



 本文介绍了时间知识图谱(TemporalKGs)在问答任务中的重要性,提出了CRONQUESTIONS,一个大规模的时间知识图谱问答数据集,比现有数据集扩大了340倍。CRONQUESTIONS包含需要时间推理的自然语言问题,用于评估和训练模型。现有的KGQA方法在此数据集上的表现不佳,为此作者提出了CRONKGQA,一个基于Transformer的解决方案,利用时间KG嵌入,实现了显著的性能提升。实验表明,虽然CRONKGQA在简单的时间推理问题上表现出色,但在复杂推理问题上仍有待改进,为未来的研究留下了空间。
本文介绍了时间知识图谱(TemporalKGs)在问答任务中的重要性,提出了CRONQUESTIONS,一个大规模的时间知识图谱问答数据集,比现有数据集扩大了340倍。CRONQUESTIONS包含需要时间推理的自然语言问题,用于评估和训练模型。现有的KGQA方法在此数据集上的表现不佳,为此作者提出了CRONKGQA,一个基于Transformer的解决方案,利用时间KG嵌入,实现了显著的性能提升。实验表明,虽然CRONKGQA在简单的时间推理问题上表现出色,但在复杂推理问题上仍有待改进,为未来的研究留下了空间。
摘要
时间知识图(Temporal KGs)通过在 KG 的每个边上提供时间范围(例如,开始和结束时间)来扩展常规知识图。虽然 KG 上的问答 (KGQA) 受到了研究界的一些关注,但 Temporal KG 上的 QA (Temporal KGQA) 是一个相对未开发的领域。缺乏广泛覆盖的数据集是限制该领域进展的另一个因素。缺乏广泛覆盖的数据集是限制该领域进展的另一个因素。 我们通过提供已知最大的时间 KGQA 数据集 CRONQUESTIONS 来应对这一挑战,层次分明,结构复杂.CRONQUESTIONS 将唯一已知的先前数据集扩展了 340 倍。 我们发现各种最先进的 KGQA方法在这个新数据集上远远达不到预期的性能。 作为回应,我们还提出了 CRONKGQA,这是一种transformer的解决方案,它利用了时间 KG 嵌入,并实现优于所有基线的性能,准确率比次佳提高 120%执行方法。 通过广泛的实验,我们详细了解 CRONKGQA 的工作原理以及情况
1 简介
时间知识图(Temporal KGs)是多关系图,其中每条边都与一个持续时间相关联。 这与不存在时间注释的常规 KG 形成对比。
例如,常规 KG 可能包含诸如(Barack Obama,hold position, President of USA)之类的事实,而临时 KG 也将包含开始和结束时间——(Barack Obama,hold position,President of USA,2008) , 2016)。 边也可以与一组不连续的时间间隔相关联。 这些时间范围在事实可以自动估计或用户贡献。 文献中已经提出了几个这样的 Temporal KG,重点是 KG 的完成
知识图问答 (KGQA) 的任务是使用 KG 作为知识库回答自然语言问题。 这与基于阅读理解的问答相反,其中问题通常伴随着上下文(例如,文本段落)并且答案是多项选择之一(Rajpurkar 等人,2016)或来自 上下文(Yang 等人,2018 年)。 在 KGQA 中,答案通常是 KG 中的一个实体(节点),回答问题所需的推理要么是基于单一事实的(Bordes 等,2015),要么是多跳(Yih 等,2015,Zhang 等) al. 2017)或基于连词/比较的推理(Talmor 和 Berant,2018)。 时间 KGQA 更进一步,其中:
1. 底层 KG 是一个 Temporal KG。
2. 答案是实体或持续时间。
3. 可能需要复杂的时间推理。
KG Embeddings 是 KG 中实体和关系的低维密集向量表示。 文献中已经提出了几种方法来嵌入 KG(Bordes et al. 2013, Trouillon等。 2016 年,Vashishth 等人。 2020)。 这些嵌入最初是为了 KG 完成的任务而提出的,即预测 KG 中缺失的边缘,因为大多数现实世界的 KG 都是不完整的。
然而,最近它们也被应用于 KGQA 的任务,在那里它们已被证明可以提高完整和不完整 KG 设置的性能(Saxena 等人 2020;Sun 等人 2020)
时间 KG 嵌入是另一个即将到来的领域,其中时间 KG 中的实体、关系和时间戳被嵌入到低维向量空间中(Dasgupta 等人 2018,Lacroix 等人。2020 年,Jain 等人。 2020 年,Goel 等人。 2019)。到目前为止,这里的主要应用也是时间 KG 完成。在我们的工作中,我们研究了时间 KG 嵌入是否可以应用于 时间 KGQA 的任务,以及它们与非时间嵌入或没有任何 KG 嵌入的现成方法相比如何。 在本文中,我们提出了 CRONQUESTIONS,这是 Temporal KGQA 的新数据集。 CRONQUESTIONS 由时间 KG 和伴随的自然语言问题组成。有创建此数据集时的三个主要指导原则:
1. 关联的 KG 必须提供时间注释。
2. 问题必须涉及时间元素推理。
3.标记实例的数量必须很大足以用于训练模型,而不是单纯的评价。
在上述原则的指导下,我们提出了一个由 125k 的时间 KG 组成的数据集实体和 328k 事实,以及一组 410k需要时间的自然语言问题推理。
在这个新数据集上,我们仅应用基于深度语言模型 (LM) 的方法,例如 T5 (Raffel et al., 2020)、BERT (Devlin et al., 2019) 和 KnowBERT (Peters et al., 2019) ,以及混合 LM+KG 嵌入方法,例如 Entities-as-Experts(Fevry 等人,2020 年)和 EmbedKGQA(Saxena 等人,2020 年)。 我们发现这些基线不适合时间推理。 作为回应,我们提出了 CRONKGQA,这是 EmbedKGQA 的增强,它在所有问题类型中都优于基线。 CRONKGQA在简单的时间推理问题上达到了非常高的准确率,但在需要更复杂推理的问题上却达不到要求。 因此,虽然我们得到了有希望的早期结果,
CRONQUESTIONS 为改进复杂的 Temporal KGQA 留下了充足的空间
2 相关工作
2.1 时间 QA 数据集
文献中提出了几个 KGQA 数据集(表 1)。
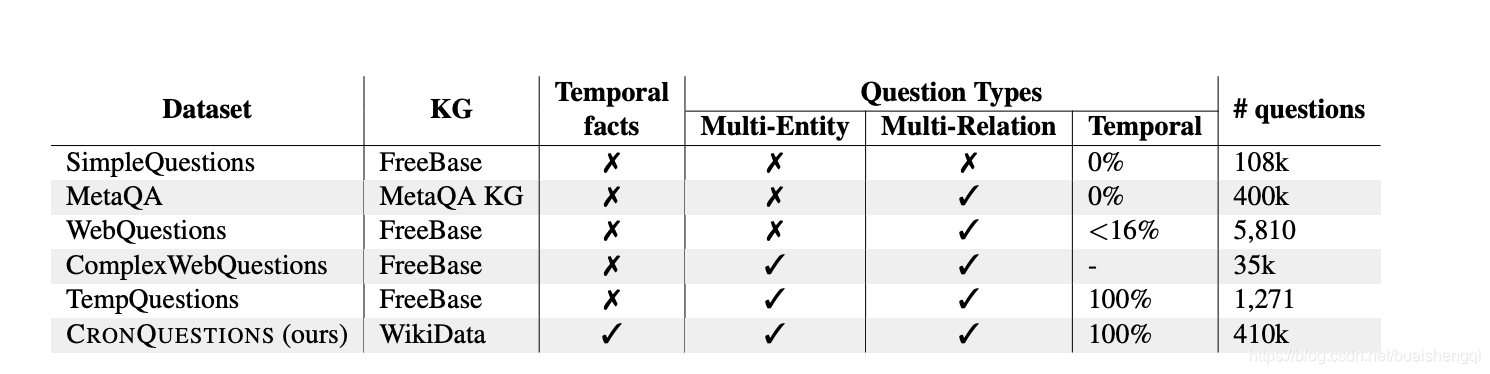
表 1:KGQA 数据集比较。 统计了 WebQuestions 的时间问题的百分比
来自贾等人。 (2018a)。 我们没有关于 ComplexWebQuestions 的时间问题的明确数量,但由于它是使用来自 WebQuestions 的问题自动构建的,我们预计百分比与 WebQuestions (16%) 相似。 详情请参阅第 2.1 节
在 SimpleQuestions (Bordes et al., 2015) 中,只需要从 KG 中提取一个事实来回答问题。 MetaQA(Zhang et al., 2017) 和 WebQuestionsSP (Yih et al., 2015) 需要多跳推理,其中必须遍历 KG 中的多个边才能找到答案。 ComplexWebQuestions(Talmor 和 Berant,2018 年)包含多跳和连词/比较类型的问题。然而, 这些都不是针对时间推理的,它们所基于的 KG 是非时间的。时间 QA 数据集主要在阅读理解领域进行研究。一个这样的 数据集是 TORQUE (Ning et al., 2020),其中给系统一个问题以及一些上下文(文本段落),并要求系统回答具有五个选项的多项选择题。这与 KGQA 形成对比,后者没有上下文,答案是潜在的数十万个实体之一
TempQuestions (Jia et al., 2018a) 是一个专门针对时间 QA 的 KGQA 数据集。 它由来自 WebQuestions、Free917(Cai 和 Yates,2013)和 ComplexQuestions(Bao 等,2016)的问题的子集组成,这些问题本质上是时间性的。 他们给出了“时间问题”的定义并使用了某些触发词(例如‘before’, ‘after’) 以及其他限制条件,以从这些数据集中过滤掉属于这个定义范围内的问题。 然而,这个数据集只包含 1271 个问题——仅用于评估— 并且它所基于的 KG(FreeBase 的一个子集(Bollacker 等,2008))不是时间 KG。 另一个缺点是 FreeBase 自 2015 年以来一直没有积极开发,因此其中存储的某些信息已过时,这是不准确的潜在来源
2.2 时间 QA 算法
据我们所知,最近的 KGQA 算法(Miller et al. 2016; Sun et al. 2019; Cohen et al. 2020; Sun et al. 2020)适用于非时间 KG,即包含形式(主题,关系,对象)。将这些扩展到包含形式(主题、关系、对象、开始时间、结束时间)的事实的时间 KG 是一个非平凡的任务。 TEQUILA (Jia et al., 2018b) 是一种专门针对时间 KGQA 的方法。 TEQUILA 将问题分解并重写为非时间子问题和时间约束。然后使用任何 KGQA 引擎检索子问题的答案。最后,TEQUILA 使用时间间隔上的约束推理来计算完整问题的最终答案。这种方法的一个主要缺点是使用预先指定的模板进行分解,以及对实体具有时间约束的假设。此外,由于它是为非时间 KG 制作的,因此没有直接的方法将其应用于时间范围内的事实的时间 KG。
3 CRONQUESTIONS:新的 TemporalKGQA 数据集
CRONQUESTIONS,我们的时间 KGQA 数据集由两部分组成:具有时间注释的 KG,以及一组需要时间推理的自然语言问题
3.1 时间KG
为了准备我们的时间 KG,我们首先从 Lacroix 等人提出的 WikiData 子集中获取所有带有时间注释的事实。 (2020)。我们删除了谓词“成员运动队”以平衡 KG,因为这个谓词构成了超过 50% 的事实。时间戳被离散化为年。这导致 KG 有 323k 个事实、125k 个实体和 203 个关系。然而,这种对事实的过滤错过了重要的世界事件。例如,使用上述技术创建的 KG 子集包含实体二战,但没有相关的事实告诉我们二战何时开始或结束。需要这些知识来回答诸如“二战期间谁是美国总统?”之类的问题。为了克服这个缺点,我们首先从维基数据中提取了具有“开始时间”和“结束时间”注释的实体。从这个集合,然后我们删除了游戏节目中的实体,电影或电视连续剧(因为这些不是重要的世界事件,但确实有开始和结束时间注释),然后删除关联事实少于 50 的实体。然后将这最后一组实体添加为格式中的事实(二战,重大事件,发生,1939 年,1945 年)。最终的 Temporal KG 由 328k 个事实组成,其中 5k 个是事件事实。
3.2 时间问题
为了生成 QA 数据集,我们从一组开始
用于时间推理的模板。 这些曾经是
使用来自以下五个最频繁的关系
我们的 WikiData 子集,即
• 运动队成员
• 持有的立场
• 获奖
• 配偶
• 雇主
这导致了 5 个关系和 5 个不同推理结构的 30 个独特的种子模板(请参见表 2 中的一些示例)。

表 2:不同类型的时间推理的示例问题。 {head}、{tail} 和 {time} 对应于形式(head、relation、tail、timestamp)中的实体/时间戳。 {event} 对应于事件事实中的实体,例如。 二战。 {type} 可以是 before/after 之一,{adj} 可以是 first/last 之一。 详情请参阅第 3.2 节。这些模板中的每一个都有一个相应的过程,可以在时间 KG 上执行以提取该模板的所有可能答案。 然而,类似于张等人。 (2017),我们选择不将此过程作为数据集的一部分,以删除QA 系统对这种正式的候选收集方法的不受欢迎的依赖。 这也允许轻松扩充数据集,因为只需要问答对。
本着与 ComplexWebQuestions 相同的精神,然后我们请人类注释者解释这些模板是为了生成更多语言多样性。 注释者被给予带有虚拟实体和时间的插槽填充模板,并被要求重新表述问题,以便在释义中出现虚拟实体/时间,并且提问的意思没变。 这产生了 246 个独特的模板。 然后我们使用了 Hu 等人开发的单语释义。 (2019) 使用这 246 个模板自动生成释义。 通过注释器验证它们的正确性后,我们最终得到了 654 个模板。 然后使用来自 WikiData 的实体别名填充这些模板到生成 410k 个独特的问答对。
最后,同时将数据拆分为训练/测试
折叠,我们确保
1. 训练问题的释义不存在于测试题。
2.试题之间没有实体重叠和训练问题。 允许事件重叠
第二个要求意味着,如果训练集中出现“谁是奥巴马之前的总统”这个问题,则测试集中不能包含任何提及实体“奥巴马”的问题。 虽然这策略可能看起来过于谨慎,它确保模型进行时间推理,而不是从训练期间看到的实体进行猜测。 刘易斯等人。 (2020) 注意到一个问题他们发现几乎 30% 的测试问题与训练问题重叠。 这个问题也出现在 MetaQA 数据集中,其中存在显着的重叠测试/训练实体和测试/训练问题释义之间的差异,导致即使使用部分 KG 数据(Saxena 等人,2020 年)在基线方法上的性能也令人怀疑 KG。
我们的数据创建协议的一个缺点是 问题/答案对是自动生成的。 因此,从语义的角度来看,问题分布是人为的。 (ComplexWebQuestions 也有类似的限制。)但是, 因为开发能够进行时间推理的模型是自然的一个重要方向语言理解,我们觉得我们的数据集 提供培训和评估的机会
KGQA 模型由于其规模较大,尽管其语言多样性低于自然。 在第 6.4 节,我们展示了训练数据的效果尺寸对模型性能有影响。总而言之,我们的每个示例都包含
1. 一个释义的自然语言问题。
2. 问题中的一组实体/时间。
3. 一组“黄金”答案(实体或时间)
实体被指定为 WikiData ID(例如,Q219237),时间是年(例如,1991)。 我们包括测试问题中的实体/时间集,因为类似于其他 KGQA 数据集MetaQA、WebQuestions、ComplexWebQuestions)以及使用这些数据集的方法(PullNet、
EmQL),实体链接被视为一个单独的问题,并假设完整的实体链接。 我们还包括种子模板和
训练折叠中的头/尾/时间注释,但省略这些来自测试折叠。
3.2.1 问题分类 为了便于分析,我们将问题分为“简单推理”和“复杂推理”问题(分布统计见表4)。 简单推理:这些问题需要一个事实来回答,答案可以是一个实体或一个时间实例。例如“谁是 2008 年的美国总统?”这个问题。需要一个事实来回答这个问题,即(巴拉克奥巴马,担任美国总统,2008 年,2016 年) 复杂的推理:这些问题需要多个事实来回答,并且可以更加多样化。例如“谁是美国的第一任总统? 美国?”这需要对与“美国总统”实体有关的多个事实进行推理。在我们的数据集中,所有不是“简单推理”问题的问题都被视为复杂问题。这些问题进一步分为“之前/之后”、“第一/最后”和“时间连接”类型—— 有关这些示例,请参阅表 2 问题。 ...
4 时间 KG 嵌入
我们研究了如何使用时间和非时间的 KG 嵌入以及预训练的语言模型来执行时间 KGQA。 我们先简单介绍一下具体的我们使用的 KG 嵌入模型,然后继续展示我们如何在我们的 QA 模型中使用它们。 在所有情况下,对于不完整 KG 中的正负元组,分数都被转化为合适的损失,并将这些损失最小化以训练实体、时间和关系表示。
4.1 complex模型


5 CRONKGQA: 文中的方法
我们从时间 KG 开始,应用时间不可知
或时间敏感的 KG 嵌入算法(ComplEx、TComplEx 或 TimePlex),并获得时间 KG 的实体、关系和时间戳嵌入。 我们将使用以下符号。
• E 是实体嵌入矩阵
• T 是时间戳嵌入矩阵
• E.T 是 E 和 T 矩阵的串联。
这用于对答案进行评分,因为答案可以是实体或时间戳。 如果实体/时间戳嵌入是 ![]() 中的复值向量,我们将它们扩展为大小为 2D 的实值向量,其中前半部分是实数部分,后半部分是原始向量的复数部分。
中的复值向量,我们将它们扩展为大小为 2D 的实值向量,其中前半部分是实数部分,后半部分是原始向量的复数部分。
我们首先应用 EmbedKGQA (Saxena et al.,2020) 直接到 Temporal KGQA 的任务。在其原始实现中,EmbedKGQA 使用 ComplEx(第 4.1 节)嵌入并且只能处理非时间 KG 和单个实体问题。为了将其应用于 CRONQUESTIONS,我们设置问题中遇到的第一个实体是 EmbedKGQA 需要的“头实体”。与此同时,我们将实体嵌入矩阵 E 设置为我们的 KG 实体的 ComplEx 嵌入,并将 T 初始化为一个随机可学习矩阵。 EmbedKGQA 然后对 E.T 进行预测。接下来,我们修改 EmbedKGQA 使其可以 使用时间 KG 嵌入。我们使用 TComplEx
(第 4.2 节)用于获取实体和时间戳嵌入。 CRONKGQA(图 1)使用两种评分函数,一种用于预测实体,一种用于预测时间。使用预训练的 LM(在我们的例子中是 BERT)CRONKGQA 找到了一个嵌入 qe 的问题。然后投影得到两个嵌入,qeent 和 qetime,它们分别是实体和时间预测的问题嵌入


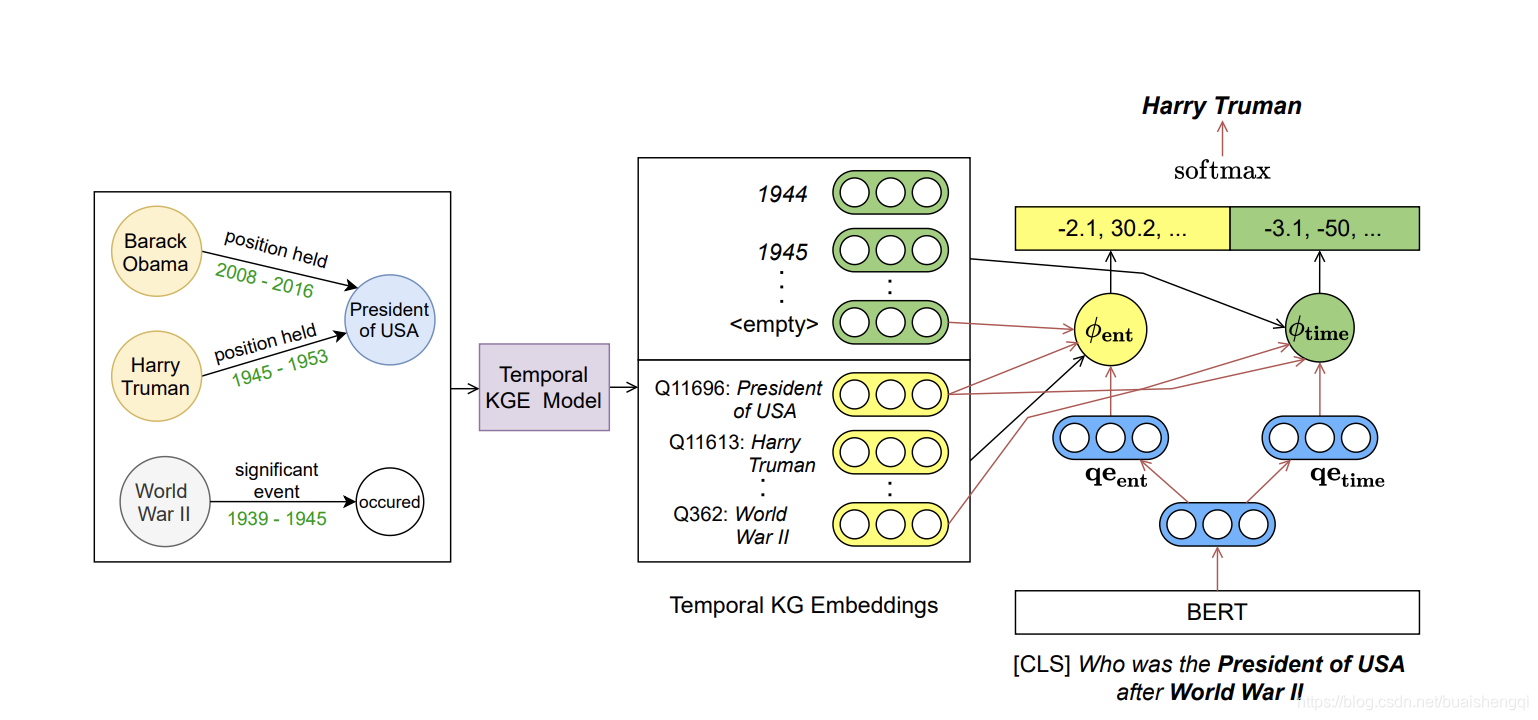 图 1:CRONKGQA 方法。 (i) 时间 KG 嵌入模型(第 4 节)用于为时间知识图中的每个时间戳和实体生成嵌入 (ii) BERT 用于获得两个问题嵌入:qeent 和 qetime。 (iii) 问题中实体/时间提及的嵌入与使用等式 4 和 5 的问题嵌入相结合,以获得实体和时间预测的得分向量。 (iv) 分数向量是使用连接和 softmax 来获取答案概率。 详情请参阅第 5 节。
图 1:CRONKGQA 方法。 (i) 时间 KG 嵌入模型(第 4 节)用于为时间知识图中的每个时间戳和实体生成嵌入 (ii) BERT 用于获得两个问题嵌入:qeent 和 qetime。 (iii) 问题中实体/时间提及的嵌入与使用等式 4 和 5 的问题嵌入相结合,以获得实体和时间预测的得分向量。 (iv) 分数向量是使用连接和 softmax 来获取答案概率。 详情请参阅第 5 节。
6 实验与诊断 在本节中,我们旨在回答以下问题:
1. 基线和 CRONKGQA 如何在 CRONQUESTIONS 任务上执行? (第 6.2 节。)
2. 在特定的推理任务上,某些方法是否比其他方法表现更好? (第 6.3 节。)
3. 训练数据集大小(问题数量)对模型性能的影响有多大? (第 6.4 节。)
4. 时间 KG 嵌入比非时间 KG 嵌入有什么优势吗? (第 6.5 节。)
6.1 其他方法比较
Petroni 等人已经证明了这一点。 (2019) 和 Raffel 等人。 (2020) 大型 LM,例如 BERT 及其变体,可以捕获现实世界的知识(从其庞大的百科全书式训练中收集)语料库),可以直接应用于 QA 等任务。 在这些基线中,我们并没有专门将我们的时间 KG 版本提供给模型——而是希望模型具有真实世界的知识来计算答案。

















 2896
2896




 到【灌水乐园】发言
到【灌水乐园】发言







