




本节将通过一个实战案例来详细介绍如何使用PyTorch进行深度学习模型的开发。我们将使用CIFAR-10图像数据集来训练一个卷积神经网络。
神经网络训练的一般步骤如图5-3所示。
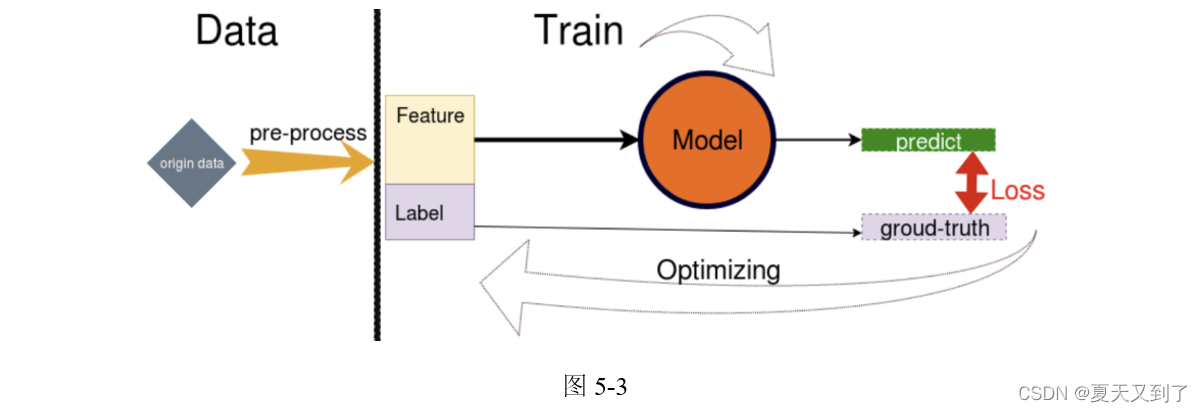
(1)加载数据集,并做预处理。
(2)预处理后的数据分为Feature和Label两部分,Feature 送到模型里面,Label被当作ground-truth。
(3)Model接收Feature作为Input,并通过一系列运算,向外输出 predict。
(4)建立一个损失函数 Loss,Loss 的函数值是为了表示 predict 与 ground-truth 之间的差距。
(5)建立 Optimizer 优化器,优化的目标就是 Loss 函数,让它的取值尽可能最小,Loss越小代表 Model 预测的准确率越高。
(6)Optimizer 优化过程中,Model 根据规则改变自身参数的权重,这是一个反复循环和持续的过程,直到Loss值趋于稳定,不能再取得更小的值。
数据集的加载可以自行编写代码,但如果是基于学习目的的话,那么把精力放在编写这个步骤的代码上面会让人十分无聊,好在PyTorch 提供了非常方便的包torchvision。torchvison提供了dataloader来加载常见的MNIST、CIFAR-10、ImageNet 等数据集,也提供了transform对图像进行变换、正则化和可视化。
在本项目中,我们的目的是用 PyTorch 创建基于 CIFAR-10 数据集的图像分类器。CIFAR-10图像数据集共有60 000幅彩色图像,这些图像是32×32的,分为10个类,分别是airplane、automobile、bird、cat等,每类6 000幅图,如图5-4所示。这里面有50 000幅训练图像,10 000幅测试图像。

首先,加载数据并进行预处理。我们将使用torchvision包来下载CIFAR-10数据集,并使用transforms模块对数据进行预处理。主要用来进行数据增强,为了防止训练出现过拟合,通常在小型数据集上,通过随机翻转图片、随机调整图片的亮度来增加训练时数据集的容量。但是,测试的时候,并不需要对数据进行增强。运行代码后,会自动下载数据集。
接下来,定义卷积神经网络模型。在这个网络模型中,我们使用nn.Module来定义网络模型,然后在__init__方法中定义网络的层,最后在forward方法中定义网络的前向传播过程。在PyTorch中可以通过继承nn.Module来自定义神经网络,在init()中设定结构,在forward()中设定前向传播的流程。因为PyTorch可以自动计算梯度,所以不需要特别定义反向传播。
定义好神经网络模型后,还需要定义损失函数(Loss)和优化器(Optimizer)。在这里采用 cross-entropy-loss函数作为损失函数,采用 Adam 作为优化器,当然SGD也可以。
一切准备就绪后,开始训练网络,这里训练10次(可以增加训练次数,提高准确率)。在训练过程中,首先通过网络进行前向传播得到输出,然后计算输出与真实标签的损失,接着通过后向传播计算梯度,最后使用优化器更新模型参数。训练完成后,我们需要在测试集上测试网络的性能。这可以让我们了解模型在未见过的数据上的表现如何,以评估其泛化能力。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5615
5615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









