





论文题目为:Dynamic Graph Neural Networks for Sequential Recommendation,基于动态图卷积神经的序列化推荐系统
本文是对其代码的复现,已经有博主讲解过该论文内容,因此本文对概念部分就不细讲了
论文地址:ieee
代码地址:github
简介
将用户序列建模和用户之间的动态交互信息统一到一个框架中。提出了一种新的动态图神经网络顺序推荐方法(DGSR),
该方法通过动态图结构连接不同用户的顺序,设计了一个动态图注意力神经网络来实现不同用户及其序列在动态图中的信息传播和聚合。
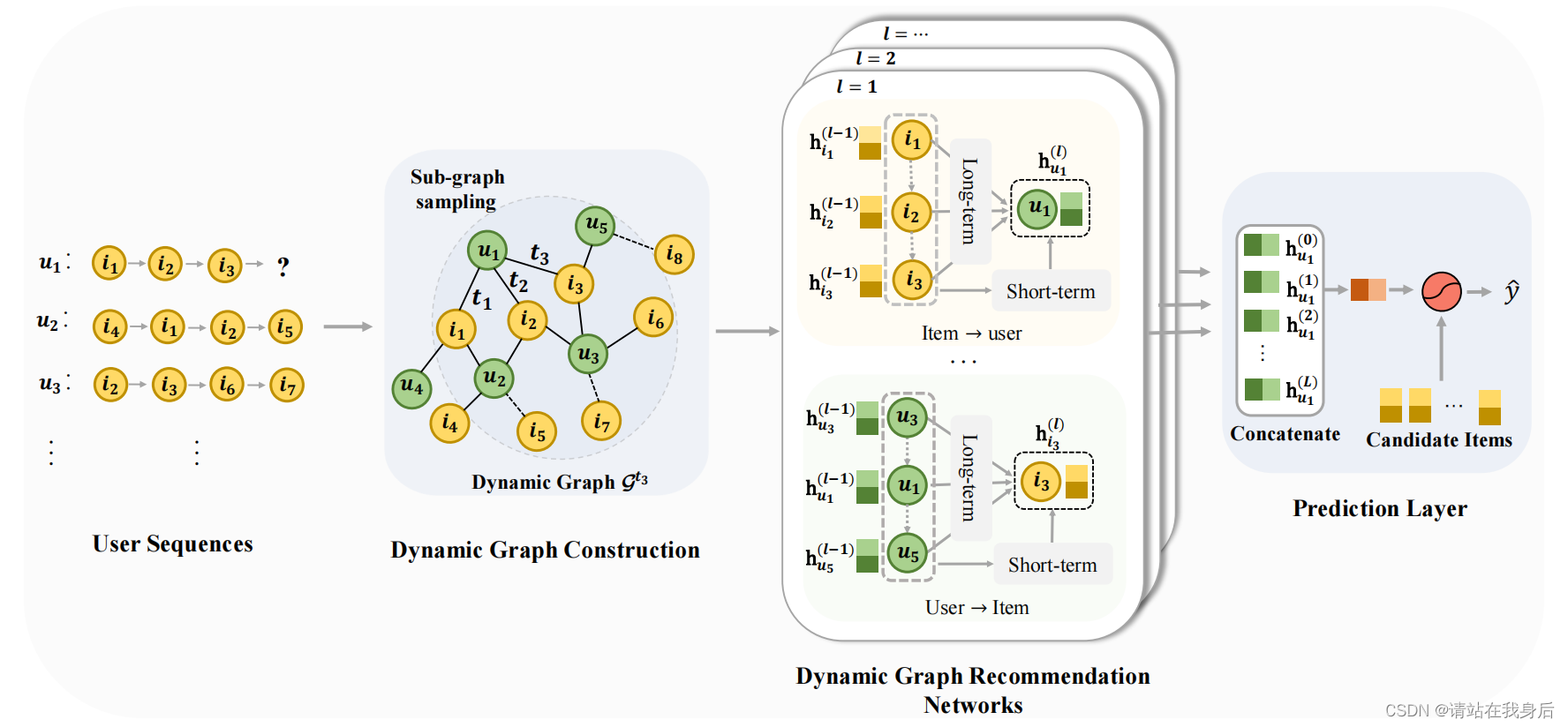
简单来讲,在t=目标-1的位置构建知识图谱,提取到子图后进行嵌入 ,利用网络提取到特征进行协同过滤,详细的将在下面根据论文讲解。
代码
推荐使用的环境,大家自行安装哦
- Python 3.6
- torch 1.7.1
- dgl 0.7.2
Generate data
代码首先要做是生成数据,以game 数据集举例:数据集存储在 Data/Games.csv
#!/user/bin/env/ bash
nohup python -u new_data.py \
--data=Games \
--job=10 \
--item_max_length=50 \
--user_max_length=50 \
--k_hop=2 \
>./results/ga_data&
直接看 new_data.py 代码,假设为第一次创建图谱
if __name__ == '__main__':
data_path = './Data/' + opt.data + '.csv'
graph_path = './Data/' + opt.data + '_graph'
data = pd.read_csv(data_path).groupby('user_id').apply(refine_time).reset_index(drop=True)
#创建图谱
if not os.path.exists(graph_path):
graph = generate_graph(data)
save_graphs(graph_path, graph)
else:
graph = dgl.load_graphs(graph_path)[0][0]调用panda 从csv中读取到数据集存入data 中,进行图谱的创建。
generate_graph
def generate_graph(data):
#对数据进行分组排序
data = data.groupby('user_id').apply(refine_time).reset_index(drop=True)
data = data.groupby('user_id').apply(cal_order).reset_index(drop=True)
data = data.groupby('item_id').apply(cal_u_order).reset_index(drop=True)
user = data['user_id'].values
item = data['item_id'].values
time = data['time'].values
#创建图谱
graph_data = {('item','by','user'):(torch.tensor(item), torch.tensor(user)),
('user','pby','item'):(torch.tensor(user), torch.tensor(item))}
graph = dgl.heterograph(graph_data)
#添加时间和序列特征
graph.edges['by'].data['time'] = torch.LongTensor(time)
graph.edges['pby'].data['time'] = torch.LongTensor(time)
graph.nodes['user'].data['user_id'] = torch.LongTensor(np.unique(user))
graph.nodes['item'].data['item_id'] = torch.LongTensor(np.unique(item))
return graph第一块首先将数据根据id进行分组,看到里面apply 的排序规则,举例:
def refine_time(data):
data = data.sort_values(['time'], kind='mergesort')
time_seq = data['time'].values
time_gap = 1
for i, da in enumerate(time_seq[0:-1]):
if time_seq[i] == time_seq[i+1] or time_seq[i] > time_seq[i+1]:
time_seq[i+1] = time_seq[i+1] + time_gap
time_gap += 1
data['time'] = time_seq
return data这一段做的是将数组根据time排序,循环保证排序id严格递增,后面的同样以此给item和user一个id序号。
第二块创建图谱:
#创建图谱
graph_data = {('item','by','user'):(torch.tensor(item), torch.tensor(user)),
('user','pby','item'):(torch.tensor(user), torch.tensor(item))}
graph = dgl.heterograph(graph_data)根据dgl库的规则,首先创建了一个字典,{规则:属性} 比如第一个规则就是 itme-user 之间的关系是by,因为本文要求具有图谱包含时序信息的五元组,因此构建双向的图谱,具体参考论文这部分:

第三部分,添加最基本的id属性信息到关系和点中,关系之间用时间作为特征。
graph.edges['by'].data['time'] = torch.LongTensor(time)
graph.edges['pby'].data['time'] = torch.LongTensor(time)
graph.nodes['user'].data['user_id'] = torch.LongTensor(np.unique(user))
graph.nodes['item'].data['item_id'] = torch.LongTensor(np.unique(item))
这样一个graph就构建好啦,设置好训练路径,也就是数据集存储的地方,默认建立个Newdata文件夹,没必要修改
#设置训练路径
train_path = f'Newdata/{opt.data}_{opt.item_max_length}_{opt.user_max_length}_{opt.k_hop}/train/'
val_path = f'Newdata/{opt.data}_{opt.item_max_length}_{opt.user_max_length}_{opt.k_hop}/val/'
test_path = f'Newdata/{opt.data}_{opt.item_max_length}_{opt.user_max_length}_{opt.k_hop}/test/'
#generate_user(41, data, graph, opt.item_max_length, opt.user_max_length, train_path, test_path, k_hop=opt.k_hop)
print('start:', datetime.datetime.now())generate_data
all_num = generate_data(data, graph, opt.item_max_length, opt.user_max_length, train_path, test_path, val_path, job=opt.job, k_hop=opt.k_hop)
def generate_data(data, graph, item_max_length, user_max_length, train_path, test_path, val_path, job=10, k_hop=3):
user = data['user_id'].unique()
a = Parallel(n_jobs=1)(delayed(lambda u: generate_user(u, data, graph, item_max_length, user_max_length, train_path, test_path, k_hop, val_path))(u) for u in user)
return a这一行很长,简单来说,以此读取用户id作为参数传入到 generate_user函数中,为了更快速,因此调用joblib库进行流水线加速。 下一段很长, 先整体粘在这。
def generate_user(user, data, graph, item_max_length, user_max_length, train_path, test_path, k_hop=3, val_path=None):
data_user = data[data['user_id'] == user].sort_values('time')
u_time = data_user['time'].values
u_seq = data_user['item_id'].values
split_point = len(u_seq) - 1
train_num = 0
test_num = 0
# 生成训练数据
if len(u_seq) < 3:
return 0, 0
else:
for j, t in enumerate(u_time[0:-1]):
if j == 0:
continue
if j < item_max_length:
start_t = u_time[0]
else:
start_t = u_time[j - item_max_length]
#构建子图
sub_u_eid = (graph.edges['by'].data['time'] < u_time[j+1]) & (graph.edges['by'].data['time'] >= start_t)
sub_i_eid = (graph.edges['pby'].data['time'] < u_time[j+1]) & (graph.edges['pby'].data['time'] >= start_t)
sub_graph = dgl.edge_subgraph(graph, edges = {'by':sub_u_eid, 'pby':sub_i_eid}, relabel_nodes=False)
u_temp = torch.tensor([user])
his_user = torch.tensor([user])
#选择给定节点权值最大(或最小)k个的相邻边,返回诱导子图
graph_i = select_topk(sub_graph, item_max_length, weight='time', nodes={'user':u_temp})
i_temp = torch.unique(graph_i.edges(etype='by')[0])
his_item = torch.unique(graph_i.edges(etype='by')[0])
edge_i = [graph_i.edges['by'].data[dgl.NID]]
edge_u = []
for _ in range(k_hop-1):
graph_u = select_topk(sub_graph, user_max_length, weight='time', nodes={'item': i_temp}) # item的邻居user
u_temp = np.setdiff1d(torch.unique(graph_u.edges(etype='pby')[0]), his_user)[-user_max_length:] #找到2个数组中集合元素的差异。
#u_temp = torch.unique(torch.cat((u_temp, graph_u.edges(etype='pby')[0])))
graph_i = select_topk(sub_graph, item_max_length, weight='time', nodes={'user': u_temp})
his_user = torch.unique(torch.cat([torch.tensor(u_temp), his_user]))
#i_temp = torch.unique(torch.cat((i_temp, graph_i.edges(etype='by')[0])))
i_temp = np.setdiff1d(torch.unique(graph_i.edges(etype='by')[0]), his_item)
his_item = torch.unique(torch.cat([torch.tensor(i_temp), his_item]))
edge_i.append(graph_i.edges['by'].data[dgl.NID])
edge_u.append(graph_u.edges['pby'].data[dgl.NID])
all_edge_u = torch.unique(torch.cat(edge_u))
all_edge_i = torch.unique(torch.cat(edge_i))
#获得最终图谱
fin_graph = dgl.edge_subgraph(sub_graph, edges={'by':all_edge_i,'pby':all_edge_u})
target = u_seq[j+1]
last_item = u_seq[j]
u_alis = torch.where(fin_graph.nodes['user'].data['user_id']==user)[0]
last_alis = torch.where(fin_graph.nodes['item'].data['item_id']==last_item)[0]
# 分别计算user和last_item在fin_graph中的索引
if j < split_point-1:
save_graphs(train_path+ '/' + str(user) + '/'+ str(user) + '_' + str(j) + '.bin', fin_graph,
{'user': torch.tensor([user]), 'target': torch.tensor([target]), 'u_alis':u_alis, 'last_alis': last_alis})
train_num += 1
if j == split_point - 1 - 1:
save_graphs(val_path + '/' + str(user) + '/' + str(user) + '_' + str(j) + '.bin', fin_graph,
{'user': torch.tensor([user]), 'target': torch.tensor([target]), 'u_alis': u_alis,
'last_alis': last_alis})
if j == split_point - 1:
save_graphs(test_path + '/' + str(user) + '/' + str(user) + '_' + str(j) + '.bin', fin_graph,
{'user': torch.tensor([user]), 'target': torch.tensor([target]), 'u_alis':u_alis, 'last_alis': last_alis})
test_num += 1
return train_num, test_num1、传入的user 是一个id,找到这个人的所有记录,并根据时间排序
data_user = data[data['user_id'] == user].sort_values('time')
提取到交互的item 和时间,这两个应该是一样多的
u_time = data_user['time'].values
u_seq = data_user['item_id'].values
split_point = len(u_seq) - 1
train_num = 0
test_num = 0根据时间id 构建子图,参考论文这部分:

选择大于开始时间小于当前时间 的数据构建子图
sub_u_eid = (graph.edges['by'].data['time'] < u_time[j+1]) & (graph.edges['by'].data['time'] >= start_t)
sub_i_eid = (graph.edges['pby'].data['time'] < u_time[j+1]) & (graph.edges['pby'].data['time'] >= start_t)
sub_graph = dgl.edge_subgraph(graph, edges = {'by':sub_u_eid, 'pby':sub_i_eid}, relabel_nodes=False)
u_temp = torch.tensor([user])
his_user = torch.tensor([user])dgl.edge_subgraph 是一个在 DGL(Deep Graph Library)库中定义的函数,用于从原始图中提取一个子图。这个子图由指定的边集合构成,并且可以选择是否重新标记节点的ID。举例
import dgl import torch # 假设有一个图 g g = dgl.graph((torch.tensor([0, 1, 2]), torch.tensor([1, 2, 3]))) # 假设我们有一个边的布尔索引数组,表示我们想要选择的边 edge_indices = torch.tensor([True, False, True]) # 使用 dgl.edge_subgraph 提取子图,不重新标记节点ID subgraph = dgl.edge_subgraph(g, {'by': edge_indices}, relabel_nodes=False) # 打印子图的边 print(subgraph.edges())
在这个示例中,我们首先创建了一个简单的图
g,然后定义了一个布尔索引数组edge_indices来选择我们想要的边。接着,我们使用dgl.edge_subgraph函数来提取子图,并且指定relabel_nodes=False以保留原始的节点ID。
使用 select_topk 函数选择与用户或物品相关的k个时间上最近邻节点,这个也是dgl里面的函数,就不举例了,大家知道是这么用就行
from dgl.sampling import sample_neighbors, select_topkimport dgl import torch # 创建一个简单的图 g = dgl.graph((torch.tensor([0, 1, 2, 1]), torch.tensor([1, 2, 3, 3]))) # 假设我们为边设置了权重属性 'weight' g.edata['weight'] = torch.tensor([1.0, 2.0, 3.0, 4.0]) # 选择节点 0 的 k=2 个最近邻节点,使用 'weight' 作为权重 k = 2 nodes = torch.tensor([0]) topk_mask = dgl.sampling.select_topk(g, k, nodes, weight='weight') # 打印被选中的边的索引 print(g.find_edges(topk_mask))为边设置了权重属性
'weight'。接着,我们使用select_topk函数来选择节点 0 的 k=2 个最近邻节点,并且使用'weight'作为权重。
#选择给定节点权值最大(或最小)k个的相邻边,返回诱导子图
graph_i = select_topk(sub_graph, item_max_length, weight='time', nodes={'user':u_temp})
i_temp = torch.unique(graph_i.edges(etype='by')[0])
his_item = torch.unique(graph_i.edges(etype='by')[0])
edge_i = [graph_i.edges['by'].data[dgl.NID]]
edge_u = []
for _ in range(k_hop-1):
graph_u = select_topk(sub_graph, user_max_length, weight='time', nodes={'item': i_temp}) # item的邻居user
u_temp = np.setdiff1d(torch.unique(graph_u.edges(etype='pby')[0]), his_user)[-user_max_length:] #找到2个数组中集合元素的差异。
#u_temp = torch.unique(torch.cat((u_temp, graph_u.edges(etype='pby')[0])))
graph_i = select_topk(sub_graph, item_max_length, weight='time', nodes={'user': u_temp})
his_user = torch.unique(torch.cat([torch.tensor(u_temp), his_user]))
#i_temp = torch.unique(torch.cat((i_temp, graph_i.edges(etype='by')[0])))
i_temp = np.setdiff1d(torch.unique(graph_i.edges(etype='by')[0]), his_item)
his_item = torch.unique(torch.cat([torch.tensor(i_temp), his_item]))
edge_i.append(graph_i.edges['by'].data[dgl.NID])
edge_u.append(graph_u.edges['pby'].data[dgl.NID])
all_edge_u = torch.unique(torch.cat(edge_u))
all_edge_i = torch.unique(torch.cat(edge_i))k_hop表明选择了 最近的3个item
获取到最终的图谱
#获得最终图谱
fin_graph = dgl.edge_subgraph(sub_graph, edges={'by':all_edge_i,'pby':all_edge_u})
target = u_seq[j+1]
last_item = u_seq[j]
u_alis = torch.where(fin_graph.nodes['user'].data['user_id']==user)[0]
last_alis = torch.where(fin_graph.nodes['item'].data['item_id']==last_item)[0]最后,计算用户和上一个物品在 fin_graph 中的索引。保存并 获取到数据集数量
# 分别计算user和last_item在fin_graph中的索引
if j < split_point-1:
save_graphs(train_path+ '/' + str(user) + '/'+ str(user) + '_' + str(j) + '.bin', fin_graph,
{'user': torch.tensor([user]), 'target': torch.tensor([target]), 'u_alis':u_alis, 'last_alis': last_alis})
train_num += 1
if j == split_point - 1 - 1:
save_graphs(val_path + '/' + str(user) + '/' + str(user) + '_' + str(j) + '.bin', fin_graph,
{'user': torch.tensor([user]), 'target': torch.tensor([target]), 'u_alis': u_alis,
'last_alis': last_alis})
if j == split_point - 1:
save_graphs(test_path + '/' + str(user) + '/' + str(user) + '_' + str(j) + '.bin', fin_graph,
{'user': torch.tensor([user]), 'target': torch.tensor([target]), 'u_alis':u_alis, 'last_alis': last_alis})
test_num += 1这一部分就结束啦,数据存储在Newdata中
generate_neg.py
需要运行generate_neg .py文件来生成数据以加快测试速度。您可以在文件中设置数据集。
dataset = 'Games'
data = pd.read_csv('./Data/' + dataset + '.csv')
user = data['user_id'].unique()
item = data['item_id'].unique()
user_num = len(user)
item_num = len(item)
data_neg = user_neg(data, item_num)
f = open(dataset+'_neg', 'wb')
pickle.dump(data_neg,f)
f.close()
调用一个名为 user_neg 的函数,该函数接收原始数据集 data 和物品总数 item_num 作为参数。这个函数的目的是生成负样本数据集
def user_neg(data, item_num):
item = range(item_num)
def select(data_u, item):
return np.setdiff1d(item, data_u)
return data.groupby('user_id')['item_id'].apply(lambda x: select(x, item))其目的是为每个用户生成负采样物品列表。负采样通常在推荐系统中使用,用于创建用户未交互过的物品集合,这有助于训练模型以区分用户可能感兴趣的和不感兴趣的物品。
np.setdiff1d,这是NumPy库中的一个函数,用于计算集合的差集。
负样本存在源目录下Games_neg
train and model
#!/user/bin/env/ bash
nohup python -u new_main.py \
--data=Beauty \
--gpu=0 \
--epoch=20 \
--user_long=orgat \
--user_short=att \
--item_long=orgat \
--item_short=att \
--user_update=rnn \
--item_update=rnn \
--batchSize=50 \
--layer_num=3 \
--lr=0.001 \
--l2=0.00001 \
--item_max_length=50 \
--user_max_length=50 \
--record \
--model_record \
>./jup&
跳过乱七八糟的,直接看
data
# loading data
data = pd.read_csv('./Data/' + opt.data + '.csv')
user = data['user_id'].unique()
item = data['item_id'].unique()
user_num = len(user)
item_num = len(item)
train_root = f'Newdata/{opt.data}_{opt.item_max_length}_{opt.user_max_length}_{opt.k_hop}/train/'
test_root = f'Newdata/{opt.data}_{opt.item_max_length}_{opt.user_max_length}_{opt.k_hop}/test/'
val_root = f'Newdata/{opt.data}_{opt.item_max_length}_{opt.user_max_length}_{opt.k_hop}/val/'
train_set = myFloder(train_root, load_graphs)
test_set = myFloder(test_root, load_graphs)
if opt.val:
val_set = myFloder(val_root, load_graphs)
train_data = DataLoader(dataset=train_set, batch_size=opt.batchSize, collate_fn=collate, shuffle=True, pin_memory=True, num_workers=12)
test_data = DataLoader(dataset=test_set, batch_size=opt.batchSize, collate_fn=lambda x: collate_test(x, data_neg), pin_memory=True, num_workers=8)
if opt.val:
val_data = DataLoader(dataset=val_set, batch_size=opt.batchSize, collate_fn=lambda x: collate_test(x, data_neg), pin_memory=True, num_workers=2)
class myFloder(Dataset):
def __init__(self, root_dir, loader):
self.root = root_dir
self.loader = loader
self.dir_list = load_data(root_dir)
self.size = len(self.dir_list)
def __getitem__(self, index):
dir_ = self.dir_list[index]
data = self.loader(dir_)
return data
def __len__(self):
return self.size
from dgl import load_graphs
dataset用的load_graphs是集成好的加载数据集的函数,因此创建的十分轻松
model
# 初始化模型
model = DGSR(user_num=user_num, item_num=item_num, input_dim=opt.hidden_size, item_max_length=opt.item_max_length,
user_max_length=opt.user_max_length, feat_drop=opt.feat_drop, attn_drop=opt.attn_drop, user_long=opt.user_long, user_short=opt.user_short,
item_long=opt.item_long, item_short=opt.item_short, user_update=opt.user_update, item_update=opt.item_update, last_item=opt.last_item,
layer_num=opt.layer_num).cuda()
optimizer = optim.Adam(model.parameters(), lr=opt.lr, weight_decay=opt.l2)
loss_func = nn.CrossEntropyLoss()用的交叉熵损失函数,看向DGSR的forward
def forward(self, g, user_index=None, last_item_index=None, neg_tar=None, is_training=False):
feat_dict = None
user_layer = []
g.nodes['user'].data['user_h'] = self.user_embedding(g.nodes['user'].data['user_id'].cuda())
g.nodes['item'].data['item_h'] = self.item_embedding(g.nodes['item'].data['item_id'].cuda())
if self.layer_num > 0:
for conv in self.layers:
feat_dict = conv(g, feat_dict)
user_layer.append(graph_user(g, user_index, feat_dict['user']))
if self.last_item:
item_embed = graph_item(g, last_item_index, feat_dict['item'])
user_layer.append(item_embed)
unified_embedding = self.unified_map(torch.cat(user_layer, -1))
score = torch.matmul(unified_embedding, self.item_embedding.weight.transpose(1, 0))
if is_training:
return score
else:
neg_embedding = self.item_embedding(neg_tar)
score_neg = torch.matmul(unified_embedding.unsqueeze(1), neg_embedding.transpose(2, 1)).squeeze(1)
return score, score_neg1、分别嵌入用户和item 数据
self.user_embedding = nn.Embedding(self.user_num, self.hidden_size)
self.item_embedding = nn.Embedding(self.item_num, self.hidden_size)
2、然后经过layber进行提取
self.layers = nn.ModuleList([DGSRLayers(self.hidden_size, self.hidden_size, self.user_max_length, self.item_max_length, feat_drop, attn_drop,
self.user_long, self.user_short, self.item_long, self.item_short,
self.user_update, self.item_update) for _ in range(self.layer_num)])3、统一映射到一个维度
self.unified_map = nn.Linear(self.layer_num * self.hidden_size, self.hidden_size, bias=False)
4、计算注意力得分
score = torch.matmul(unified_embedding, self.item_embedding.weight.transpose(1, 0))
f然后加权,orward就这样啦
看向layber内部,也就是每一个DGSRLayers,时间有限,我就粘贴在这里,
def forward(self, g, feat_dict=None):
if feat_dict == None:
if self.user_long in ['gcn']:
g.nodes['user'].data['norm'] = g['by'].in_degrees().unsqueeze(1).cuda()
if self.item_long in ['gcn']:
g.nodes['item'].data['norm'] = g['by'].out_degrees().unsqueeze(1).cuda()
user_ = g.nodes['user'].data['user_h']
item_ = g.nodes['item'].data['item_h']
else:
user_ = feat_dict['user'].cuda()
item_ = feat_dict['item'].cuda()
if self.user_long in ['gcn']:
g.nodes['user'].data['norm'] = g['by'].in_degrees().unsqueeze(1).cuda()
if self.item_long in ['gcn']:
g.nodes['item'].data['norm'] = g['by'].out_degrees().unsqueeze(1).cuda()
g.nodes['user'].data['user_h'] = self.user_weight(self.feat_drop(user_))
g.nodes['item'].data['item_h'] = self.item_weight(self.feat_drop(item_))
g = self.graph_update(g)
g.nodes['user'].data['user_h'] = self.user_update_function(g.nodes['user'].data['user_h'], user_)
g.nodes['item'].data['item_h'] = self.item_update_function(g.nodes['item'].data['item_h'], item_)
f_dict = {'user': g.nodes['user'].data['user_h'], 'item': g.nodes['item'].data['item_h']}
return f_dict
user_weight,item_weight,user_update_function,item_update_function
不断更新权重
self.user_weight = nn.Linear(self.hidden_size, self.hidden_size, bias=False)
self.item_weight = nn.Linear(self.hidden_size, self.hidden_size, bias=False)
def user_update_function(self, user_now, user_old):
if self.user_update_m == 'residual':
return F.elu(user_now + user_old)
elif self.user_update_m == 'gate_update':
pass
elif self.user_update_m == 'concat':
return F.elu(self.user_update(torch.cat([user_now, user_old], -1)))
elif self.user_update_m == 'light':
pass
elif self.user_update_m == 'norm':
return self.feat_drop(self.norm_user(user_now)) + user_old
elif self.user_update_m == 'rnn':
return F.tanh(self.user_update(torch.cat([user_now, user_old], -1)))
else:
print('error: no user_update')
exit()
具体的规则是根据论文来的,要讲其实就是讲一遍论文,大家可以自行看一遍论文内的传播部分,其实就是注意力的不断更新。
train
for epoch in range(opt.epoch):
stop = True
epoch_loss = 0
iter = 0
print('start training: ', datetime.datetime.now())
model.train()
if __name__ == '__main__':
for user, batch_graph, label, last_item in train_data:
iter += 1
score = model(batch_graph.to(device), user.to(device), last_item.to(device), is_training=True)
loss = loss_func(score, label.to(device))
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss += loss.item()
if iter % 400 == 0:
print('Iter {}, loss {:.4f}'.format(iter, epoch_loss/iter), datetime.datetime.now())
epoch_loss /= iter
model.eval()
print('Epoch {}, loss {:.4f}'.format(epoch, epoch_loss), '=============================================')
# val
if opt.val:
print('start validation: ', datetime.datetime.now())
val_loss_all, top_val = [], []
with torch.no_grad:
for user, batch_graph, label, last_item, neg_tar in val_data:
score, top = model(batch_graph.to(device), user.to(device), last_item.to(device), neg_tar=torch.cat([label.unsqueeze(1), neg_tar], -1).to(device), is_training=False)
val_loss = loss_func(score, label.cuda())
val_loss_all.append(val_loss.append(val_loss.item()))
top_val.append(top.detach().cpu().numpy())
recall5, recall10, recall20, ndgg5, ndgg10, ndgg20 = eval_metric(top_val)
print('train_loss:%.4f\tval_loss:%.4f\tRecall@5:%.4f\tRecall@10:%.4f\tRecall@20:%.4f\tNDGG@5:%.4f'
'\tNDGG10@10:%.4f\tNDGG@20:%.4f' %
(epoch_loss, np.mean(val_loss_all), recall5, recall10, recall20, ndgg5, ndgg10, ndgg20))
# test
print('start predicting: ', datetime.datetime.now())
all_top, all_label, all_length = [], [], []
iter = 0
all_loss = []
with torch.no_grad():
for user, batch_graph, label, last_item, neg_tar in test_data:
iter+=1
score, top = model(batch_graph.to(device), user.to(device), last_item.to(device), neg_tar=torch.cat([label.unsqueeze(1), neg_tar],-1).to(device), is_training=False)
test_loss = loss_func(score, label.cuda())
all_loss.append(test_loss.item())
all_top.append(top.detach().cpu().numpy())
all_label.append(label.numpy())
if iter % 200 == 0:
print('Iter {}, test_loss {:.4f}'.format(iter, np.mean(all_loss)), datetime.datetime.now())
recall5, recall10, recall20, ndgg5, ndgg10, ndgg20 = eval_metric(all_top)
if recall5 > best_result[0]:
best_result[0] = recall5
best_epoch[0] = epoch
stop = False
if recall10 > best_result[1]:
if opt.model_record:
torch.save(model.state_dict(), 'save_models/'+ model_file + '.pkl')
best_result[1] = recall10
best_epoch[1] = epoch
stop = False
if recall20 > best_result[2]:
best_result[2] = recall20
best_epoch[2] = epoch
stop = False
# ------select Mrr------------------
if ndgg5 > best_result[3]:
best_result[3] = ndgg5
best_epoch[3] = epoch
stop = False
if ndgg10 > best_result[4]:
best_result[4] = ndgg10
best_epoch[4] = epoch
stop = False
if ndgg20 > best_result[5]:
best_result[5] = ndgg20
best_epoch[5] = epoch
stop = False
if stop:
stop_num += 1
else:
stop_num = 0
print('train_loss:%.4f\ttest_loss:%.4f\tRecall@5:%.4f\tRecall@10:%.4f\tRecall@20:%.4f\tNDGG@5:%.4f'
'\tNDGG10@10:%.4f\tNDGG@20:%.4f\tEpoch:%d,%d,%d,%d,%d,%d' %
(epoch_loss, np.mean(all_loss), best_result[0], best_result[1], best_result[2], best_result[3],
best_result[4], best_result[5], best_epoch[0], best_epoch[1],
best_epoch[2], best_epoch[3], best_epoch[4], best_epoch[5]))使用交叉熵loss 计算,其实就是计算预测的连接是否存在
test就是预测用户与item之间是否存在连接
结束!!
仅供学习,有问题call我


















 2834
2834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











