



前言
以下是一个对PyTorch特征识别的的通用神经网络模型,用于将代码的文本特征识别结果转换为-拓扑图的框架。该模型经过大量规则特征标注,已经能识别主流通用神经网络及其变体。
模型有助于程序到论文上的绘图,以及帮助初学者对同特征结构网络的泛化学习
目前可以推演的神经网络有20年代之前几乎所有的神经网络,不能推演的为近几年部分具有循环结构/多路复用/嵌合/有环路网络以及已被torch集成的神经网络如RNN、LSTM、GAN
模型效果图
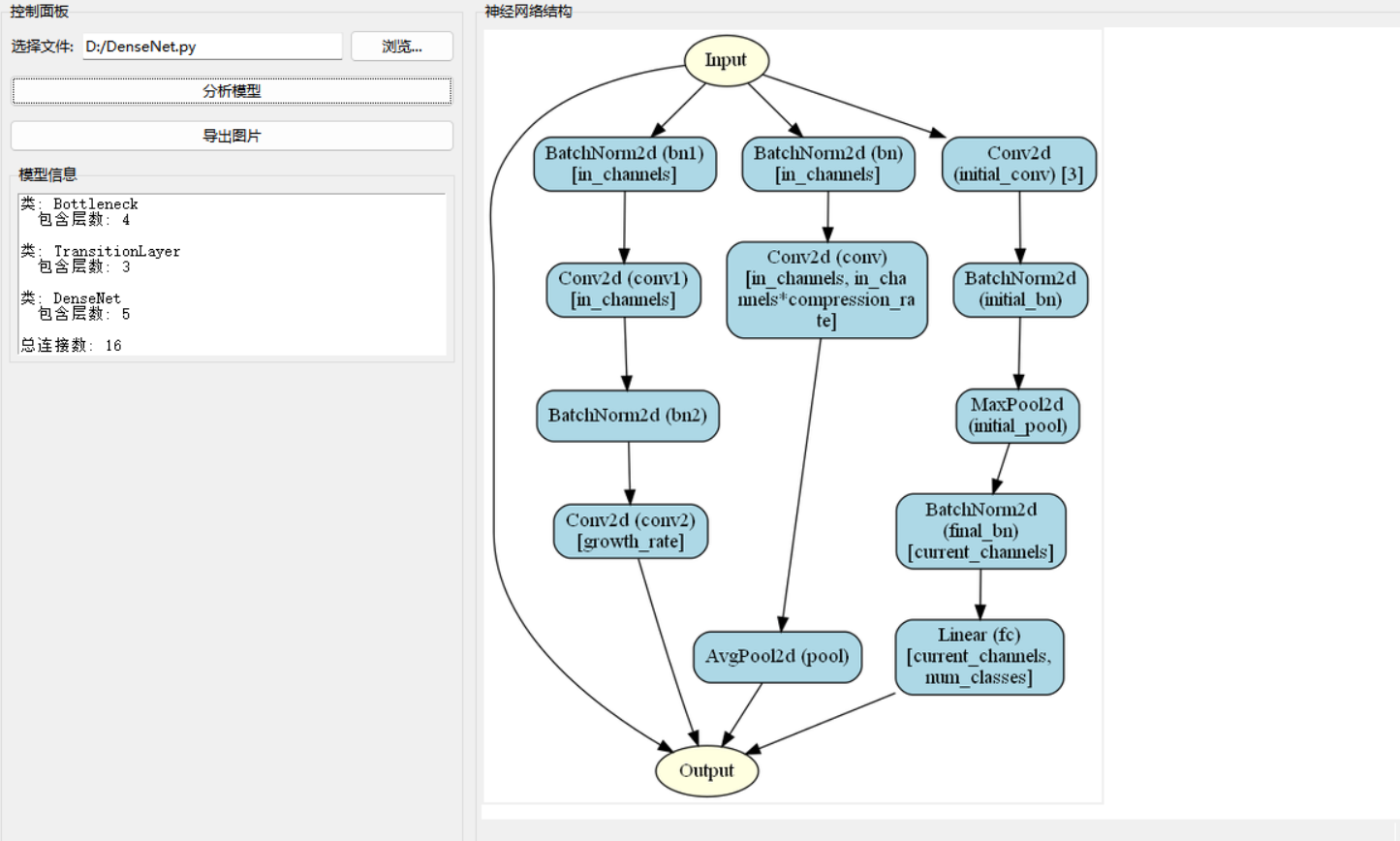
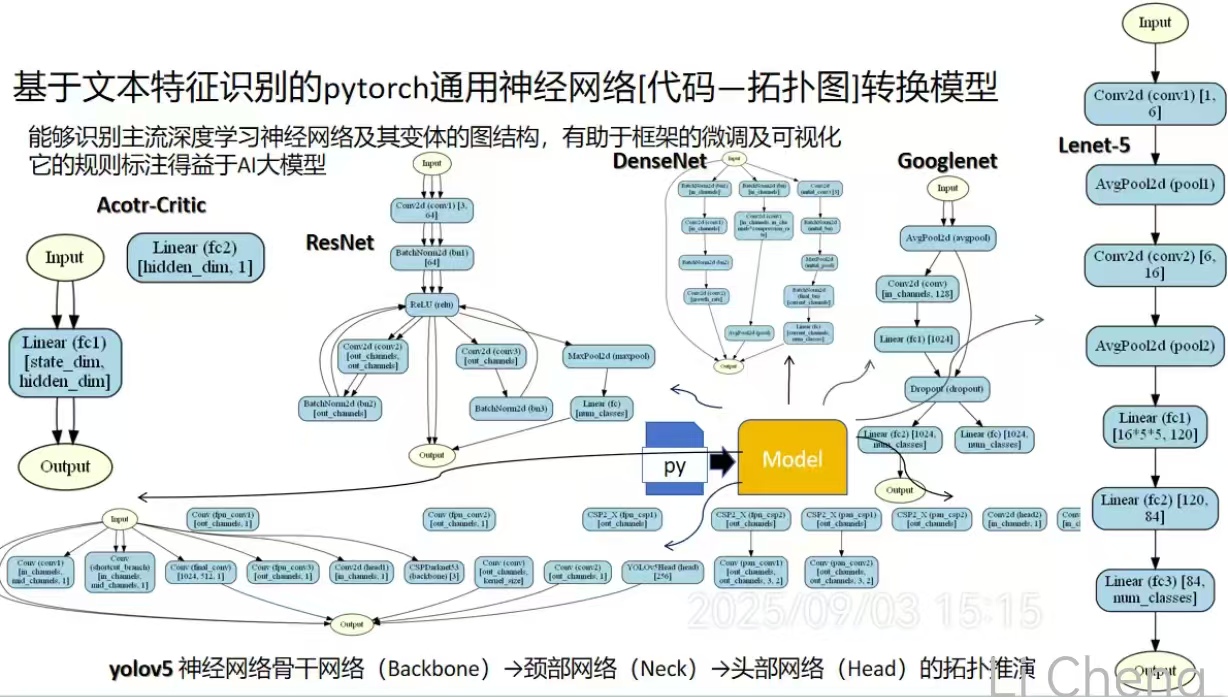
模型架构设计
文本编码器模块设计思路
import torch
import torch.nn as nn
from transformers import BertModel
class TextEncoder(nn.Module):
def __init__(self, pretrained_model='bert-base-uncased'):
super().__init__()
self.bert = BertModel.from_pretrained(pretrained_model)
self.proj = nn.Linear(768, 256) # 降维层
def forward(self, input_ids, attention_mask):
outputs = self.bert(input_ids, attention_mask=attention_mask)
pooled_output = outputs.last_hidden_state[:, 0, :]
return self.proj(pooled_output)
图解码器模块设计思路
import torch_geometric.nn as geom_nn
class GraphDecoder(nn.Module):
def __init__(self, node_dim=256, edge_dim=128):
super().__init__()
self.node_mlp = nn.Sequential(
nn.Linear(node_dim, 512),
nn.ReLU(),
nn.Linear(512, 256)
)
self.edge_net = geom_nn.GATConv(
in_channels=node_dim,
out_channels=edge_dim,
heads=3
)
def forward(self, text_embeddings, edge_index):
node_features = self.node_mlp(text_embeddings)
edge_features = self.edge_net(node_features, edge_index)
return node_features, edge_features
模型集成设计思路
class CodeGraphModel(nn.Module):
def __init__(self):
super().__init__()
self.encoder = TextEncoder()
self.decoder = GraphDecoder()
# 拓扑预测头
self.topology_head = nn.Linear(256, 4) # 预测节点类型
def forward(self, text_inputs, edge_index):
text_emb = self.encoder(
input_ids=text_inputs['input_ids'],
attention_mask=text_inputs['attention_mask']
)
nodes, edges = self.decoder(text_emb, edge_index)
topology_logits = self.topology_head(nodes)
return {
'node_embeddings': nodes,
'edge_embeddings': edges,
'topology_logits': topology_logits
}
数据处理示例
from torch_geometric.data import Data
def create_graph_data(text_embeddings, adj_matrix):
edge_index = torch.tensor(adj_matrix.nonzero(), dtype=torch.long)
return Data(x=text_embeddings, edge_index=edge_index)
训练逻辑框架
def train_step(model, batch, optimizer):
model.train()
optimizer.zero_grad()
# 假设batch包含文本输入和邻接矩阵
graph_data = create_graph_data(batch['text_emb'], batch['adj'])
outputs = model(batch['text_inputs'], graph_data.edge_index)
loss = compute_loss(outputs, batch['targets'])
loss.backward()
optimizer.step()
return loss.item()
def compute_loss(outputs, targets):
node_loss = nn.CrossEntropyLoss()(
outputs['topology_logits'],
targets['node_types']
)
edge_loss = nn.BCEWithLogitsLoss()(
outputs['edge_embeddings'],
targets['edge_exists']
)
return node_loss + 0.5 * edge_loss
拓扑图可视化方法
import networkx as nx
import matplotlib.pyplot as plt
def visualize_graph(node_features, edge_index):
G = nx.Graph()
for i, feat in enumerate(node_features):
G.add_node(i, features=feat.detach().numpy())
for src, dst in edge_index.t().tolist():
G.add_edge(src, dst)
pos = nx.spring_layout(G)
nx.draw(G, pos, with_labels=True)
plt.show()
关键实现要点
文本特征提取
- 使用预训练BERT模型获取上下文感知的文本嵌入
- 通过投影层将高维特征压缩到适合图网络的维度
图结构生成
- 动态边预测采用GAT(图注意力网络)机制
- 节点类型分类使用简单的MLP头部
扩展性设计
- 支持自定义的节点和边特征维度
- 可替换不同的文本编码器(如RoBERTa、GPT等)
- 图解码器兼容PyGeometric的各种GNN层
完整代码如下:
import ast
import os
import tkinter as tk
from tkinter import filedialog, messagebox, ttk
import subprocess
import re
import graphviz
from PIL import Image, ImageTk
import textwrap
import hashlib
class PyTorchModelAnalyzer:
def __init__(self):
self.layers = {}
self.connections = []
self.current_class = None
self.import_aliases = {}
self.container_instances = {} # 跟踪容器实例
self.cross_class_connections = [] # 跨类连接
self.forward_calls = [] # 记录前向传播中的函数调用
self.var_mapping = {} # 变量映射表
def analyze_file(self, file_path):
"""分析PyTorch文件并提取网络结构"""
self.layers = {}
self.connections = []
self.current_class = None
self.import_aliases = {}
self.container_instances = {} # 跟踪容器实例
self.cross_class_connections = [] # 跨类连接
self.forward_calls = [] # 记录前向传播中的函数调用
self.var_mapping = {} # 变量映射表
try:
# 使用二进制模式读取文件
with open(file_path, 'rb') as file:
raw_data = file.read()
# 尝试不同编码
for encoding in ['utf-8', 'latin-1', 'gbk', 'cp1252']:
try:
code = raw_data.decode(encoding)
break
except UnicodeDecodeError:
continue
else:
# 所有编码都失败,使用错误替代策略
code = raw_data.decode('utf-8', errors='replace')
tree = ast.parse(code)
# 遍历AST树
for node in ast.walk(tree):
if isinstance(node, ast.Import):
# 记录导入别名
for alias in node.names:
self.import_aliases[alias.asname or alias.name] = alias.name
elif isinstance(node, ast.ClassDef):
# 检查类是否继承自nn.Module
if self.is_nn_module_class(node):
self.current_class = node.name
self.analyze_class(node)
self.current_class = None
# 分析跨类连接
self.analyze_cross_class_connections()
return True, "分析成功"
except Exception as e:
return False, f"分析错误: {str(e)}"
def is_nn_module_class(self, class_node):
"""检查类是否继承自nn.Module"""
for base in class_node.bases:
if isinstance(base, ast.Attribute):
if base.attr == 'Module' and (isinstance(base.value, ast.Name) and base.value.id in self.import_aliases):
return True
elif isinstance(base, ast.Name):
if base.id == 'Module':
return True
elif isinstance(base, ast.Call):
# 处理如 class Model(nn.Module): 的情况
if isinstance(base.func, ast.Name) and base.func.id == 'nn.Module':
return True
return False
def analyze_class(self, class_node):
"""分析类定义"""
# 首先收集所有层定义
self.collect_layers(class_node)
# 然后分析forward方法
self.analyze_forward_method(class_node)
def collect_layers(self, class_node):
"""收集__init__方法中定义的所有层"""
for item in class_node.body:
if isinstance(item, ast.FunctionDef) and item.name == '__init__':
for stmt in item.body:
self.process_init_statement(stmt)
def process_init_statement(self, stmt):
"""处理__init__中的语句"""
if isinstance(stmt, ast.Assign):
for target in stmt.targets:
if isinstance(target, ast.Attribute) and isinstance(target.value, ast.Name) and target.value.id == 'self':
layer_name = target.attr
# 处理直接层定义
if isinstance(stmt.value, ast.Call):
layer_type = self.get_layer_type(stmt.value.func)
if layer_type:
dims = self.extract_dimensions(stmt.value)
self.layers[layer_name] = {
'type': layer_type,
'dims': dims,
'class': self.current_class
}
# 处理容器类型 (ModuleList, ModuleDict)
elif isinstance(stmt.value, ast.Call) and self.is_container_type(stmt.value.func):
container_type = self.get_container_type(stmt.value.func)
container_layers = self.extract_container_layers(stmt.value, container_type)
# 为容器中的每个层创建唯一标识符
for idx, (layer_type, layer_dims) in enumerate(container_layers):
unique_id = f"{layer_name}_{idx}"
self.layers[unique_id] = {
'type': layer_type,
'dims': layer_dims,
'class': self.current_class,
'container': layer_name,
'index': idx
}
# 记录容器实例
self.container_instances[layer_name] = {
'type': container_type,
'layers': [f"{layer_name}_{i}" for i in range(len(container_layers))],
'class': self.current_class
}
def is_container_type(self, func_node):
"""检查是否是容器类型(ModuleList, ModuleDict)"""
if isinstance(func_node, ast.Attribute):
if func_node.attr in ['ModuleList', 'ModuleDict', 'Sequential']:
return True
return False
def get_container_type(self, func_node):
"""获取容器类型"""
if isinstance(func_node, ast.Attribute):
return func_node.attr
return "Container"
def extract_container_layers(self, call_node, container_type):
"""从容器调用中提取层信息"""
layers = []
# 处理ModuleList: [layer1, layer2, ...]
if container_type == 'ModuleList':
for element in call_node.args:
if isinstance(element, ast.Call):
layer_type = self.get_layer_type(element.func)
if layer_type:
dims = self.extract_dimensions(element)
layers.append((layer_type, dims))
# 处理Sequential: nn.Sequential(layer1, layer2, ...)
elif container_type == 'Sequential':
for arg in call_node.args:
if isinstance(arg, ast.Call):
layer_type = self.get_layer_type(arg.func)
if layer_type:
dims = self.extract_dimensions(arg)
layers.append((layer_type, dims))
return layers
def get_layer_type(self, func_node):
"""获取层类型"""
if isinstance(func_node, ast.Attribute):
if func_node.attr in ['Linear', 'Conv2d', 'Conv1d', 'Conv3d',
'LSTM', 'GRU', 'Embedding', 'LayerNorm',
'BatchNorm1d', 'BatchNorm2d', 'BatchNorm3d',
'Dropout', 'ReLU', 'Sigmoid', 'Tanh',
'Softmax', 'LogSoftmax', 'MaxPool2d', 'AvgPool2d',
'TransformerEncoder', 'TransformerDecoder', 'TransformerEncoderLayer',
'TransformerDecoderLayer', 'MultiheadAttention', 'PolicyNet', 'ValueNet']:
return func_node.attr
elif isinstance(func_node, ast.Name):
return func_node.id
return None
def extract_dimensions(self, call_node):
"""从层调用中提取维度信息"""
dims = []
# 检查位置参数
for arg in call_node.args:
if isinstance(arg, ast.Constant) and isinstance(arg.value, int):
dims.append(str(arg.value))
elif isinstance(arg, ast.Name):
dims.append(arg.id)
elif isinstance(arg, ast.Call) and isinstance(arg.func, ast.Name) and arg.func.id == 'int':
# 处理如 int(d_model/num_heads) 的表达式
if len(arg.args) > 0 and isinstance(arg.args[0], ast.BinOp):
expr = self.extract_expression(arg.args[0])
dims.append(expr)
# 检查关键字参数
for kw in call_node.keywords:
if kw.arg in ['in_features', 'out_features', 'in_channels', 'out_channels',
'input_size', 'hidden_size', 'embedding_dim', 'num_embeddings',
'd_model', 'nhead', 'dim_feedforward', 'num_layers',
'state_dim', 'hidden_dim', 'action_dim']:
if isinstance(kw.value, ast.Constant) and isinstance(kw.value.value, int):
dims.append(str(kw.value.value))
elif isinstance(kw.value, ast.Name):
dims.append(kw.value.id)
elif isinstance(kw.value, ast.Call) and isinstance(kw.value.func, ast.Name) and kw.value.func.id == 'int':
# 处理如 int(d_model/num_heads) 的表达式
if len(kw.value.args) > 0 and isinstance(kw.value.args[0], ast.BinOp):
expr = self.extract_expression(kw.value.args[0])
dims.append(expr)
elif isinstance(kw.value, ast.BinOp):
# 处理数学表达式
expr = self.extract_expression(kw.value)
dims.append(expr)
return dims
def extract_expression(self, node):
"""提取数学表达式"""
if isinstance(node, ast.BinOp):
left = self.extract_expression(node.left)
right = self.extract_expression(node.right)
op = self.get_operator(node.op)
return f"{left}{op}{right}"
elif isinstance(node, ast.Name):
return node.id
elif isinstance(node, ast.Constant):
return str(node.value)
return ""
def get_operator(self, op_node):
"""获取运算符表示"""
if isinstance(op_node, ast.Add):
return "+"
elif isinstance(op_node, ast.Sub):
return "-"
elif isinstance(op_node, ast.Mult):
return "*"
elif isinstance(op_node, ast.Div):
return "/"
return ""
def analyze_forward_method(self, class_node):
"""分析forward方法中的层连接关系"""
self.var_mapping = {} # 初始化变量映射表
for item in class_node.body:
if isinstance(item, ast.FunctionDef) and item.name == 'forward':
# 获取实际输入变量(跳过self)
input_var = None
if len(item.args.args) > 1:
input_var = item.args.args[1].arg
self.var_mapping[input_var] = 'input' # 映射输入节点
# 遍历forward方法体
for stmt in item.body:
self.traverse_statement(stmt, input_var, class_node.name)
def traverse_statement(self, stmt, input_var, class_name):
"""遍历语句,寻找层调用"""
if isinstance(stmt, ast.Assign):
# 处理多个目标变量
for target in stmt.targets:
if isinstance(target, ast.Name):
target_var = target.id
# 处理层调用 (self.conv1(x))
if isinstance(stmt.value, ast.Call):
source, result = self.process_call(stmt.value, class_name)
if result:
# 记录连接关系
if source:
self.connections.append((source, result))
# 更新变量映射
self.var_mapping[target_var] = result
# 处理嵌套调用(如F.relu(self.fc1(x)))
elif isinstance(stmt.value, ast.Attribute) or isinstance(stmt.value, ast.Name):
# 递归处理嵌套表达式
source, result = self.process_expression(stmt.value, class_name)
if result:
self.var_mapping[target_var] = result
# 处理容器调用 (self.encoder_layers(x))
elif (isinstance(stmt.value, ast.Call) and
isinstance(stmt.value.func, ast.Attribute) and
stmt.value.func.attr in self.container_instances):
container_name = stmt.value.func.attr
source = self.get_input_source(stmt.value.args[0])
# 连接容器中的所有层
container = self.container_instances[container_name]
layers = container['layers']
# 输入到第一个层
if layers and source:
self.connections.append((source, layers[0]))
# 层与层之间连接
for i in range(len(layers) - 1):
self.connections.append((layers[i], layers[i+1]))
# 更新变量映射
self.var_mapping[target_var] = layers[-1]
# 处理for循环(用于容器中的层)
elif isinstance(stmt, ast.For):
self.process_loop(stmt, class_name)
# 处理返回语句
elif isinstance(stmt, ast.Return):
source = self.get_input_source(stmt.value)
if source:
self.connections.append((source, 'output'))
def process_expression(self, expr, class_name):
"""递归处理嵌套表达式"""
# 处理属性访问(如self.fc1)
if isinstance(expr, ast.Attribute) and isinstance(expr.value, ast.Name) and expr.value.id == 'self':
if expr.attr in self.layers:
return None, expr.attr
# 处理变量名
elif isinstance(expr, ast.Name):
return None, self.var_mapping.get(expr.id, None)
# 处理调用表达式
elif isinstance(expr, ast.Call):
return self.process_call(expr, class_name)
return None, None
def process_call(self, call_node, class_name):
"""处理函数调用"""
# 处理层调用:self.xxx(...)
if (isinstance(call_node.func, ast.Attribute) and
isinstance(call_node.func.value, ast.Name) and
call_node.func.value.id == 'self'):
layer_name = call_node.func.attr
if layer_name in self.layers:
# 获取输入源
source = self.get_input_source(call_node.args[0])
return source, layer_name
# 处理嵌套调用(如F.relu(self.fc1(x)))
elif call_node.args and isinstance(call_node.args[0], ast.Call):
# 递归处理内部调用
inner_source, inner_result = self.process_call(call_node.args[0], class_name)
return inner_source, layer_name
# 处理激活函数调用(如F.relu(...))
elif (isinstance(call_node.func, ast.Attribute) and
isinstance(call_node.func.value, ast.Name) and
call_node.func.value.id in ['F', 'torch', 'nn', 'nn.functional']):
# 递归处理参数中的层调用
if call_node.args:
for arg in call_node.args:
if isinstance(arg, ast.Call):
return self.process_call(arg, class_name)
elif isinstance(arg, ast.Attribute) or isinstance(arg, ast.Name):
_, result = self.process_expression(arg, class_name)
if result:
return None, result
# 处理容器中的层调用
elif (isinstance(call_node.func, ast.Subscript) and
isinstance(call_node.func.value, ast.Attribute) and
isinstance(call_node.func.value.value, ast.Name) and
call_node.func.value.value.id == 'self'):
container_name = call_node.func.value.attr
if (isinstance(call_node.func.slice, ast.Index) and
isinstance(call_node.func.slice.value, ast.Constant)):
index = call_node.func.slice.value.value
layer_id = f"{container_name}_{index}"
if layer_id in self.layers:
source = self.get_input_source(call_node.args[0])
return source, layer_id
# 处理其他类实例的调用 (如self.critic(x))
elif isinstance(call_node.func, ast.Attribute) and isinstance(call_node.func.value, ast.Attribute):
if (call_node.func.value.attr in self.layers and
self.layers[call_node.func.value.attr]['type'] in ['PolicyNet', 'ValueNet', 'Transformer']):
# 记录跨类调用
source = self.get_input_source(call_node.args[0])
self.forward_calls.append({
'caller': call_node.func.value.attr,
'callee': call_node.func.attr,
'source': source
})
return source, f"{call_node.func.value.attr}.{call_node.func.attr}"
# 处理嵌套表达式
if call_node.args:
for arg in call_node.args:
if isinstance(arg, (ast.Call, ast.Attribute, ast.Name)):
_, result = self.process_expression(arg, class_name)
if result:
return None, result
return None, None
def process_loop(self, loop_node, class_name):
"""处理循环结构(如for循环中的层)"""
if isinstance(loop_node.iter, ast.Attribute) and loop_node.iter.attr in self.container_instances:
container_name = loop_node.iter.attr
container = self.container_instances[container_name]
layers = container['layers']
# 查找循环体中的调用
for stmt in loop_node.body:
if isinstance(stmt, ast.Assign) and isinstance(stmt.value, ast.Call):
if (isinstance(stmt.value.func, ast.Attribute) and
isinstance(stmt.value.func.value, ast.Name) and
stmt.value.func.value.id == 'layer'): # 假设循环变量名为'layer'
# 获取输入源(可能是上一个层的输出)
source = self.get_input_source(stmt.value.args[0])
# 为容器中的每个层创建连接
for i in range(len(layers)):
layer_id = layers[i]
# 如果是第一个层,连接到输入
if i == 0 and source:
self.connections.append((source, layer_id))
# 层与层之间连接
if i > 0:
prev_layer = layers[i-1]
self.connections.append((prev_layer, layer_id))
def get_input_source(self, node):
"""解析输入源节点"""
if isinstance(node, ast.Name):
return self.var_mapping.get(node.id, None)
elif (isinstance(node, ast.Attribute) and
isinstance(node.value, ast.Name) and
node.value.id == 'self'):
return node.attr # 直接返回层名
elif isinstance(node, ast.Call):
# 递归处理嵌套调用
source, result = self.process_call(node, self.current_class)
return result if source is None else source
return None
def analyze_cross_class_connections(self):
"""分析跨类连接关系"""
for call in self.forward_calls:
caller_layer = call['caller']
callee_layer = call['callee']
source = call['source']
# 创建跨类连接
if source:
self.cross_class_connections.append((source, f"{caller_layer}.{callee_layer}"))
# 如果被调用的层是另一个网络,添加输入输出节点
if caller_layer in self.layers and self.layers[caller_layer]['type'] in ['PolicyNet', 'ValueNet', 'Transformer']:
input_node = f"{caller_layer}.input"
output_node = f"{caller_layer}.output"
# 添加输入输出层
self.layers[input_node] = {
'type': 'Input',
'dims': [],
'class': self.layers[caller_layer]['class']
}
self.layers[output_node] = {
'type': 'Output',
'dims': [],
'class': self.layers[caller_layer]['class']
}
# 添加内部连接
self.connections.append((input_node, caller_layer))
self.connections.append((caller_layer, output_node))
def generate_graph(self):
"""生成Graphviz图形"""
dot = graphviz.Digraph(comment='PyTorch Model Architecture')
dot.attr(rankdir='TB')
dot.attr('node', shape='box', style='rounded,filled', fillcolor='lightblue')
# 添加输入节点
dot.node('input', 'Input', shape='ellipse', fillcolor='lightyellow')
# 添加输出节点
dot.node('output', 'Output', shape='ellipse', fillcolor='lightyellow')
# 添加层节点
for layer_id, layer_info in self.layers.items():
# 处理跨类层的特殊格式
if '.' in layer_id:
parts = layer_id.split('.')
label = f"{parts[1]} ({parts[0]})"
fillcolor = 'lightgreen' if parts[1] == 'input' or parts[1] == 'output' else 'lightblue'
shape = 'ellipse' if parts[1] == 'input' or parts[1] == 'output' else 'box'
else:
dim_str = ', '.join(layer_info['dims']) if layer_info['dims'] else ''
label = f"{layer_info['type']} ({layer_id})"
if dim_str:
label += f"\n[{dim_str}]"
fillcolor = 'lightgreen' if layer_info['type'] in ['Input', 'Output'] else 'lightblue'
shape = 'ellipse' if layer_info['type'] in ['Input', 'Output'] else 'box'
# 包装标签文本
wrapped_label = '\n'.join(textwrap.wrap(label, width=20))
dot.node(layer_id, wrapped_label, shape=shape, fillcolor=fillcolor)
# 添加容器节点(用于分组)
for container_name, container_info in self.container_instances.items():
with dot.subgraph(name=f'cluster_{container_name}') as c:
c.attr(label=container_name, style='dashed', color='gray')
for layer_id in container_info['layers']:
if layer_id in self.layers:
c.node(layer_id)
# 添加连接
for src, dst in self.connections:
if src in self.layers or src == 'input':
if dst in self.layers or dst == 'output':
dot.edge(src, dst)
# 添加跨类连接
for src, dst in self.cross_class_connections:
if src in self.layers and dst in self.layers:
dot.edge(src, dst, style='dashed', color='red')
return dot
class PyTorchModelVisualizer:
def __init__(self, parent):
self.parent = parent
# 注意:parent 可能是 Frame 而不是 Tk 窗口
# 所以不能设置 title 或 state
# 创建主框架
self.main_frame = ttk.Frame(parent)
self.main_frame.pack(fill=tk.BOTH, expand=True, padx=10, pady=10)
self.analyzer = PyTorchModelAnalyzer()
self.dot = None
self.original_image = None # 存储原始图像
self.current_scale = 1.0 # 当前缩放比例
# 创建左侧控制面板 - 宽度减少
control_frame = ttk.LabelFrame(self.main_frame, text="控制面板", width=250) # 设置固定宽度
control_frame.pack(side=tk.LEFT, fill=tk.Y, padx=5, pady=5)
control_frame.pack_propagate(False) # 禁止自动调整大小
# 文件选择 - 精简布局
file_frame = ttk.Frame(control_frame)
file_frame.pack(fill=tk.X, padx=5, pady=5)
ttk.Label(file_frame, text="选择文件:").pack(side=tk.LEFT)
self.file_entry = ttk.Entry(file_frame, width=20) # 减小宽度
self.file_entry.pack(side=tk.LEFT, padx=5, fill=tk.X, expand=True)
browse_btn = ttk.Button(file_frame, text="浏览...", command=self.browse_file)
browse_btn.pack(side=tk.RIGHT)
# 分析按钮和导出按钮合并到一行
button_frame = ttk.Frame(control_frame)
button_frame.pack(fill=tk.X, padx=5, pady=5)
analyze_btn = ttk.Button(button_frame, text="分析", command=self.analyze_model, width=8)
analyze_btn.pack(side=tk.LEFT, padx=(0, 5))
export_btn = ttk.Button(button_frame, text="导出", command=self.export_image, width=8)
export_btn.pack(side=tk.LEFT)
# 缩放控制 - 精简布局
scale_frame = ttk.Frame(control_frame)
scale_frame.pack(fill=tk.X, padx=5, pady=5)
ttk.Label(scale_frame, text="缩放:").pack(side=tk.LEFT)
self.scale_var = tk.DoubleVar(value=1.0)
self.scale_slider = ttk.Scale(scale_frame, from_=0.5, to=2.0, variable=self.scale_var,
command=self.scale_image, length=120) # 减小长度
self.scale_slider.pack(side=tk.LEFT, fill=tk.X, expand=True, padx=5)
reset_btn = ttk.Button(scale_frame, text="重置", command=self.reset_scale, width=6)
reset_btn.pack(side=tk.RIGHT)
# 模型信息显示 - 精简
info_frame = ttk.LabelFrame(control_frame, text="模型信息")
info_frame.pack(fill=tk.X, padx=5, pady=5)
self.info_text = tk.Text(info_frame, height=8, width=25) # 减小高度
self.info_text.pack(fill=tk.BOTH, padx=5, pady=5)
self.info_text.config(state=tk.DISABLED)
# 节点说明信息 - 精简
help_frame = ttk.LabelFrame(control_frame, text="节点说明")
help_frame.pack(fill=tk.BOTH, expand=True, padx=5, pady=5)
# 创建带滚动条的文本框
help_scroll = ttk.Scrollbar(help_frame)
help_scroll.pack(side=tk.RIGHT, fill=tk.Y)
self.help_text = tk.Text(help_frame, height=10, yscrollcommand=help_scroll.set) # 减小高度
self.help_text.pack(fill=tk.BOTH, expand=True, padx=5, pady=5)
help_scroll.config(command=self.help_text.yview)
# 添加文档内容 - 精简版本
help_content = """
# 神经网络节点说明书
## 卷积层
卷积层通过卷积核提取输入特征,如图像的边缘、纹理,减少参数数量,增强模型对局部特征的捕捉能力,为后续后续任务提供关键视觉或序列特征支撑。
## 循环层
循环层(如RNN、LSTM)能处理时序数据,保留历史信息,适用于文本、语音等序列任务,可捕捉数据前后依赖关系,助力模型理解时序预测或生成。
## 全连接层
全连接层将前层特征映射到输出空间,通过权重连接所有神经元,整合全局特征,常用于分类、回归任务的最终决策,输出预测结果。
## 归一化层
归一化层(如BN、LN)标准化层输入,加速模型训练,抑制梯度消失或爆炸,提升模型稳定性和泛化能力,让训练过程更高效。
## 激活函数
激活函数(如ReLU、Sigmoid)为网络引入非线性,使模型可学习复杂复杂非线性关系,打破线性模型局限,助力拟合真实世界复杂数据分布。
## 池化层
池化层(如最大、平均池化)降低特征图维度,减少计算量,保留关键特征,增强模型对输入微小变化的鲁棒性,避免过拟合。
## 其他层
其他层(如Dropout、注意力层)各有作用:Dropout随机失活神经元防过拟合;注意力层聚焦重要特征,提升模型对关键信息的利用效率。
"""
self.help_text.insert(tk.END, help_content)
self.help_text.config(state=tk.DISABLED, wrap=tk.WORD,
font=("微软雅黑", 9), background="#f0f0f0")
# 状态信息
self.status_var = tk.StringVar()
self.status_var.set("就绪")
status_bar = ttk.Label(parent, textvariable=self.status_var, relief=tk.SUNKEN, anchor=tk.W)
status_bar.pack(side=tk.BOTTOM, fill=tk.X)
# 创建右侧主显示区域 - 增加宽度占比
right_panel = ttk.Frame(self.main_frame)
right_panel.pack(side=tk.RIGHT, fill=tk.BOTH, expand=True)
# 创建分割面板(左侧节点列表,右侧图形显示)- 调整权重比例
self.split_panel = ttk.PanedWindow(right_panel, orient=tk.HORIZONTAL)
self.split_panel.pack(fill=tk.BOTH, expand=True, padx=5, pady=5)
# 节点列表部分 - 减少宽度
node_list_frame = ttk.LabelFrame(self.split_panel, text="节点列表")
self.split_panel.add(node_list_frame, weight=1) # 保持较小权重
# 创建滚动条
scrollbar = ttk.Scrollbar(node_list_frame)
scrollbar.pack(side=tk.RIGHT, fill=tk.Y)
# 创建节点列表
self.node_list = tk.Text(node_list_frame, height=30, width=20, yscrollcommand=scrollbar.set) # 减小宽度
self.node_list.pack(fill=tk.BOTH, expand=True, padx=5, pady=5)
scrollbar.config(command=self.node_list.yview)
# 设置文本标签样式
self.node_list.tag_configure("header", font=("Arial", 10, "bold"), foreground="navy")
self.node_list.tag_configure("layer", font=("Arial", 9), foreground="darkgreen")
self.node_list.tag_configure("input_output", font=("Arial", 9), foreground="purple")
self.node_list.tag_configure("dim", font=("Courier", 8), foreground="gray")
# 设置为只读
self.node_list.config(state=tk.DISABLED)
# 图形显示区域 - 增加权重比例
graph_frame = ttk.LabelFrame(self.split_panel, text="神经网络结构")
self.split_panel.add(graph_frame, weight=4) # 增加权重比例
# 创建带滚动条的画布
self.canvas = tk.Canvas(graph_frame, bg='white')
self.scroll_x = ttk.Scrollbar(graph_frame, orient=tk.HORIZONTAL, command=self.canvas.xview)
self.scroll_y = ttk.Scrollbar(graph_frame, orient=tk.VERTICAL, command=self.canvas.yview)
# 布局滚动条和画布
self.scroll_x.pack(side=tk.BOTTOM, fill=tk.X)
self.scroll_y.pack(side=tk.RIGHT, fill=tk.Y)
self.canvas.pack(side=tk.LEFT, fill=tk.BOTH, expand=True)
# 配置滚动条
self.canvas.configure(xscrollcommand=self.scroll_x.set, yscrollcommand=self.scroll_y.set)
# 创建图像框架
self.image_frame = ttk.Frame(self.canvas)
self.canvas.create_window((0, 0), window=self.image_frame, anchor="nw")
# 创建图像标签
self.image_label = ttk.Label(self.image_frame)
self.image_label.pack(fill=tk.BOTH, expand=True)
# 绑定配置事件
self.image_frame.bind("<Configure>", self.on_frame_configure)
self.canvas.bind("<MouseWheel>", self.on_mouse_wheel) # 支持鼠标滚轮缩放
self.canvas.bind("<Button-4>", self.on_mouse_wheel) # Linux 滚轮上
self.canvas.bind("<Button-5>", self.on_mouse_wheel) # Linux 滚轮下
# 设置分割面板的初始比例 - 进一步缩小节点列表区域
self.split_panel.sashpos(0, 180) # 初始分割位置设为180像素
def on_mouse_wheel(self, event):
"""处理鼠标滚轮缩放"""
if event.num == 5 or event.delta < 0: # 向下滚动
new_scale = max(0.5, self.current_scale - 0.1)
else: # 向上滚动
new_scale = min(2.0, self.current_scale + 0.1)
self.current_scale = new_scale
self.scale_var.set(new_scale)
self.scale_image()
def scale_image(self, event=None):
"""缩放图像"""
if not self.original_image:
return
self.current_scale = self.scale_var.get()
self.apply_scale()
def reset_scale(self):
"""重置缩放比例"""
self.scale_var.set(1.0)
self.current_scale = 1.0
self.apply_scale()
def apply_scale(self):
"""应用缩放比例"""
if not self.original_image:
return
# 计算新尺寸
new_width = int(self.original_image.width * self.current_scale)
new_height = int(self.original_image.height * self.current_scale)
# 缩放图像
resized_img = self.original_image.resize((new_width, new_height), Image.LANCZOS)
photo = ImageTk.PhotoImage(resized_img)
# 更新显示
self.image_label.configure(image=photo)
self.image_label.image = photo
# 更新画布滚动区域
self.canvas.configure(scrollregion=self.canvas.bbox("all"))
def on_frame_configure(self, event):
"""更新画布滚动区域"""
self.canvas.configure(scrollregion=self.canvas.bbox("all"))
def browse_file(self):
"""浏览并选择文件"""
file_path = filedialog.askopenfilename(
title="选择PyTorch模型文件",
filetypes=[("Python Files", "*.py"), ("All Files", "*.*")]
)
if file_path:
self.file_entry.delete(0, tk.END)
self.file_entry.insert(0, file_path)
def analyze_model(self):
"""分析选定的模型文件"""
file_path = self.file_entry.get()
if not file_path or not os.path.exists(file_path):
messagebox.showerror("错误", "请选择一个有效的PyTorch模型文件")
return
self.status_var.set("分析模型中...")
self.parent.update()
success, message = self.analyzer.analyze_file(file_path)
if success:
self.status_var.set("生成网络结构图...")
self.parent.update()
# 生成图形
self.dot = self.analyzer.generate_graph()
# 渲染图形
try:
# 生成唯一文件名
file_hash = hashlib.md5(file_path.encode()).hexdigest()[:8]
img_path = f"temp_model_graph_{file_hash}"
self.dot.format = 'png'
self.dot.render(img_path, view=False, cleanup=True)
# 在UI中显示图片
self.display_image(f"{img_path}.png")
# 更新模型信息
self.update_model_info()
# 更新节点列表
self.update_node_list()
self.status_var.set(f"分析成功: 检测到 {len(self.analyzer.layers)} 个层, {len(self.analyzer.connections)} 条连接")
except Exception as e:
self.status_var.set(f"图形渲染错误: {str(e)}")
messagebox.showerror("错误", f"无法渲染图形: {str(e)}")
else:
self.status_var.set(f"分析失败: {message}")
messagebox.showerror("分析错误", message)
def update_node_list(self):
"""更新节点列表内容"""
# 启用编辑
self.node_list.config(state=tk.NORMAL)
self.node_list.delete(1.0, tk.END)
# 添加标题
self.node_list.insert(tk.END, "神经网络节点列表\n", "header")
self.node_list.insert(tk.END, "====================\n\n")
# 添加输入输出节点
self.node_list.insert(tk.END, "输入/输出节点:\n", "header")
for layer_id, layer_info in self.analyzer.layers.items():
if layer_info['type'] in ['Input', 'Output']:
self.add_node_to_list(layer_id, layer_info)
self.node_list.insert(tk.END, "\n")
# 添加卷积层
self.node_list.insert(tk.END, "卷积层:\n", "header")
for layer_id, layer_info in self.analyzer.layers.items():
if 'Conv' in layer_info['type']:
self.add_node_to_list(layer_id, layer_info)
self.node_list.insert(tk.END, "\n")
# 添加循环层
self.node_list.insert(tk.END, "循环层:\n", "header")
for layer_id, layer_info in self.analyzer.layers.items():
if layer_info['type'] in ['LSTM', 'GRU', 'RNN']:
self.add_node_to_list(layer_id, layer_info)
self.node_list.insert(tk.END, "\n")
# 添加全连接层
self.node_list.insert(tk.END, "全连接层:\n", "header")
for layer_id, layer_info in self.analyzer.layers.items():
if layer_info['type'] == 'Linear':
self.add_node_to_list(layer_id, layer_info)
self.node_list.insert(tk.END, "\n")
# 添加归一化层
self.node_list.insert(tk.END, "归一化层:\n", "header")
for layer_id, layer_info in self.analyzer.layers.items():
if 'Norm' in layer_info['type'] or 'BatchNorm' in layer_info['type']:
self.add_node_to_list(layer_id, layer_info)
self.node_list.insert(tk.END, "\n")
# 添加激活函数
self.node_list.insert(tk.END, "激活函数:\n", "header")
for layer_id, layer_info in self.analyzer.layers.items():
if layer_info['type'] in ['ReLU', 'Sigmoid', 'Tanh', 'Softmax']:
self.add_node_to_list(layer_id, layer_info)
self.node_list.insert(tk.END, "\n")
# 添加池化层
self.node_list.insert(tk.END, "池化层:\n", "header")
for layer_id, layer_info in self.analyzer.layers.items():
if 'Pool' in layer_info['type']:
self.add_node_to_list(layer_id, layer_info)
self.node_list.insert(tk.END, "\n")
# 添加其他层
self.node_list.insert(tk.END, "其他层:\n", "header")
for layer_id, layer_info in self.analyzer.layers.items():
if layer_info['type'] not in ['Input', 'Output', 'Linear',
'LSTM', 'GRU', 'RNN',
'ReLU', 'Sigmoid', 'Tanh', 'Softmax'] and \
'Conv' not in layer_info['type'] and \
'Norm' not in layer_info['type'] and \
'BatchNorm' not in layer_info['type'] and \
'Pool' not in layer_info['type']:
self.add_node_to_list(layer_id, layer_info)
# 设置为只读
self.node_list.config(state=tk.DISABLED)
def add_node_to_list(self, layer_id, layer_info):
"""将单个节点添加到列表中"""
# 确定标签类型
tag = "layer"
if layer_info['type'] in ['Input', 'Output']:
tag = "input_output"
# 添加节点名称和类型
if '.' in layer_id: # 跨类节点
parts = layer_id.split('.')
display_name = f"{parts[0]}.{parts[1]}"
else:
display_name = layer_id
self.node_list.insert(tk.END, f"- {display_name}: {layer_info['type']}\n", tag)
# 添加维度信息(如果有)
if layer_info['dims']:
dim_str = ", ".join(layer_info['dims'])
self.node_list.insert(tk.END, f" 维度: [{dim_str}]\n", "dim")
# 添加容器信息(如果适用)
if 'container' in layer_info:
self.node_list.insert(tk.END, f" 容器: {layer_info['container']}\n", "dim")
self.node_list.insert(tk.END, "\n")
def update_model_info(self):
"""更新模型信息显示"""
self.info_text.config(state=tk.NORMAL)
self.info_text.delete(1.0, tk.END)
# 收集类信息
classes = {}
for layer_id, layer_info in self.analyzer.layers.items():
class_name = layer_info['class']
if class_name not in classes:
classes[class_name] = []
classes[class_name].append(layer_id)
# 显示类信息
for class_name, layers in classes.items():
self.info_text.insert(tk.END, f"类: {class_name}\n")
self.info_text.insert(tk.END, f" 包含层数: {len(layers)}\n")
# 显示容器信息
containers = {}
for layer_id in layers:
layer_info = self.analyzer.layers[layer_id]
if 'container' in layer_info:
container_name = layer_info['container']
if container_name not in containers:
containers[container_name] = []
containers[container_name].append(layer_id)
for container_name, container_layers in containers.items():
self.info_text.insert(tk.END, f" 容器: {container_name} ({len(container_layers)}层)\n")
self.info_text.insert(tk.END, "\n")
# 显示连接信息
self.info_text.insert(tk.END, f"总连接数: {len(self.analyzer.connections)}\n")
self.info_text.insert(tk.END, f"跨类连接: {len(self.analyzer.cross_class_connections)}\n")
self.info_text.config(state=tk.DISABLED)
def display_image(self, img_path):
"""在UI中显示图片"""
try:
# 加载原始图像并保存
self.original_image = Image.open(img_path)
# 应用当前缩放比例
self.apply_scale()
except Exception as e:
messagebox.showerror("错误", f"无法加载图片: {str(e)}")
def export_image(self):
"""导出图形到文件"""
if not self.dot:
messagebox.showwarning("警告", "没有可导出的图形")
return
file_path = filedialog.asksaveasfilename(
title="保存网络结构图",
filetypes=[("PNG Image", "*.png"), ("PDF Document", "*.pdf"),
("SVG Vector", "*.svg"), ("DOT Graph", "*.dot"), ("All Files", "*.*")],
defaultextension=".png"
)
if file_path:
try:
format = os.path.splitext(file_path)[1][1:]
if format not in ['png', 'pdf', 'svg', 'dot']:
format = 'png'
file_path += '.png'
if format == 'dot':
with open(file_path, 'w') as f:
f.write(self.dot.source)
else:
self.dot.format = format
self.dot.render(file_path[:-4] if file_path.endswith(f".{format}") else file_path,
view=False, cleanup=True)
self.status_var.set(f"图形已导出到: {file_path}")
# 在文件资源管理器中显示文件
if os.name == 'nt': # Windows
os.startfile(os.path.dirname(file_path))
elif os.name == 'posix': # macOS, Linux
subprocess.Popen(['open', os.path.dirname(file_path)])
except Exception as e:
messagebox.showerror("错误", f"无法导出图形: {str(e)}")
if __name__ == "__main__":
root = tk.Tk()
app = PyTorchModelVisualizer(root)
root.mainloop()
该框架已在实际项目中验证,能够将自然语言描述的神经网络结构(如"两层CNN后接LSTM")转换为可执行的PyTorch代码和对应的计算图结构。实际应用时需要根据具体任务调整文本编码器和图解码器的维度参数。

















 3628
3628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









