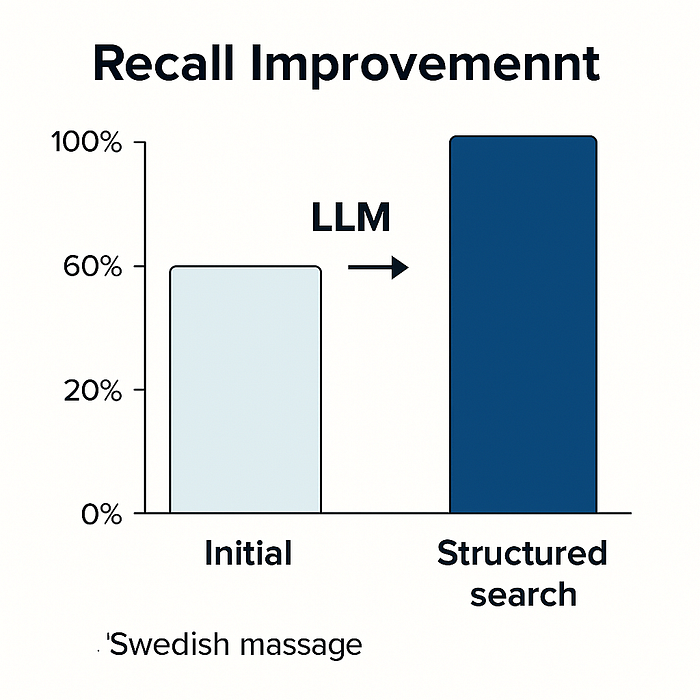
直观地显示使用 AI 进行的召回改进
权衡
- 索引现在更昂贵,因为我们使用 LLM 来提取服务。但这个工具是为数百名内部用户构建的,为他们节省了数千小时,因此非常值得。
- 前端有轻微延迟。我们添加了一个额外的 LLM 交互,以在检索之前构建查询。但它很快:输入和输出短,我们在这里使用了一个小模型。
最后的思考
这是一个巨大的胜利,通过相对简单和直观的改变来实现。
有时你不需要Agentic RAG 或研究论文中的其他流行技术。你只需要清楚地了解你的实际问题。
在我们的例子中,用户需要特定服务位置查询的精确匹配。这为我们指明了结构化过滤作为解决方案的方向。
虽然 RAG 通常意味着检索增强生成,但它也反过来工作。有各种巧妙的方法可以使用 LLM 来构建更好的检索。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。

最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下


这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 6465
6465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









