




常规的文本相似度计算有TF-IDF,Simhash、编辑距离等方式,但是常规的文本相似度计算方式仅仅能对文本表面相似度进行分析计算,并不能结合语义分析,而如果使用机器学习、深度学习的方式费时费力,效果也不一定能达到我们满意的状态,随着大模型技术的日渐成熟,我们是否可以利用大模型来完成文本相似度分析呢?
本文将结合文心一言4.0来介绍两种文本相似度分析的方法:
方式一
提供prompt,直接调用大模型接口,输出文本相似度结果。示例如下
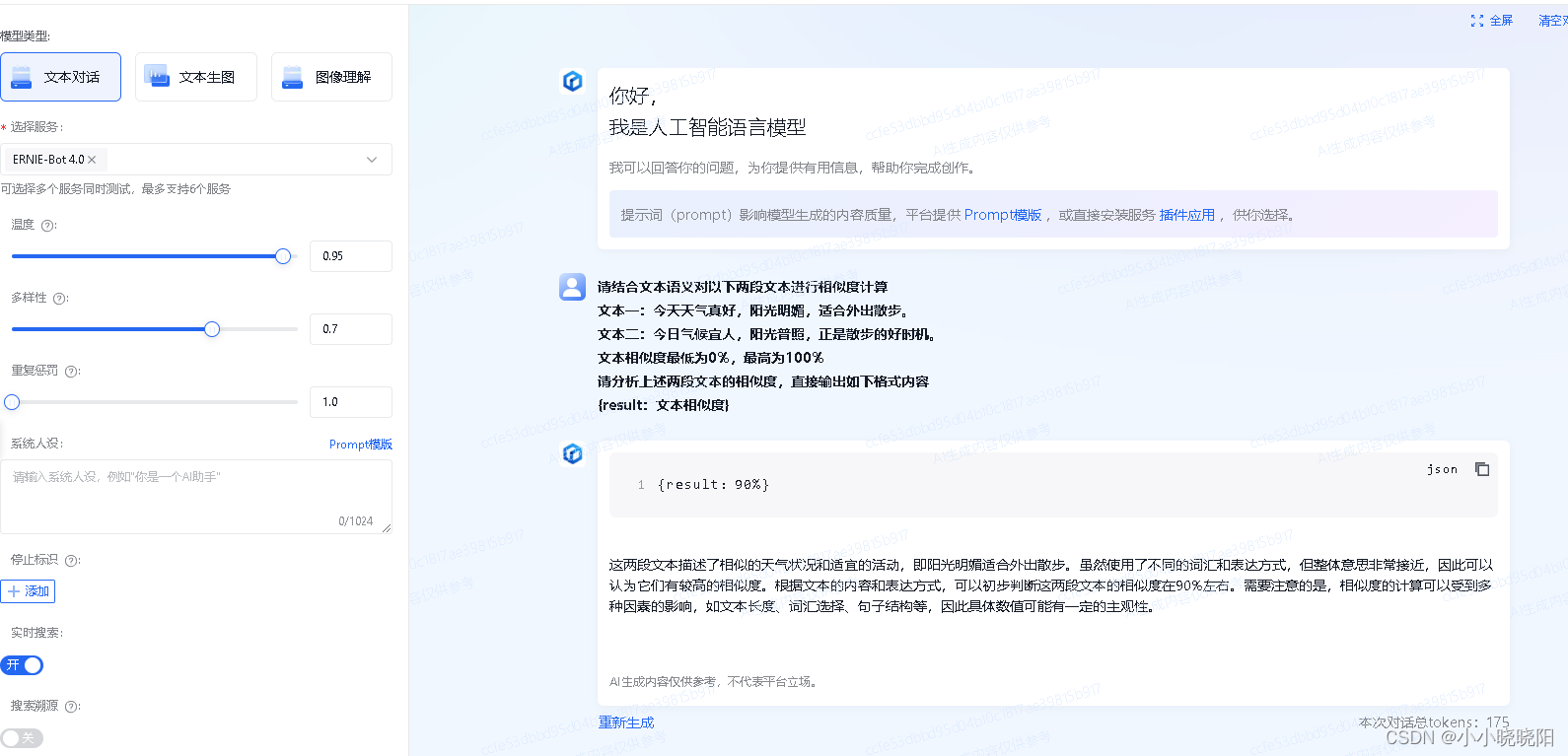
方式二
方式一虽然结果更加准确,可解释性也更强,但调用大模型分析会相对比较耗时,且资费较贵,所以我们也可以采用生成文本embedding向量的方式来计算文本相似度,以文心一言embedding接口为例,代码示例如下
def get_embeddings(inputs):
"""
生成文本embeddings
:param inputs:
:return:
"""
url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/embeddings/embedding-v1?access_token=" + get_access_token()
payload = json.dumps({
"input": inputs
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers,  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 319
319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









