




主要给大家展示下强大的图片风格迁移,也就是图生图,十分有趣
本文介绍的pytorch 版本,且精简过的,因此十分简单易懂,大家可以自行复现
大佬的github:cyclegan
论文:arxiv
介绍
CycleGAN,即循环生成对抗网络,出自发表于 ICCV17 的论文《Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks》,和它的兄长Pix2Pix(均为朱大神作品)一样,用于图像风格迁移任务。以前的GAN都是单向生成,CycleGAN为了突破Pix2Pix对数据集图片一一对应的限制,采用了双向循环生成的结构,因此得名CycleGAN。
简单来说就是两个生成器,两个辨别器,简单易懂,详细的推荐大家取看看论文
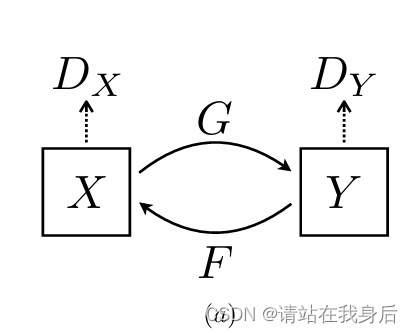

不多说了,直接进入代码部分
代码
首先还是数据提取部分,分开讲解,整体代码放在最后面。
因为我相信大家下载下来肯定也不是去看什么马转化为斑马,这里简单介绍,大家替换成自己的数据集即可
另外一点,这类图生图的算法最大的优点就在于不需要成对的图片,举例,A领域:真人照片,B领域:动漫图片 ——》转化风格就是真人转动漫头像。是不是很厉害
transforms_ = [ transforms.Resize(int(opt.size*1.12), Image.BICUBIC),
transforms.RandomCrop(opt.size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5)) ]
dataloader = DataLoader(ImageDataset(opt.dataroot, transforms_=transforms_, unaligned=True),
batch_size=opt.batchSize, shuffle=True, num_workers=opt.n_cpu)运用到torch里面的转换,大家可以自行修改参数
import glob
import random
import os
from torch.utils.data import Dataset
from PIL import Image
import torchvision.transforms as transforms
class ImageDataset(Dataset):
def __init__(self, root, transforms_=None, unaligned=False, mode='train'):
self.transform = transforms.Compose(transforms_)
self.unaligned = unaligned
self.files_A = sorted(glob.glob(os.path.join(root, '%s/A' % mode) + '/*.*'))
self.files_B = sorted(glob.glob(os.path.join(root, '%s/B' % mode) + '/*.*'))
def __getitem__(self, index):
item_A = self.transform(Image.open(self.files_A[index % len(self.files_A)]))
if self.unaligned:
item_B = self.transform(Image.open(self.files_B[random.randint(0, len(self.files_B) - 1)]))
else:
item_B = self.transform(Image.open(self.files_B[index % len(self.files_B)]))
return {'A': item_A, 'B': item_B}
def __len__(self):
return max(len(self.files_A), len(self.files_B))可以看到,数据集的提取没有什么花里胡哨,就是一个A领域,一个B领域,大家主要改下地址就行
# Loss plot
logger = Logger(opt.n_epochs, len(dataloader))网络构建部分
1、构建两个生成器两个辨别器,扔到gpu里面
netG_A2B = Generator(opt.input_nc, opt.output_nc)
netG_B2A = Generator(opt.output_nc, opt.input_nc)
netD_A = Discriminator(opt.input_nc)
netD_B = Discriminator(opt.output_nc)
if opt.cuda:
netG_A2B.cuda()
netG_B2A.cuda()
netD_A.cuda()
netD_B.cuda()2、应用初始化权重
netG_A2B.apply(weights_init_normal)
netG_B2A.apply(weights_init_normal)
netD_A.apply(weights_init_normal)
netD_B.apply(weights_init_normal)3、加载损失函数,这里就是三个损失,两个l1 一个mse
# Lossess
criterion_GAN = torch.nn.MSELoss()
criterion_cycle = torch.nn.L1Loss()
criterion_identity = torch.nn.L1Loss()
4、加载优化器和学习规划
# Optimizers & LR schedulers
optimizer_G = torch.optim.Adam(itertools.chain(netG_A2B.parameters(), netG_B2A.parameters()),
lr=opt.lr, betas=(0.5, 0.999))
optimizer_D_A = torch.optim.Adam(netD_A.parameters(), lr=opt.lr, betas=(0.5, 0.999))
optimizer_D_B = torch.optim.Adam(netD_B.parameters(), lr=opt.lr, betas=(0.5, 0.999))
lr_scheduler_G = torch.optim.lr_scheduler.LambdaLR(optimizer_G, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step)
lr_scheduler_D_A = torch.optim.lr_scheduler.LambdaLR(optimizer_D_A, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step)
lr_scheduler_D_B = torch.optim.lr_scheduler.LambdaLR(optimizer_D_B, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step)5、提前订好物理存储,我反正平时懒得这么干
# Inputs & targets memory allocation
Tensor = torch.cuda.FloatTensor if opt.cuda else torch.Tensor
input_A = Tensor(opt.batchSize, opt.input_nc, opt.size, opt.size)
input_B = Tensor(opt.batchSize, opt.output_nc, opt.size, opt.size)
target_real = Variable(Tensor(opt.batchSize).fill_(1.0), requires_grad=False)
target_fake = Variable(Tensor(opt.batchSize).fill_(0.0), requires_grad=False)
fake_A_buffer = ReplayBuffer()
fake_B_buffer = ReplayBuffer()训练部分
for epoch in range(opt.epoch, opt.n_epochs):
for i, batch in enumerate(dataloader):1、初始优化器和参数
# Set model input
real_A = Variable(input_A.copy_(batch['A']))
real_B = Variable(input_B.copy_(batch['B']))
###### Generators A2B and B2A ######
optimizer_G.zero_grad()
2、生成器
###### Generators A2B and B2A ######
optimizer_G.zero_grad()
# Identity loss
# G_A2B(B) should equal B if real B is fed
same_B = netG_A2B(real_B)
loss_identity_ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1310
1310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











