







《DeepSeek大模型高性能核心技术与多模态融合开发(人工智能技术丛书)》(王晓华)【摘要 书评 试读】- 京东图书
本文节选自《DeepSeek大模型高性能核心技术与多模态融合开发》,出版社和作者授权发布。混合专家模型(MoE)的主要作用是作为前馈神经网络层(Feedforward Neural Network,FFNN)的替代品。通过引入这种替代方案,我们获得了诸多显著的好处。
首先,MoE通过集成多个“专家”子模型,显著增强了模型的表达能力和容量。相较于单一的前馈层,这种结构能够更细致地捕捉数据的复杂特征,从而在处理高度非线性问题时展现出更优越的性能。其次,MoE模型通过条件计算实现了高效的资源利用。在传统的FFNN中,所有神经元在每次前向传播时都会被激活,这可能导致计算资源的浪费。而在MoE中,只有部分专家会被选择性地激活,这种稀疏性不仅降低了计算成本,还使得模型能够更专注于当前任务相关的特征。如图5-13所示。
此外,MoE还具备出色的可扩展性。随着数据量的增长和任务的复杂化,我们可以通过增加专家数量来轻松扩展模型,而无需从头开始训练整个网络。这种灵活性使得MoE能够轻松应对不断变化的应用场景和需求。最后,通过引入专家之间的竞争机制,MoE还能够促进模型内部的多样性和鲁棒性。不同的专家可以学习到不同的数据特征和表示方式,从而增强了模型对噪声和异常值的抗干扰能力。这种特性使得MoE在处理实际应用中的复杂数据时表现出更高的稳定性和可靠性。
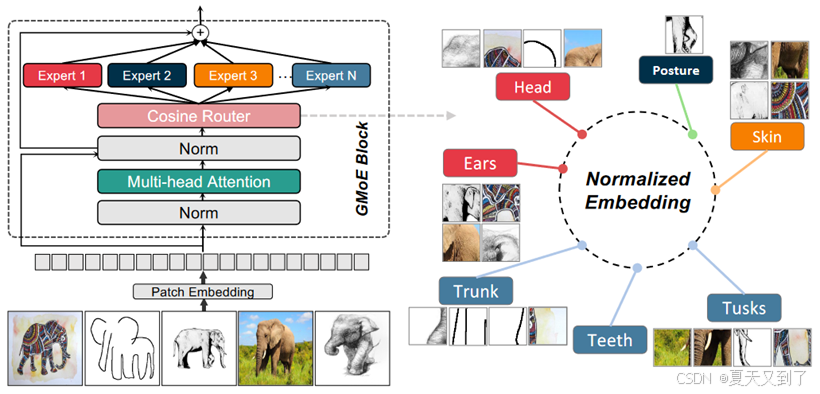
图5-13 针对不同部位判定的MoE层
5.3.1 注意力机制中的前馈层不足
在前面探讨注意力机制的章节中,我们曾提及,在注意力层之后,通常会紧接一个标准的前馈神经网络(FFNN)。这个前馈神经网络在模型中的作用举足轻重,它使模型能够充分利用注意力机制所生成的上下文信息,并将这些信息进一步转化和提炼,从而捕捉到数据中更为复杂和深层次的关系。如图5-14所示。
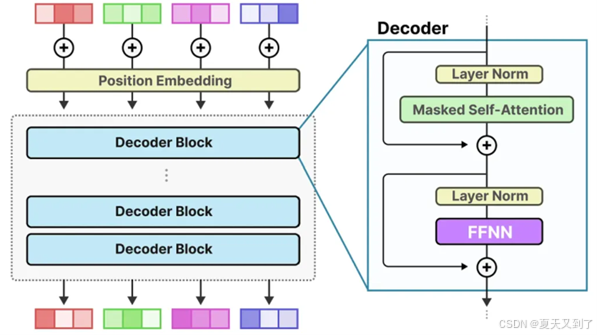
图5-14 注意力层之后接上FFNN
然而,随着模型对数据处理需求的提升,FFNN的规模也呈现出迅速增长的趋势。为了有效地学习并表达这些复杂的数据关系,FFNN通常需要对接收到的输入进行显著的维度扩展。这意味着,在实践中,我们需要运用一个庞大的全连接层(Fully Connected Layer,FCL)来完成这一关键任务。
具体来看,传统的前馈层是由一系列串联的全连接层所构成,这些层级结构通过调整内部神经元的数量,来实现对输入信息的逐层抽象与处理。传统的前馈层如图5-15所示。[yx1] [晓王2]
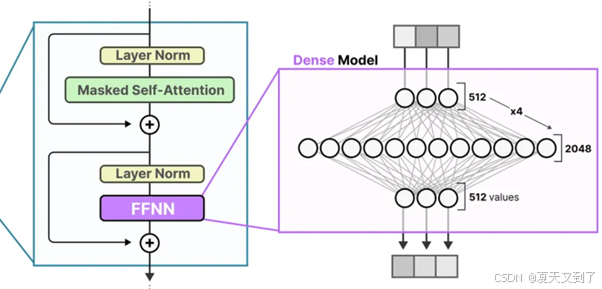
图5-15 传统的前馈层
这种设计虽然在一定程度上提升了模型的表达能力,但同时也带来了计算资源和存储空间的挑战。因此,在构建和应用这类模型时,我们需要精心权衡其性能与资源消耗之间的平衡。
在传统的注意力模型中,FFNN 被称为密集模型(Dense Model),因为它的所有参数(包括权重和偏置项)都会被激活。所有参数都被用于计算输出,没有任何部分被遗弃。如果我们仔细观察密集模型,可以发现输入在某种程度上激活了所有参数。密集模型如图5-16所示。
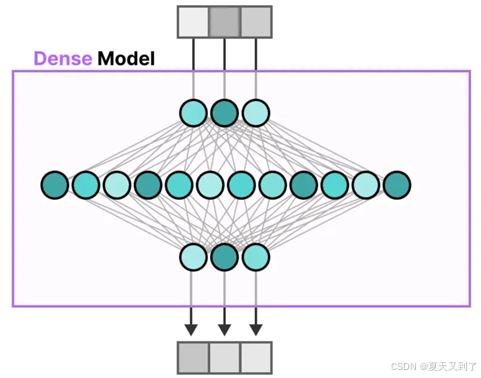
图5-16 密集模型
相比之下,稀疏模型(Sparse Model)在运行时仅激活其总参数集中的一小部分,这种特性使其与专家混合模型紧密相连。为了更直观地阐述这一点,我们可以设想将一个密集模型(即传统意义上的全连接模型)分解为多个独立的部分,这些部分在MoE的框架中被称作“专家”。每个专家都负责处理特定类型的数据或特征,并在训练过程中专注于学习其专长领域内的知识。稀疏模型如图5-17所示。
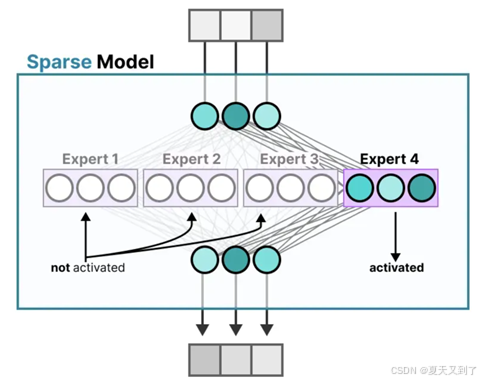
图5-17 稀疏模型
稀疏性的概念采用了条件计算的思想。在传统的稠密模型中,所有的参数都会对所有输入数据进行处理。相比之下,稀疏性允许我们仅针对整个系统的某些特定部分执行计算。这意味着并非所有参数都会在处理每个输入时被激活或使用,而是根据输入的特定特征或需求,只有部分参数集合被调用和运行。
在模型运行时,我们不再像密集模型那样同时激活所有参数,而是根据输入数据的特性动态地选择并激活一部分专家。这种机制使得MoE能够在不同情境下调用最合适的专家组合,从而更精确地捕捉数据的复杂性和多样性。同时,由于每次只激活部分专家,MoE在计算效率和资源消耗方面相较于密集模型具有显著优势。这种可选择的稀疏专家模型如图5-18所示。
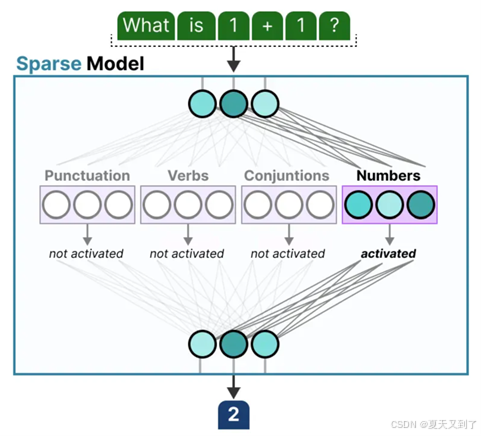
图5-18 可选择的稀疏专家模型
下面两个示意图(图5-19、图5-20),根据颜色的深浅可以看到,对于输入的文本内容,其中的每个词汇或者字母(根据token划分)都被不同的专家所关注。

图5-19 不同专家所关注的部分
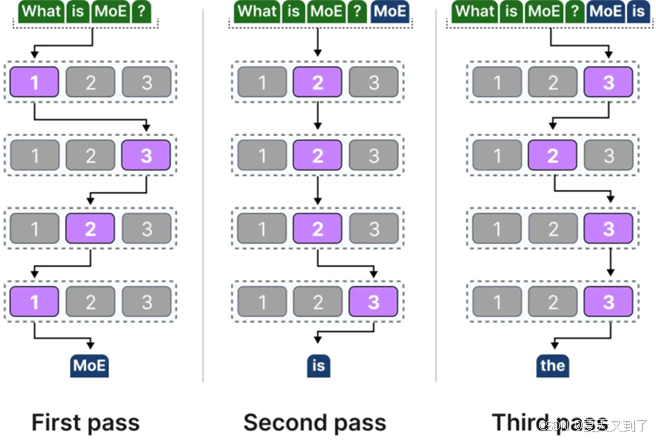
图5-20 每个注意力中的专家
这种灵活性使得混合专家模型能够更精细地捕捉和响应数据中的复杂模式,从而提升了模型的整体性能和泛化能力。同时,由于每个专家都专注于其特定领域的知识表示,这种结构也有助于实现模型内部的知识分工和模块化,进一步提高了模型的解释性和可维护性。
5.3.2 MoE天然可作为前馈层FFNN
在前面的工作中,我们已经成功设计并实现了混合专家模型(MoE)的程序代码,更进一步地,我们利用这个独立且完整的MoE模型完成了情感分类的实战演练。通过实战结果,我们清晰地观察到,MoE模型本身便具备出色的特征抽取能力,可以作为一个高效的特征抽取层来使用。在情感分类任务中,MoE模型展现出了良好的性能,准确地完成了分类任务。
传统的注意力机制中的前馈层,在很大程度上,其核心功能和作用可由特定的混合专家模型(MoE)来有效替代。可替代注意力模型中前馈层的MoE如图5-21所示。
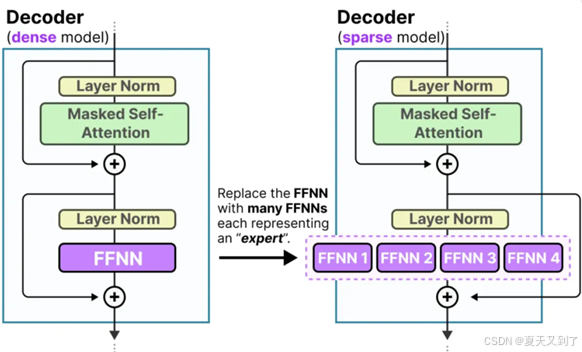
图5-21 可替代注意力模型中前馈层的MoE
在上一节中,我们已经对MoE模型做了详细的阐述,尽管可以将专家模型理解为被分解的密集模型的隐藏层,但事实上这些专家模型本身往往就是功能完备的前馈神经网络(FFNN)。可作为FFNN的完整MoE模型如图5-22所示,使用专家模型作为前馈层如图5-23所示。
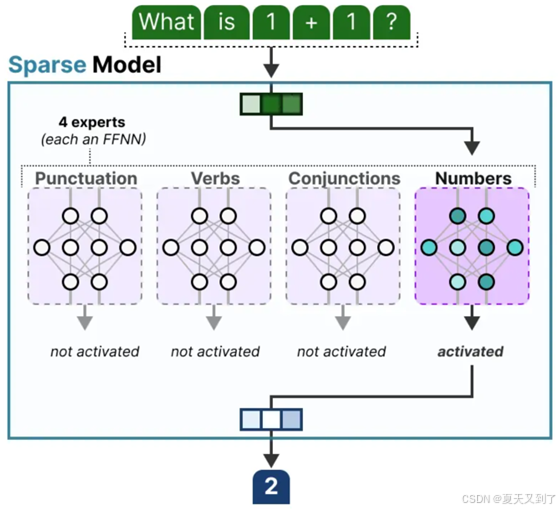
图5-22 可作为FFNN的完整MoE模型
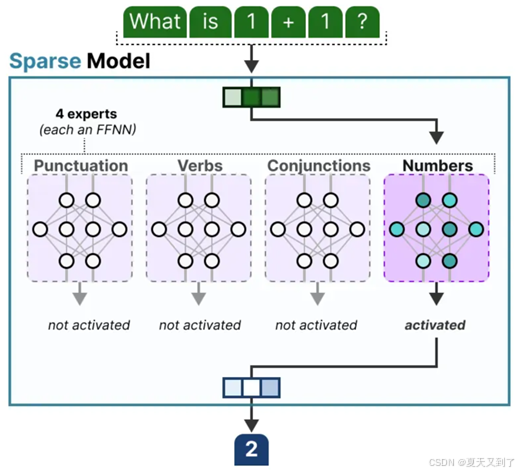
图5-23 使用专家模型作为前馈层
而一般注意力模型在使用过程中,由于存在多个模块的叠加,给定的文本在生成之前会依次通过这些不同模块中的多个专家。不同的token在传递过程中可能会被不同的专家所处理,这导致了在模型内部形成了多样化的处理“路径”。叠加注意力模块中的专家路径示意如图5-24所示。
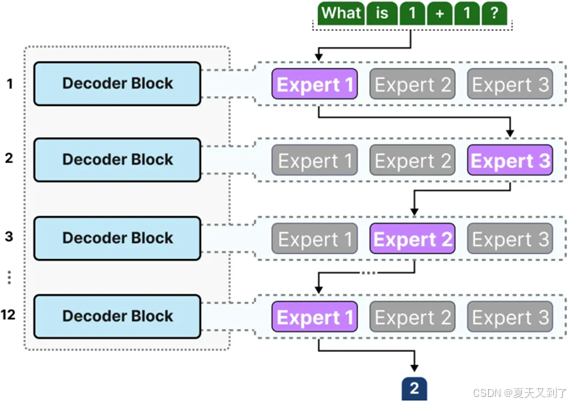
图5-24 叠加注意力模块中的专家路径
如果我们更新对解码器块的视觉呈现,现在它将展现出一个包含多个FFNN(前馈神经网络)的架构,其中每个FFNN都代表一个特定的“专家”。这种设计意味着,在推理阶段,解码器块内拥有多个可供选择的FFNN专家,模型能够根据输入数据的特性动态地选择合适的专家来处理信息。
而不同的专家在混合专家模型(MoE)中选择关注的token各不相同,这种差异性使得随着输入文本的变化,模型会动态地选择不同的“路径”进行处理。换言之,每个专家都专注于捕获输入数据的特定特征或模式,从而根据输入内容的不同,整体模型的关注路径也会相应地调整。如图5-25所示。
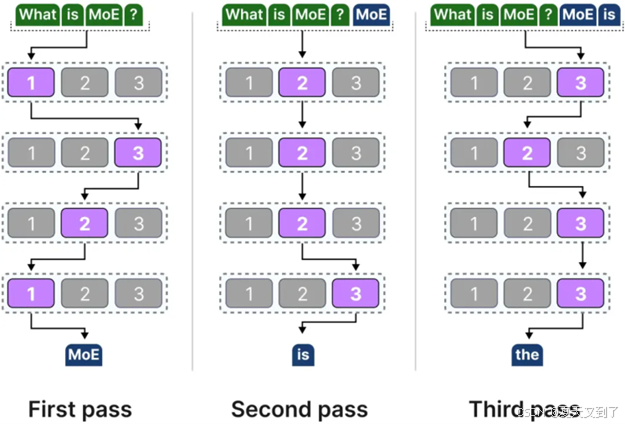
图5-25 输入路径不同选择的专家不同
我们可以观察到,这种随着输入内容变化而变化的关注路径,实际上为模型提供了一种灵活且动态的特征选择机制。这种机制使得模型能够在处理不同输入时,更加精准地聚焦于关键信息,从而提升了模型的泛化能力和处理复杂任务的能力。
更重要的是,这种动态选择关注点的特性,正是我们所期望的。它意味着模型可以根据具体任务需求和输入数据的特性,自适应地调整其关注重点,以实现更加高效和准确的特征抽取和分类。这种灵活性不仅增强了模型的实用性,也为深度学习领域的发展注入了新的活力。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









