



论文名称:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
MobileNets是一种高效卷积神经网络,它采用深度可分离卷积来构建轻量级深度神经网络,可用于移动和嵌入式视觉应用,文章还介绍了两个简单的全局超参数(宽度超参数和分辨率超参数),可以有效地在延迟和准确性之间进行权衡。
深度可分离卷积
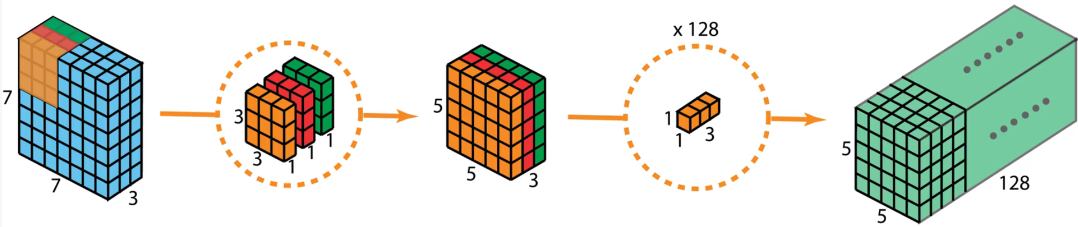
深度可分离卷积将一般的卷积操作分成了两个主要部分:深度卷积(depthwise convolution)和逐点卷积(pointwise convolution),相当于是将输入的长宽方向和通道方向的信息解耦了,模型的结构是先进行深度卷积,对每个通道采用独立的卷积进行处理,这里的卷积不再是像一般的卷积,拥有和输入一样的通道数,深度卷积的每个卷积核都只有一层,并且分别单独处理对应的输入通道,也就是说,如果是RGB三个通道,那么就会对应有三个二维的卷积核对其进行处理,得到相同通道数,但长宽方向会有变化的feature map,上图的左半部分可以看出,在经过了深度卷积后,feature map会再通过逐点卷积进行通道之间的混合,从而得到最终的输出,这里的逐点卷积核都是1*1的卷积,通道数和feature map的通道数相同,这可以保证前后的长宽相同,然后有几个逐点卷积核则输出有多少通道数,如上图右半部分所示。
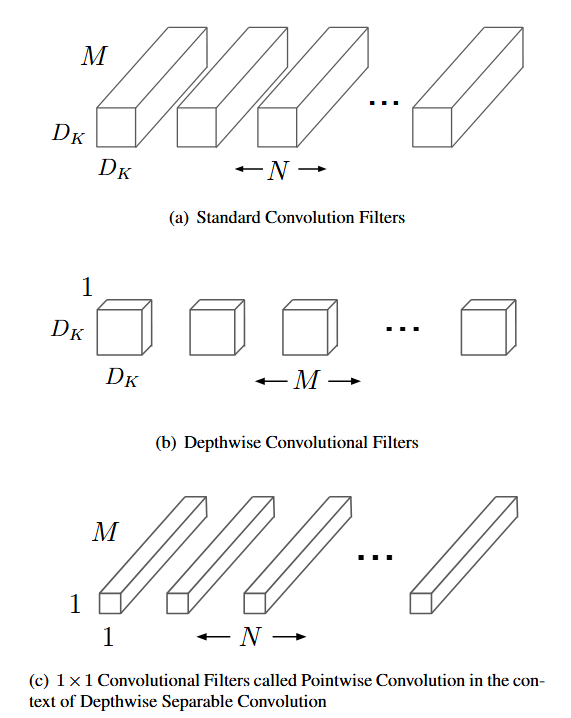
这是原文中的图片,M表示输入的通道数,N表示feature map的通道数,Dk*Dk为深度卷积的大小。

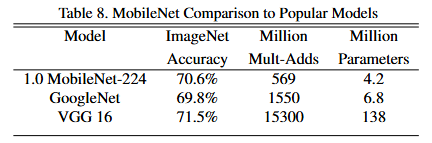
这从论文给出的实验结果也可以看出,MobileNet确实在参数量和计算量的缩减非常显著,并且在ImageNet数据集上的准确率具有很强的竞争力。
此外,论文还加入了两个超参数——宽度超参数和分辨率超参数,宽度超参数的作用是均匀地缩减模型中每一层地通道数,分辨率超参数的作用是缩减图像和模型内部表示的分辨率,也就是大小,将宽度超参数和分辨率超参数的有效结合,可以更加灵活的设计MobileNets,在计算量和准确率之间寻找一个适合自己的模型。
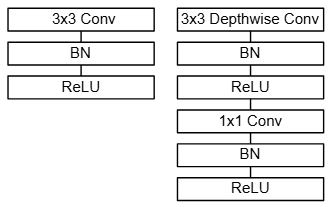
这张图左边是标准卷积,右边便是用来代替标准卷积的深度可分离卷积。
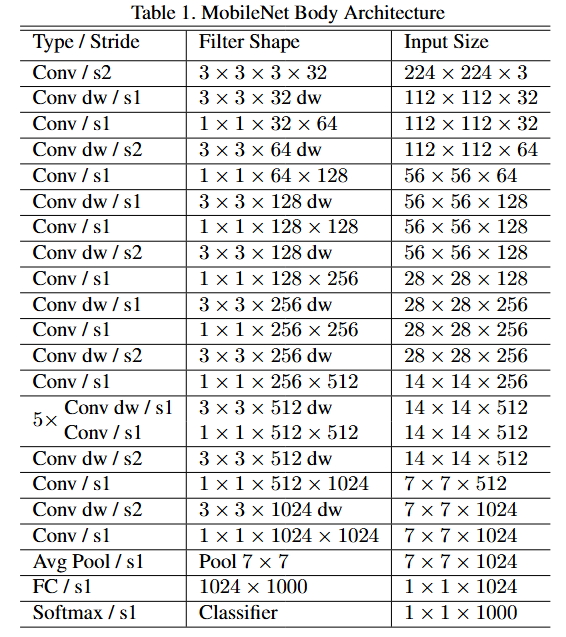
这是MobileNet的网络结构,出了第一层是一个标准卷积 ,其他都是一个深度卷积加上一个逐点卷积的组合,s1表示步长为1,s2表示步长为2,表示进行一次下采样,用以替换池化层,这是因为池化操作虽然在计算上比较高效,但是会丢失一些空间信息,而使用步长为2的下采样操作,网络能够学习到更丰富的特征信息,也可以保留参数的共享特性,使得模型更加紧凑,这种设计方法已经被广泛的应用于其他的网络架构中,证明了卷积层作为下采样方法的有效性和灵活性。
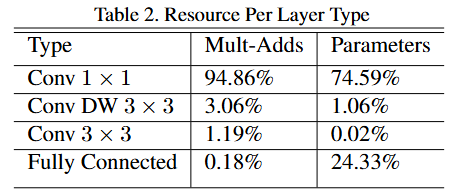
这张图展现了,1*1的卷积层占据了大约95%的运算量和75%的参数量,模型结构几乎将所有计算都集中在密集的1*1卷积中,这可以通过高度优化的通用矩阵乘法(GEMM)函数来实现,但通常卷积要通过GEMM实现,需要在内存中进行初步重排,这被称为im2col,将卷积运算转换为矩阵乘法运算,但1*1卷积不需要在内存中进行重排,可以直接通过GEMM实现,所以这更加符合我们需要快速运算的目标。
最后我使用自己的数据集对ViT和MobileNet进行对比实验(这里选用ViT是因为复现师兄的论文,使用的是ViT),使用的硬件平台是华为云AI平台,设备型号为Tesla V100-PCIE-32GB,batch_size设定为256,学习率设为0.00005,在每一帧的处理上,ViT需要花费0.00944s,而MobileNet每一帧只需要0.00879s,两者的最优准确率只相差1%,下面第一张图是ViT的最终分类报告,第二张图是MobileNet的最终分类报告。
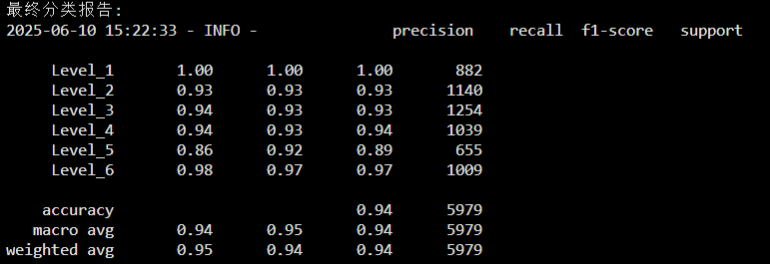
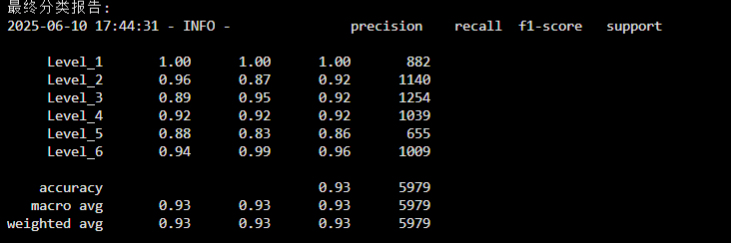
并且保存的两个模型的最优权重大小也相差巨大,这里做一个展示。第一张图是ViT的最优模型权重文件,第二张图是MobileNet的最优模型权重。
![]()
![]()

















 3414
3414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









