



 本文提出一种新的基于注意的方法A2N模型,用于学习实体的查询相关表示以完成KG补全任务。该模型以查询为条件,对实体图邻域使用双线性关注生成嵌入表示,通过分配概率聚合相邻嵌入,结合DistMult评分函数生成元组,还通过添加逆关系增强图来改善训练。
本文提出一种新的基于注意的方法A2N模型,用于学习实体的查询相关表示以完成KG补全任务。该模型以查询为条件,对实体图邻域使用双线性关注生成嵌入表示,通过分配概率聚合相邻嵌入,结合DistMult评分函数生成元组,还通过添加逆关系增强图来改善训练。
提出了一种新的基于注意的方法来学习实体的查询相关表示,该方法自适应地组合实体的相关图邻域,从而实现更精确的KG完成
KG完成的任务要求从观察到的图形和表示为预测一个给定源实体和关系的查询的目标实体的推断缺失的实体关系,即完成元组(e,r,?),KG补全的大多数最先进方法学习实体和关系的向量嵌入,将其与(可能参数化的)评分函数结合使用,该评分函数对图中的每个元组进行评分。对这些嵌入进行了优化,使得观察到的图元组的得分高于随机元组。虽然这些模型取得了良好的性能,但它们学习了每个实体的固定维嵌入,这要求该嵌入必须记忆,然后能够概括推断实体的所有可能关系,这可能需要在KG中进行多次推理
我们提出了A2N,一种有效的模型(第2节),该模型以查询为条件,对实体的图邻域使用双线性关注来生成实体的嵌入表示。然后使用此查询特定和邻域通知表示对查询的目标实体进行评分。
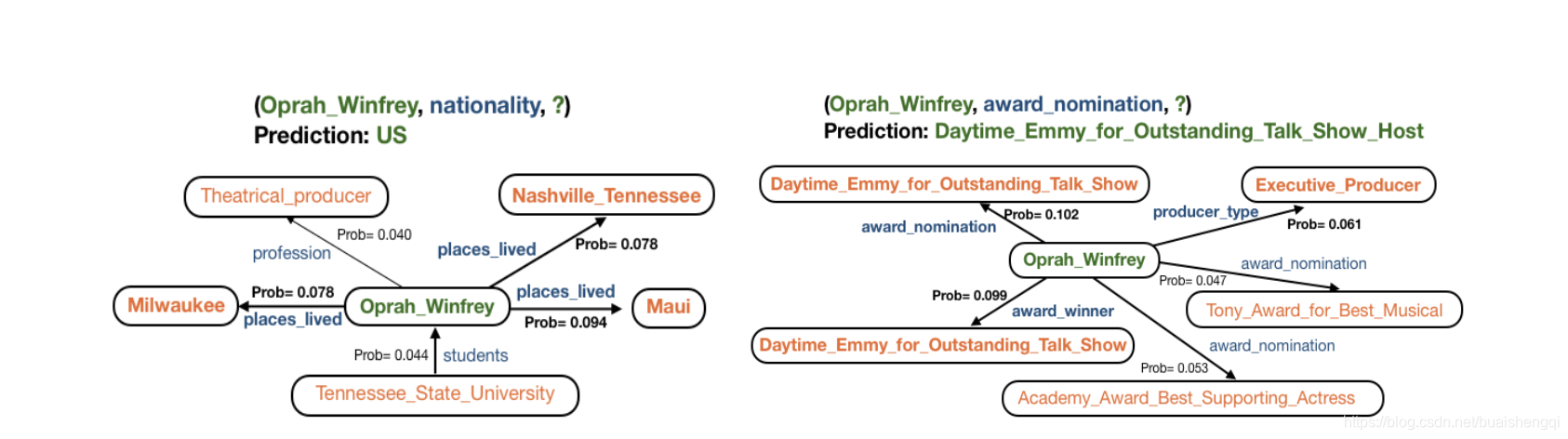
图 1 显示了模型如何对同一节点上的两个不同查询的图邻域进行评分的实际示例,为每个查询关注邻域的不同相关子集。我们展示了顶级邻居的一个子集。 根据查询为每个邻居分配一个概率,并根据这些概率对邻居表示进行池化以获得源实体的实体嵌入
问题表述和符号:让[X]代表整数集{1,...,X}。 给定一个 KG,G:={(s,r,t)},其中每个元组由源实体∈[Ve]、关系∈[Vr]和目标实体t∈[Ve]组成,其中Vr是关系的数量和Ve的数量 图中的实体。 目标是预测源实体和关系的给定查询的目标实体,q:= (s,r,?)– 这样预测的元组在 G 中不存在
描述我们的图形注意模型。考虑一个实体的邻域:Ns={(ri,ei)|(s,ri,ei)∈G} ,将图形的实体e和r分别与和
相关联(实体和关系的嵌入向量),实体S的邻居的嵌入(ri,ei)∈Ns是通过使用线性变换连接初始嵌入和投影来获得的。然后,该模型关注网络中的每个元素,为其在回答查询时的相关性分配一个概率,并通过聚合由相关性指定的相邻嵌入来生成实体的查询相关嵌入,具体地说,给定一个区间(s,r,?),我们分配给每个邻居∈Ns注意评分,然后对所有邻居进行标准化,以获得概率Pi。然后使用Pi作为权重对相邻嵌入进行聚集,以生成新的源嵌入
。这与初始源嵌入和投影源嵌入相连接,以获得最终源嵌入
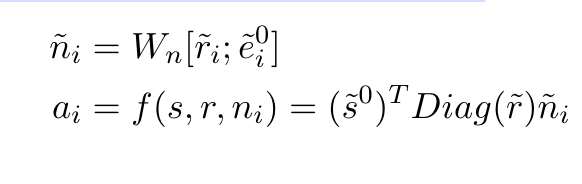
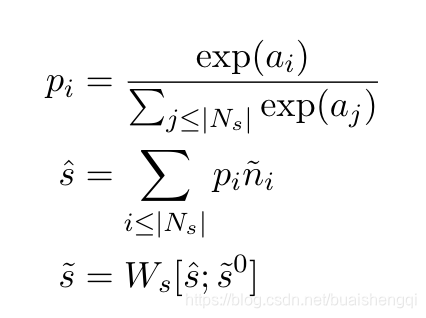
我们使用这种基于注意力的嵌入源实体 以及查询关系嵌入
和潜在目标实体的基础嵌入 ̃t0 在 DistMult 评分函数 Eq(1) 中生成元组 (s,r ,t)。 这是对所有可能的实体 st∈[Ve] 完成的,以获得查询的潜在目标实体的排名列表
中使用 DistMult 函数进行注意力评分,因为它允许模型学习将邻居投影到与目标实体相同的空间中,以便在得到结果时给予高分以纠正目标 使用 DistMult score 再次对嵌入进行评分。
训练:模型随机初始化,所有嵌入和投影参数通过从图中取一个元组(s,r,t)∈G,隐藏目标实体和随机采样负实体来训练,t−={e|(s, r,e)/∈G}。正元组和每个负元组的分数通过一个softmax来计算预测正确目标的似然度。 重复相同的过程以预测给定的源实体(r,t)。 我们还通过为每个图关系添加逆关系来增强图,这通过增加模型可能参与的邻域元素来改善训练。

















 1952
1952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









