







《DeepSeek大模型高性能核心技术与多模态融合开发(人工智能技术丛书)》(王晓华)【摘要 书评 试读】- 京东图书
在上一节中,我们已经对混合专家模型(MoE)做了详尽的介绍。接下来,我们将进入实战环节,利用MoE模型来完成评论情感分类任务。我们将以第4章中的情感分类任务为蓝本,借鉴其框架与流程,作为本节实战内容的基础。
在模型构建环节,我们将采取一个创新性的举措:将原本的注意力层替换为MoE层。这一调整的目的是借助MoE层所特有的机制,来提升模型在处理复杂情感分类任务时的表现与准确性。
5.2.1 基于混合专家模型的MoE评论情感分类实战
为了完成这次基于MoE的评论情感分类实战,我们将遵循第4章中情感分类任务的设计思路,对训练主体部分进行构建。在模型设计方面,我们只需将注意力层替换为MoE层,即可开始我们的实战演练。单独的MoE层如图5-7所示。
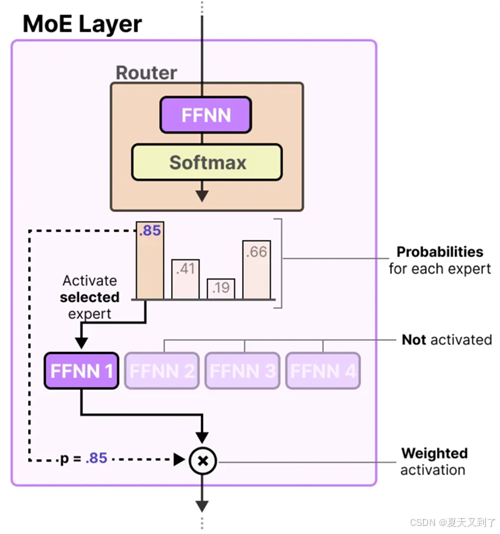
图5-7 单独的MoE层
通过这样的调整,我们期待MoE模型能够在评论情感分类任务上展现出卓越的性能。完整训练代码如下所示。
import torch
from 第五章 import baseMOE
from tqdm import tqdm
class Classifier(torch.nn.Module):
def __init__(self):
super(Classifier, self).__init__()
self.embedding_layer = torch.nn.Embedding(3120, 312)
self.encoder = torch.nn.ModuleList([baseMOE.SparseMoE(312,4,2) for _ in range(3)])
self.logits = torch.nn.Linear(14976, 2)
def forward(self, x):
embedding = self.embedding_layer(x)
for layer in self.encoder:
embedding = layer(embedding)
embedding = torch.nn.Flatten()(embedding)
logits = self.logits(embedding)
return logits
from torch.utils.data import DataLoader
import get_dataset
BATCH_SIZE = 128
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
model = Classifier().to(DEVICE)
train_dataset = get_dataset.TextSamplerDataset(get_dataset.token_list, get_dataset.label_list)
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
optimizer = torch.optim.AdamW(model.parameters(), lr=2e-4)
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=1200, eta_min=2e-5, last_epoch=-1)
criterion = torch.nn.CrossEntropyLoss(ignore_index=-100)
# 假设验证数据集已经准备好
val_dataset = get_dataset.TextSamplerDataset(get_dataset.val_token_list, get_dataset.val_label_list)
val_loader = DataLoader(val_dataset, batch_size=BATCH_SIZE, shuffle=False)
for epoch in range(12):
# 训练阶段
model.train()
pbar = tqdm(train_loader, total=len(train_loader))
for token_inp, label_inp in pbar:
token_inp = token_inp.to(DEVICE)
label_inp = label_inp.to(DEVICE).long()
logits = model(token_inp)
loss = criterion(logits, label_inp)
optimizer.zero_grad()
loss.backward()
optimizer.step()
lr_scheduler.step() # 执行优化器
pbar.set_description(f"epoch:{epoch + 1}, train_loss:{loss.item():.5f}, lr:{lr_scheduler.get_last_lr()[0] * 1000:.5f}")
# 验证阶段
model.eval()
total_val_loss = 0
correct = 0
with torch.no_grad():
for token_inp, label_inp in val_loader:
token_inp = token_inp.to(DEVICE)
label_inp = label_inp.to(DEVICE).long()
logits = model(token_inp)
loss = criterion(logits, label_inp)
total_val_loss += loss.item()
# 计算准确率
_, predicted = torch.max(logits, 1)
correct += (predicted == label_inp).sum().item()
avg_val_loss = total_val_loss / len(val_loader)
val_accuracy = correct / len(val_dataset)
print(f'Epoch {epoch + 1}, Validation Loss: {avg_val_loss:.5f}, Validation Accuracy: {val_accuracy:.5f}')
此时经过12轮的模型训练,最终结果如下:
……
Epoch 10, Validation Loss: 0.47300, Validation Accuracy: 0.80937
Epoch 11, Validation Loss: 0.53913, Validation Accuracy: 0.80312
Epoch 12, Validation Loss: 0.55707, Validation Accuracy: 0.81250
可以看到,此时的结果提高约为2个百分点,具体请读者运行代码自行验证。
另外,值得关注的是,在MoE(Mixture of Experts,混合专家模型)的框架下,MoE层通常可以划分为两种类型:稀疏专家混合模型(Sparse Mixture of Experts)与密集专家混合模型(Dense Mixture of Experts)。它们的对比如图5-8所示。
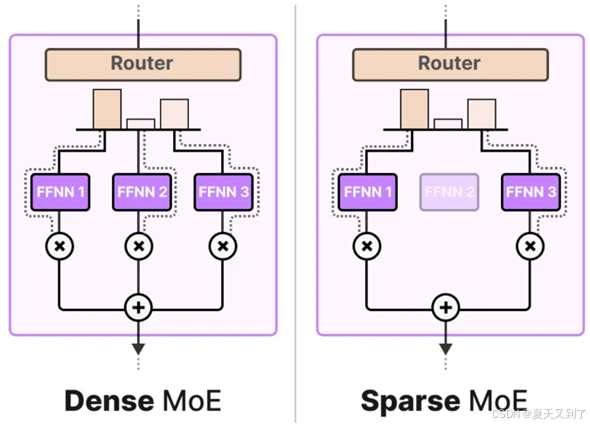
图5-8 稀疏MoE与密集MoE的对比
这两种模型都依赖于路由器机制来选择合适的专家进行处理,但它们在专家的选择上有所不同。稀疏MoE模型在每次前向传播时仅激活少数几个专家,这种策略有助于提升计算效率和模型的专注度,使得每个被选中的专家都能充分发挥其专长。相比之下,密集MoE模型则会考虑所有的专家,但会根据输入的不同以不同的权重分布来选择各个专家。这种全面考虑的策略虽然计算成本相对较高,但能够更全面地整合各个专家的意见,从而在处理某些复杂任务中展现出更优越的性能。
5.2.2 混合专家模型中负载平衡的实现
在上面的代码实现中,针对专家的负载均衡,我们使用了TopkRouter进行设置,这是一种对路由器进行负载平衡的方法,其使用了一个简单的扩展策略,称为 KeepTopK。这种策略的核心思想是,通过动态选择负载最低或性能最优的K个专家节点来处理请求,从而确保系统的稳定性和响应速度。
具体来说,KeepTopK策略会实时监控各个专家节点的负载情况,并根据预设的评估标准,如响应时间、CPU使用率、内存占用率等,对节点进行排序。当新的请求到达时,TopkRouter会根据当前的排序结果,将请求路由到性能最佳的K个节点之一。这种方法不仅能够有效平衡负载,减少某些节点的过载风险,还能确保用户请求得到快速且可靠的处理。整体计算结果说明如下。
(1)首先计算所有的输出权重,如图5-9所示。
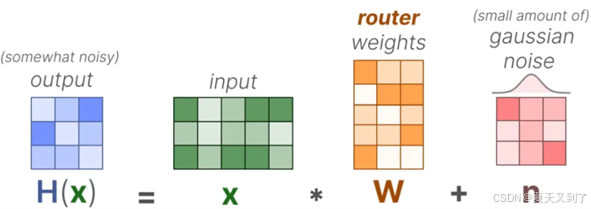
图5-9 加载了KeepTopK运算的输出
(2)然后,除了希望激活的前 k 个专家(例如 2 个)以外的所有专家权重都将被设为-∞
,如图5-10所示。
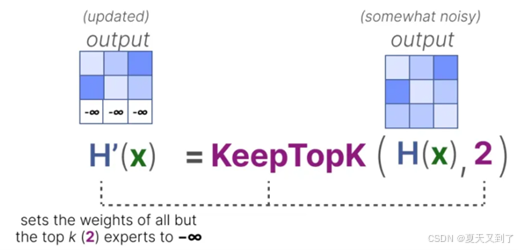
图5-10 去除额外的专家
(3)将这些专家权重设为 -∞ 时,softmax操作后的输出概率将变为 0,如图5-11所示。
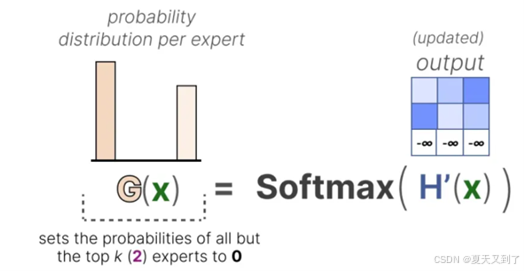
图5-11 经过softmax计算后输出概率置为0
(4)此时通过KeepTopK 策略,会将每个 token 路由到若干选定的专家。这种方法被称为 Token 选择策略(Token Choice),如图5-12所示,它允许一个给定的 token 被路由到一个专家(图5-12左图),或者被分配给多个专家(图5-12右图)。
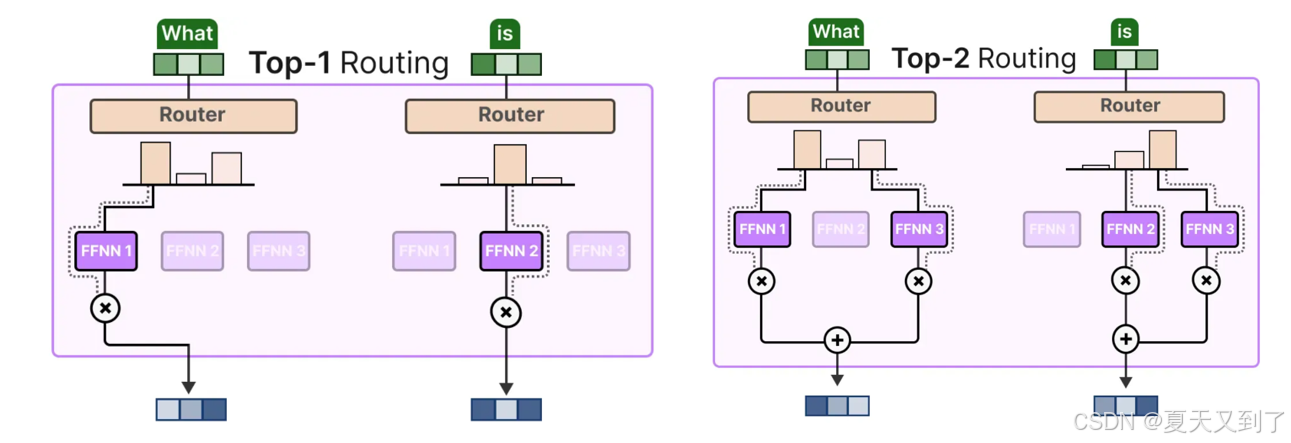
图5-12 token选择策略
路由器(Router)或门控网络(Gate Network)部分。这一组件在 MoE 架构中扮演着至关重要的角色,负责决定哪些数据(通常以 token 的形式)应该被发送到哪些专家进行处理。路由器网络根据输入数据的特性,动态地生成一个分配方案,确保每个 token 都能被路由到最合适的专家。这种动态路由机制使得 MoE 能够在处理不同输入时展现出高度的灵活性和适应性。通过优化路由器网络的设计,MoE 可以在保持计算效率的同时,最大化地利用各个专家的专长,从而提升整体模型的性能。
选择单个专家可以提升我们在计算时的速度,而选择多个专家时可以对各个专家的贡献进行加权,并将其整合起来,从而提高一定的准确性,至于选择哪种方式还需要在实际中进行权衡和处理。
5.2.3 修正后的MoE门控函数
然而,在混合专家模型的实际使用中,我们本质上追求的是一种均衡状态,即避免所有token都集中于某一组“热门”的expert上。为了实现这一目标,我们需要在系统中引入一种机制,以确保token的分配既不过于集中,也不过于分散。因此,我们采用了一种策略,那就是在来自门控线性层的logits上添加标准正态噪声,其代码如下所示。
class NoisyTopkRouter(torch.nn.Module):
def __init__(self, n_embed, num_experts, top_k):
super(NoisyTopkRouter, self).__init__()
self.top_k = top_k
self.topkroute_linear = torch.nn.Linear(n_embed, num_experts)
# add noise
self.noise_linear = torch.nn.Linear(n_embed, num_experts)
def forward(self, mh_output):
# mh_ouput is the output tensor from multihead self attention block
logits = self.topkroute_linear(mh_output)
# Noise logits
noise_logits = self.noise_linear(mh_output)
# Adding scaled unit gaussian noise to the logits
noise = torch.randn_like(logits) * torch.nn.functional.softplus(noise_logits)
noisy_logits = logits + noise
top_k_logits, indices = noisy_logits.topk(self.top_k, dim=-1)
zeros = torch.full_like(noisy_logits, float('-inf'))
sparse_logits = zeros.scatter(-1, indices, top_k_logits)
router_output = torch.nn.functional.softmax(sparse_logits, dim=-1)
return router_output, indices
而在具体使用上,我们可以直接替换稀疏注意力层的对应代码,替换后的新的稀疏混合专家模型如下所示。
# 定义一个稀疏的混合专家(MoE)模型
class SparseMoE(torch.nn.Module):
def __init__(self, n_embed, num_experts, top_k):
super(SparseMoE, self).__init__()
self.router = NoisyTopkRouter(n_embed, num_experts, top_k)#路由器,用于选择专家
# 创建一个专家列表,每个专家都是一个Expert实例
self.experts = torch.nn.ModuleList([Expert(n_embed) for _ in range(num_experts)])
self.top_k = top_k # 选择前K个专家
def forward(self, x):
# 通过路由器得到专家的概率分布和索引
gating_output, indices = self.router(x)
final_output = torch.zeros_like(x) # 初始化最终输出为与输入形状相同的全零张量
# 将输入和路由器的输出展平,以便后续处理
flat_x = x.view(-1, x.size(-1))
flat_gating_output = gating_output.view(-1, gating_output.size(-1))
# 遍历每个专家,根据其概率分布对输入进行处理
for i, expert in enumerate(self.experts):
# 找出当前专家是前K个专家的token
expert_mask = (indices == i).any(dim=-1)
flat_mask = expert_mask.view(-1) # 展平操作
# 如果当前专家对至少一个token是前K个专家之一
if flat_mask.any():
# 选出这些token的输入
expert_input = flat_x[flat_mask]
# 将这些token输入给当前专家进行处理
expert_output = expert(expert_input)
# 获取当前专家对这些token的概率分布
gating_scores = flat_gating_output[flat_mask, i].unsqueeze(1)
# 根据概率分布对专家的输出进行加权
weighted_output = expert_output * gating_scores
# 将加权后的输出累加到最终输出中对应的位置
final_output[expert_mask] += weighted_output.squeeze(1)
return final_output # 返回最终输出
这种噪声的引入,实际上为模型注入了一种随机性,使得token在选择expert时不再完全依赖于原始的logits值。通过这种方式,我们可以有效地打破可能存在的“热门”expert的垄断地位,让其他相对“冷门”的expert也有机会得到token的分配。这不仅提高了模型的整体鲁棒性,还有助于防止模型在训练过程中出现过早收敛或陷入局部最优解的问题。
此外,KeepTopK策略还具备灵活性和可扩展性,可以根据实际运行情况进行动态调整。例如,在高峰期,系统可以自动增加K的值,以容纳更多的处理节点,从而提升整体的处理能力。而在低峰期,则可以减小K值,以节省资源并提高能效。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









